Milline täht on kõige levinum. Venekeelsete tähtede kasutamise sagedus
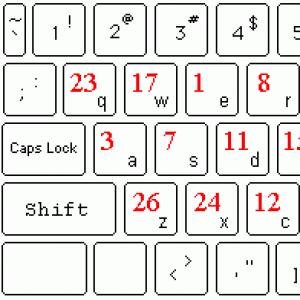
Vaadake klaviatuuri klahve "F" ja "J" ja näete väikseid konkse. See on meie juhend puutega tippimise maailma.
Puutega tippimist õppima asudes tekkis tunne, et meie küljenduses on midagi valesti. See oli venekeelsete tähtede esinemissageduse ja nende asukoha klaviatuuril mittevastavus.
Mis on teie arvates kõige levinum kiri vene keeles? Ja kui sa oleksid "Imede väljal", siis millise tähe nimetaksite kõigepealt? Kõige tavalisem täht on "O" ja kõige vähem levinud on "F". Pole ühtegi venekeelset sõna, mis algaks tähega "F".
Siin on tabel venekeelsete tekstide tähtede tõenäosusjaotuse kohta:
|
Tõenäosus |
Tõenäosus |
Tõenäosus |
Tõenäosus |
||||
Täht "F" esineb 45 korda vähem kui "O" ja on samas mugavas kohas kui "O". Kes oli see, kes selle standardi aktsepteeris? Sellele küsimusele leiate vastuse artiklist Koma tragöödia: "... arvan, et koma on palju levinum kui punkt, kuid vahepeal on koma suurtähtedega. Seda ei ole üheski koma keeles. maailm, välja arvatud vene keel ...".
Tabeliga tutvudes võis näha järgmist: pimesi tippimiseks ei saa teada mitte kõigi tähtede asukohta, vaid ainult näiteks 20 – neid esineb üle 90% juhtudest. Ma ei usu, et sageli trükkiv inimene ei suudaks võtmete asukohta meelde jätta ja ilma neid vaatamata töötada. See kõik on seotud harjumusega. Pange tähele: igas teenuses, kus paberitööd töödeldakse, vaatavad operaatorid klaviatuuri, kuigi nad tippivad väga kiiresti.
Aga ma taipasin paigutust koostades tõenäosust võeti arvesse. Ainult ta oli mõeldud neile ... kes prindib otsimise ajal klaviatuuril!!!
Lihtne on märgata, et kõik enim kohatud tähed asuvad otsenähtavuse väljas ja vähemlevinud perifeerias.
Ingliskeelse paigutusega on asjad veidi halvemad:

puutetundliku tippimise programmid. Neid on palju, arvustusi saab vaadata http://www.urikor.net. Valisin Solo ja Stamina. Otsustasin alustada Sologa. See osutus tasuliseks, kuid demo oli olemas. Et täita 1! tippimise harjutus vaja 2 tähemärki lugeda rohkem kui 10 lehekülge - omamoodi "simulaator" kiirlugemiseks.
Ja siis ei lase nad teid läbi enne, kui olete kõik läbi lugenud ja standardile vastanud. Olin peaaegu programmi desinstallimas, kui sain Solo saidilt meili, kus nad olid huvitatud minu edusammudest. Kiri oli pikk ja ma mõtlesin: "Hästi tehtud, nad õppisid kiiresti tippima ja kõigile suuri tähti kirjutama."
Kuid pärast kirja tähelepanelikku uurimist sain aru, et selle koostas robot-automaatvastaja, kuigi sellele oli alla kirjutanud inimene. Nüüd saan aru, miks minult ankeedis nii palju minu huvide ja juuksevärvi kohta küsiti. Kustutasin Solo.
Ise töötasin Stamina programmiga. See on tehtud hingega! Saate isegi mitte programmiga tegeleda, vaid ühe viite huvides alla laadida. See on kõigi aegade naljakaim tsitaat!
Kuidas võtmeid meelde jätta?"fiwa" ja "oldzh" õpid kiiresti. Iga sõrm tähega. Kokku juba 8! Ma õpetasin neid mitte Stamina, vaid saidi http://www.urikor.net programmis. Ja siis jätsin liigutused ise pähe. Näiteks puutega tippimise õppimisel on paljudel raskusi tähega "ja". Olles asetanud sõrmed "fiwa" ja "oldzh" peale, pean klahvi "ja" vajutamiseks tegema parema nimetissõrme täispöörde.
