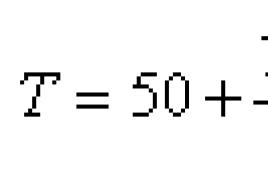Grafika 90 ticamības intervāls. Vispārīgās populācijas matemātiskās cerības ticamības intervāla konstruēšana
Intervālu novērtēšanas piemērs ir ticamības intervāls. Ticamības intervāls ir segments, kura centrs ir skaitliskā raksturlieluma punktveida novērtējums, ieskaitot šī skaitliskā raksturlieluma patieso vērtību ar noteiktu varbūtību. Šo varbūtību sauc ticamības varbūtība. Tādējādi ticamības intervāls ir aplēses precizitātes mērs, un ticamības varbūtība raksturo tā ticamību. Uzticamības intervāla lielums ir atkarīgs no tā, kādu ticamības varbūtības vērtību ir norādījis eksperimentētājs. Jo augstāks ticamības līmenis, jo plašākam ir jābūt intervālam, lai ar noteiktu varbūtību iekļautu skaitliskā raksturlieluma patieso vērtību. Bieži tiek izvēlēta ticamības vērtība P d = 0,95, tādējādi uzskatot, ka šī vērtība ir pietiekami liela, lai uzskatītu, ka ticamības intervāls “gandrīz vienmēr” aptver patieso vērtību. Tikai dažkārt atbildīgu un ļoti atbildīgu pētījumu gadījumā tiek pieņemts attiecīgi P d = 0,99 un 0,999.
Uzticamības intervāla konstruēšanas procedūra ietver divus posmus:
Varbūtības paziņojuma ieraksts par kādu nejaušu funkciju, kas ietver aplēses un skaitliskā raksturlieluma starpību vai attiecību. Šāda funkcija nes informāciju par minēto vērtību tuvuma pakāpi. Ir nepieciešams, lai būtu zināms funkcijas sadalījuma likums;
Varbūtības apgalvojums tiek pārveidots formā, kurā skaitliskā raksturlieluma ticamības intervāla robežas tiek uzrādītas skaidri izteiktā formā.
Funkciju piemēri ar zināmu sadalījumu, kas atbilst nepieciešamajām prasībām, ir šādi:
ar normālu sadalījumu, ja X vērtība ir normāli sadalīta un ir zināma s[X] vērtība;
2)  (3.25)
(3.25)
ar Stjudenta sadalījumu c m = N-1, ja X vērtība ir normāli sadalīta un s[X] vērtība iepriekš nav zināma, bet tās novērtējumu var iegūt no eksperimentāliem datiem, izmantojot formulu (3.23);
3)  (3.26)
(3.26)
ar Pīrsona sadalījumu ar m = N-1, ja X vērtība ir sadalīta normāli.
Atgādinām, ka sadalījuma parametri m ir brīvības pakāpju skaitļi. Turklāt šeit tiek izmantoti šādi apzīmējumi: - vidējā aritmētiskā vērtība, - vidējā kvadrātiskā vērtība, kas vienāda ar dispersijas kvadrātsakni, [X] - vidējās kadra vērtības aplēse, kas definēta kā kvadrātsakne no dispersijas objektīva novērtējuma, N - izlases lielums.
Funkcijas Z un t var izmantot, lai izveidotu ticamības intervālu vidējai vērtībai, savukārt funkcija c 2 konstruē dispersijas ticamības intervālu.
Izveidosim ticamības intervālu matemātiskajai cerībai, ja mūsu rīcībā ir normāli sadalīta lieluma X novērojumu N rezultāti un vidējā kvadrātiskā vērtība ir iepriekš zināma no neatkarīgiem novērojumiem. Tā kā funkcija Z ir parasti sadalīta, varat izmantot atbilstošo tabulu, lai noteiktu z a vērtību tā, ka ārpus - z a un + z a ir daļa no laukuma zem sadalījuma līknes summā, kas vienāda ar a, savukārt [- z a ,+ z a ] ietvaros ir daļa no laukuma, kas vienāda ar 1 - a . Tikko teiktais atbilst šādam varbūtības apgalvojumam:
Р(- z a £  £+z a )= 1-a. (3,27)
£+z a )= 1-a. (3,27)
(Iekavās ieliktās nevienādības izpildes varbūtība ir 1-a.). Pārveidosim izteiksmi iekavās:
Р(-z a  )= 1 - a
)= 1 - a
Mēs saucam vērtību 1-a = Р d par ticamības varbūtību Р d. Saskaņā ar (3.28) ar šo ticamības varbūtību M[X] ticamības intervāls tiek noteikts ar robežām:
 . (3.29)
. (3.29)
komentēt: Diemžēl parastās sadales tabulas dažādās grāmatās ir veidotas atšķirīgi. Dažreiz tiek norādīts varbūtības integrālis
Ф(z) = 
Jebkurš paraugs sniedz tikai aptuvenu priekšstatu par vispārējo populāciju, un visi izlases statistiskie raksturlielumi (vidējais, režīms, dispersija ...) ir vispārīgo parametru tuvinājums vai, teiksim, aplēses, ko vairumā gadījumu nevar aprēķināt vispārējās populācijas nepieejamības dēļ (20. attēls).