Sellise pöördega saan vajutada vaid "ja" klahvi. Iga sõrme puhul jätsin meelde järgmised liigutused: "p" - vasak indeks vasakule, "k" - üles, "e" - üles ja paremale jne.
Probleemid: kuna paigutus pole puutega tippimiseks optimeeritud, siis selgub, et sarnased tähed peegelduvad üksteisele, need on klahvid "a" ja "o", "k" ja "r". Ja mis veelgi huvitavam: tehakse nimetissõrmede harjutusi üheaegselt!, st. õppida korraga "a" ja "o", "e" ja "n", "p" ja "r".
Minu arvates see vale - ajus on segadus. Vähemalt olen vahel segaduses. Kui õpid puutega tippimist, mõtle liigutuste peale – siis on raske ümber õppida. Muide, klaviatuuriga töötamisega on mõnel naisel probleem, pikkade küünte tõttu vajutatakse teisi klahve.
Ja kui ma kõik selgeks sain ja otsustasin, et kirjutan pimesi, tuli järgmine etapp - "laiskus". Iga päev tuli palju trükkida ja kuna piilumisega on kiirus kiirem, siis piilusin koguaeg. Paari kuu pärast alistasin ennast ja liimitud kõik võtmed kleebistega videokassettidest.
Tähelepanu: kui sa ei pitseeri võtmeid, siis harjumus võidab sind. Kui töötan klaviatuuridel, kus tähed on nähtavad, tekib kiusatus piiluda. Nüüd pole enam tagasiteed ja see on esimene täiesti pimesi kirjutatud artikkel.
Miks ma seda vajan. Siiani olen sügavalt rahul. Kiirus on ikka veidi väiksem kui piilumisel ja ikka esineb vigu, aga juba seda artiklit kirjutades märkasin, kuidas kiirus kasvab ja vahel ununeb ja siis vaatan - trükitud on. Justkui teadvus eemaldaks plokid.
Huvitav on jälgida, kuidas sa ise õpid, sest sellist kogemust enam ei tule. Nüüd kavatsen õppida klaverit mängima. Ma isegi arvan, et ma tean, kuidas mängida (!), peate lihtsalt meeles pidama.
P.S.
Aasta on möödas. Kirjutan ainult pimesi ja suurel kiirusel. Kui töötate arvutiga, õppige kindlasti pimesi tippima. See on lihtsam kui arvate.
Siin on Inna Igolkina väike märkus selle kohta, kuidas ta õppis pimesi trükkima.
Kas teate, et mõnda tähestiku tähte leidub sõnades sagedamini kui teisi ... Pealegi on vokaalide sagedus keeles suurem kui kaashäälikutel.
Millised vene tähestiku tähed on teksti kirjutamiseks kasutatavates sõnades enim või kõige vähem levinud?
Statistika tegeleb üldiste mustrite tuvastamise ja uurimisega. Selle teadusliku suuna abil saab ülaltoodud küsimusele vastata, loendades vene tähestiku iga tähe arvu, kasutatud sõnu, valides väljavõtte erinevate autorite töödest. Oma huvides ja igavuse huvides saab igaüks ise hakkama. Viitan juba läbiviidud uuringu statistikale ...

Vene tähestik on kirillitsas. Oma eksisteerimise jooksul on see läbi teinud mitmeid reforme, mille tulemusena kujunes välja tänapäevane vene tähestikusüsteem, mis sisaldab 33 tähte.

o - 9,28%
a - 8,66%
e - 8,10%
ja – 7,45%
n – 6,35%
t - 6,30%
p - 5,53%
c – 5,45%
l - 4,32%
c – 4,19%
k - 3,47%
n – 3,35%
m - 3,29%
a – 2,90%
e - 2,56%
I - 2,22%
s – 2,11%
b – 1,90%
h - 1,81%
b – 1,51%
d – 1,41%
th - 1,31%
h - 1,27%
jü - 1,03%
x – 0,92%
g – 0,78%
kaal - 0,77%
c – 0,52%
u – 0,49%
f – 0,40%
e - 0,17%
b – 0,04%
Kõige sagedamini kasutatav vene täht on täishäälik " KOHTA', nagu siin on õigustatult soovitatud. On ka iseloomulikke näiteid, nagu " KAITSEVÕIME"(7 tükki ühesõnaga ja ei midagi eksootilist ega üllatavat; vene keelele väga tuttav). Tähe "O" suur populaarsus on suuresti tingitud sellisest grammatilisest nähtusest nagu täisvokaal. See tähendab, et "külm" asemel "külm" ja "saht" asemel "külm".
Ja sõnade alguses kaashääliku täht " P". Ka see juhtimine on enesekindel ja tingimusteta. Tõenäoliselt annab selgitus suure hulga eesliiteid tähega “P”: re-, pre-, pre-, pre-, pro- ja teised.
Tähesagedus on krüptoanalüüsi aluseks.
Kirjutas naljaka php-skripti. Sõitsin sealt läbi kõik Spectatori tekstid keele jaoks. Kokku on tekstides kasutatud 39110 erinevat sõnavormi. Kui palju erinevaid sõnad- on raske määratleda. Et sellele joonisele kuidagi lähemale jõuda, võtsin ainult sõna esimesed 5 tähte ja võrdlesin neid. Selgus 14373 sellist kombinatsiooni. Suure venitusega võib seda nimetada "Pealtvaataja" sõnavaraks.
Seejärel võtsin sõnad kätte ja uurisin nende tähtede sagedust. Ideaalis peaksite täielikkuse huvides võtma mingi sõnaraamatu. Tekste on võimatu minema ajada, vaja on ainult unikaalseid sõnu. Tekstis korratakse mõnda sõna sagedamini kui teisi. Niisiis, saime järgmised tulemused:
o - 9,28%
a - 8,66%
e - 8,10%
ja – 7,45%
n – 6,35%
t - 6,30%
p - 5,53%
c – 5,45%
l - 4,32%
c – 4,19%
k - 3,47%
n – 3,35%
m - 3,29%
a – 2,90%
e - 2,56%
i - 2,22%
s – 2,11%
b – 1,90%
h - 1,81%
b – 1,51%
g – 1,41%
th - 1,31%
h - 1,27%
jü - 1,03%
x – 0,92%
kaal - 0,78%
kaal - 0,77%
c – 0,52%
u – 0,49%
f – 0,40%
e - 0,17%
b – 0,04%
Neil, kes lähevad "Imede väljale", soovitan teil see tabel pähe õppida. Ja nimetage sõnu selles järjekorras. Näiteks näib, et sellist "tavalist" tähte "b" kasutatakse harvemini kui "haruldast" tähte "s". Samuti on vaja meeles pidada, et sõnas pole ainult täishäälikuid. Ja et kui arvasite ära ühe vokaali, peate hakkama mööda kaashäälikuid kõndima. Ja pealegi arvatakse sõna täpselt kaashäälikute järgi. Võrdle: "** a** ja * e" ja "cf * vn * t *". Mõlemal juhul on see sõna "võrdle".
Ja veel üks kaalutlus. Kuidas sa inglise keelt õppisid? Mäletad? E pliiats, e pliiats, e laud. Mida ma näen, sellest ma laulan. Ja tähendus? .. Kui sageli ütlete tavaelus sõna "pliiats"? Kui ülesanne on õpetada rääkima võimalikult kiiresti ja tõhusalt, siis on vaja ka vastavalt õpetada. Analüüsime keelt, toome välja enamkasutatavad sõnad. Ja me hakkame neilt õppima. Et enam-vähem inglise keelt rääkida, piisab vaid poolteise tuhandest sõnast.
Veel üks jant: teha tähtedest sõnu suvaliselt, kuid arvestades esinemissagedust, et see näeks välja nagu tavalised sõnad. Esimese kümne "juhusliku" neljatähelise sõna hulgas hüppas välja "eesel". Järgmises viiekümnes - sõnad "tormamine" ja "NATO". Kuid paraku on palju dissonantseid kombinatsioone, nagu "bltt" või "nrro".
Seetõttu järgmine samm. Jagasin kõik sõnad kahetähelisteks kombinatsioonideks ja hakkasin neid juhuslikult (aga arvestades kordussagedust) kombineerima. Teras suurtes kogustes põhjustab sõnadega "tavaline" sarnaseid sõnu. Näiteks: "koivdiot", "voabma", "apy", "depoid", "debyako", "orfa", "poesnavy", "ozza", "chenya", "retoorika", "urdeed", "utoichi" , "Stykh", "saapad", "gravda", "ababap", "obarto", "eluet", "larezy", "myni", "bromomer" ja isegi "todebyst".
Kuhu taotleda ... valikuid on. Näiteks kirjutage ilusate korporatiivsete mänguliste nimede generaator. Jogurtide jaoks. Nagu "memoliso" või "utororerto". Või - futuristlike värsside generaator "Burliuk-php": "opeldiy miaton, linoaz okmiaya ... deesopen odeson."
Ja on veel üks võimalus. Vaja proovida...
Mõned statistikad vene sõnade kasutamise kohta:
- Sõna keskmine pikkus on 5,28 tähemärki.
- Keskmine lause pikkus on 10,38 sõna.
- 1000 sagedasemat lemmat katavad 64,0708% tekstist.
- 2000 sagedasemad lemmad hõlmavad 71,9521% tekstist.
- 3000 sagedasemat lemmat katavad 76,5104% tekstist.
- 5000 sagedasemat lemmat katavad 82,0604% tekstist.
Pärast postitamist sain järgmise meili:
Tere Dmitri!Pärast artikli „Keel toob teid Kiievisse” ja selle osa analüüsimist, kus kirjeldate oma programmi, tekkis idee.
Sinu kirjutatud stsenaarium tundub mulle mõeldud absoluutselt mitte suuremal määral “Imede väljale”, vaid millekski muuks.
Esimene kõige mõistlikum skripti tulemuste kasutamine on mobiilseadmete nuppude programmeerimisel tähtede järjekorra määramine. Jah, jah - seda kõike on vaja mobiiltelefonides.Ma jaotasin selle lainetena ()
Edasine jaotus nuppude järgi:
1. Kõik esimese laine tähed lähevad 4 nuppu esimesse ritta
2. Kõik teise laine tähed on ka ülejäänud 4 nupul samas esimeses reas
3. Kõik kolmanda laine tähed lähevad sinna ülejäänud kahele nupule
4. Teisele reale lähevad 4,5 ja 6 lainet
5. 7,8,9 lainet lähevad kolmandale reale ja 9. laine läheb täielikult (vaatamata näilisele suurele tähtede arvule) 9. nupu kolmandale reale, nii et 10. nupp jääb igasuguste kirjavahemärkide alla. märgid (punkt, koma jne).Ma arvan, et kõik on selge ja nii, ilma üksikasjalike selgitusteta. Kuid siiski, kas saaksite oma skriptiga (sh kirjavahemärkidega) töödelda järgmise sisu tekste:
Ja siis statistika välja panna? Mulle tundus? et tekstid peegeldaksid võimalikult palju meie tänapäevast kõnet ja me nii räägime kui kirjutame sms-i.
Tänan teid juba ette.
Niisiis on tähtede kordumise sageduse analüüsimiseks kaks võimalust. Meetod 1. Võtke tekst, leidke sellest ainulaadsed (mittekorduvad) sõnavormid ja analüüsige neid. Meetod sobib hästi vene keele sõnade, mitte tekstide statistika koostamiseks. Meetod 2. Ärge otsige tekstist ainulaadseid sõnu, vaid minge otse tähtede kordumise sageduse loendamiseni. Me saame tähtede sageduse venekeelses tekstis, mitte venekeelsetes sõnades. Klaviatuuride ja muude asjade loomiseks peate kasutama seda konkreetset meetodit: klaviatuuril sisestatakse tekste.
Klaviatuurid peaksid arvestama mitte ainult tähtede sagedusega, vaid ka kõige levinumate sõnadega (sõnavormidega). Pole nii raske ära arvata, milliseid sõnu kõige sagedamini kasutatakse: need on esiteks ametnik kõneosad, sest nende roll on teenida alati ja kõikjal, ja asesõnad, mille roll pole vähem oluline: asendada kõnes mis tahes asja / inimest (see, ta, ta). Noh, peamised tegusõnad (olema, ütlema). Ülalloetletud tekstide analüüsi tulemuste põhjal sain kõige “populaarsemad” sõnad: “and, not, in, what, he, I, on, with, she, like, but, him, this, to , aga, kõik, tema, oli, nii, siis, ütles, for, sina, oh, u, tema, mina, ainult, for, mina, oleks, jah, sina, alates, oli, millal, alates, eest, ikka , nüüd, nad, ütlesid, juba, tema, ei, oli, ta, ole, noh, mitte, kui, väga, mitte midagi, siin, iseendale, endale, sellele, võib-olla sellele, enne, meie, nemad, kas, olid, on, kui või, tema” ja nii edasi.
Klaviatuuride juurde tagasi tulles on ilmne, et klaviatuuris peaksid tähekombinatsioonid “mitte”, “mida”, “tema”, “sees” ja teised olema üksteisele võimalikult lähedal või kui mitte lähedal, siis mõnes kõige optimaalsemal viisil. Tuleb läbi viia uuring, kuidas täpselt sõrmed klaviatuuril liiguvad, leida kõige “mugavamad” asendid ja paigutada neisse enamkasutatavad tähed, unustamata siiski tähekombinatsioone.
Probleem, nagu alati, on sama: isegi kui teil õnnestub luua kordumatu klaviatuur, mida teha miljonite inimestega, kes on juba qwerty / yutsukeniga harjunud?
Mis puudutab mobiilseadmeid... Ilmselt on see mõistlik. Vähemalt peavad tähed "o", "a", "e" ja "ja" olema täpselt samal klahvil. Kirjavahemärgid kasutussageduse järjekorras: , . - ? ! "; :)(
Venekeelsete tähtede kasutamise sagedusKas teate, et mõnda tähestiku tähte leidub sõnades sagedamini kui teisi ... Pealegi on vokaalide sagedus keeles suurem kui kaashäälikutel.
Millised vene tähestiku tähed on teksti kirjutamiseks kasutatavates sõnades enim või kõige vähem levinud?
Statistika tegeleb üldiste mustrite tuvastamise ja uurimisega. Selle teadusliku suuna abil saab ülaltoodud küsimusele vastata, loendades vene tähestiku iga tähe arvu, kasutatud sõnu, valides väljavõtte erinevate autorite töödest. Oma huvides ja igavuse huvides saab igaüks ise hakkama. Viitan juba läbiviidud uuringu statistikale ...
Vene tähestik on kirillitsas. Oma eksisteerimise jooksul on see läbi teinud mitmeid reforme, mille tulemusena kujunes välja tänapäevane vene tähestikusüsteem, mis sisaldab 33 tähte.
o - 9,28%
a - 8,66%
e - 8,10%
ja – 7,45%
n – 6,35%
t - 6,30%
p - 5,53%
c – 5,45%
l - 4,32%
c – 4,19%
k - 3,47%
n – 3,35%
m - 3,29%
a – 2,90%
e - 2,56%
I - 2,22%
s – 2,11%
b – 1,90%
h - 1,81%
b – 1,51%
d – 1,41%
th - 1,31%
h - 1,27%
jü - 1,03%
x – 0,92%
g – 0,78%
kaal - 0,77%
c – 0,52%
u – 0,49%
f – 0,40%
e - 0,17%
b – 0,04%
Kõige sagedamini kasutatav vene täht on täishäälik " KOHTA', nagu siin on õigustatult soovitatud. On ka iseloomulikke näiteid, nagu " KAITSEVÕIME"(7 tükki ühesõnaga ja ei midagi eksootilist ega üllatavat; vene keelele väga tuttav). Tähe "O" suur populaarsus on suuresti tingitud sellisest grammatilisest nähtusest nagu täisvokaal. See tähendab, et "külm" asemel "külm" ja "saht" asemel "külm".
Ja sõnade alguses kaashääliku täht " P". Ka see juhtimine on enesekindel ja tingimusteta. Tõenäoliselt annab selgitus suure hulga eesliiteid tähega “P”: re-, pre-, pre-, pre-, pro- ja teised.
Tähesagedus on krüptoanalüüsi aluseks.
Teatavasti pole trükimasina või arvuti klaviatuuri tähepaigutus juhuslikult koostatud, vaid järgib teatud reegleid. Niisiis asuvad kõige sagedamini kasutatavad tähed klaviatuuri keskosas ja need, mis on vähem levinud, asuvad servades. Samuti on teada, et täishäälikuid kasutatakse sagedamini kui kaashäälikuid. See teave saadi spetsiaalse valemi abil Vene keele riiklikus korpuses.
Enim kasutatud vokaalid
Kummalisel kombel on täht "o" kirjalikus kõnes kasutuste arvu liider nii vokaalide kui ka kaashäälikute seas. Sellele järgneb "a" ja "ja" ning pärast seda algavad kaashäälikud. Ekspertide hinnangul on tähe "o" kasutamise sagedus üks kümnendik protsenti, teiste vokaalide sagedus jääb vahemikku seitse kuni kaheksa sajandikku protsenti.
Kõige populaarsemad kaashäälikud
Kõige sagedamini kasutatav kaashäälik on "n". Samal ajal algab vene keeles kõige rohkem sõnu tähega "p". Täishäälikute hulgas on sel alusel eesotsas "o".
Kõige haruldasem kaashäälik vene keele kõnes on täht “f”, mida kasutatakse võõrkeeltest pärit sõnades, aga ka onomatopoeesias, näiteks “norksu”.
Selline statistika võib olla kasulik tautogrammide koostamisel. Selle sõnamängu põhiolemus on luua ühtne lugu, mille iga sõna peab algama sama tähega.