20. attēls. Izlases kļūda
Bet jūs varat norādīt intervālu, kurā ar noteiktu varbūtības pakāpi atrodas statistiskā raksturlieluma patiesā (vispārējā) vērtība. Šo intervālu sauc d ticamības intervāls (CI).
Tātad vispārējais vidējais ar varbūtību 95% atrodas iekšā
no līdz, (20)
Kur t - Studenta kritērija tabulas vērtība α =0,05 un f= n-1
Var atrast un 99% CI, šajā gadījumā t izvēlēts α =0,01.
Kāda ir ticamības intervāla praktiskā nozīme?
Plašs ticamības intervāls norāda, ka izlases vidējais rādītājs precīzi neatspoguļo populācijas vidējo vērtību. Parasti tas ir saistīts ar nepietiekamu izlases lielumu vai tā neviendabīgumu, t.i. liela dispersija. Abi dod lielu vidējo kļūdu un attiecīgi plašāku CI. Un tas ir iemesls atgriezties pētniecības plānošanas posmā.
Augšējā un apakšējā CI robeža novērtē, vai rezultāti būs klīniski nozīmīgi
Pakavēsimies sīkāk pie jautājuma par grupu īpašību pētījuma rezultātu statistisko un klīnisko nozīmīgumu. Atgādinām, ka statistikas uzdevums ir atklāt vismaz dažas atšķirības vispārējās populācijās, pamatojoties uz izlases datiem. Klīnicista uzdevums ir atrast tādas (nevis nekādas) atšķirības, kas palīdzēs diagnosticēt vai ārstēt. Un ne vienmēr statistikas secinājumi ir klīnisko secinājumu pamatā. Tādējādi statistiski nozīmīga hemoglobīna līmeņa pazemināšanās par 3 g/l nerada bažas. Un otrādi, ja kādai cilvēka ķermeņa problēmai nav masveida rakstura visu iedzīvotāju līmenī, tas nav iemesls, lai ar šo problēmu netiktu galā.
|
Mēs izskatīsim šo pozīciju piemērs. Pētnieki domāja, vai zēni, kuriem bija kāda veida infekcijas slimība, augšanas ziņā atpaliek no saviem vienaudžiem. Šim nolūkam tika veikts selektīvs pētījums, kurā piedalījās 10 zēni, kuriem bija šī slimība. Rezultāti ir parādīti 23. tabulā. 23. tabula. Statistikas rezultāti
No šiem aprēķiniem izriet, ka selektīvais vidējais augums 10 gadus veciem zēniem, kuriem ir bijusi kāda veida infekcijas slimība, ir tuvu normai (132,5 cm). Taču ticamības intervāla apakšējā robeža (126,6 cm) norāda, ka pastāv 95% varbūtība, ka šo bērnu patiesais vidējais augums atbilst jēdzienam "īss augums", t.i. šie bērni ir panīkuši. Šajā piemērā ticamības intervāla aprēķinu rezultāti ir klīniski nozīmīgi. |
|||||||||||||||||||
Bieži vien vērtētājam ir jāanalizē tā segmenta nekustamā īpašuma tirgus, kurā atrodas vērtēšanas objekts. Ja tirgus ir attīstīts, var būt grūti analizēt visu uzrādīto objektu kopu, tāpēc analīzei tiek izmantots objektu paraugs. Šis paraugs ne vienmēr ir viendabīgs, dažkārt ir nepieciešams to attīrīt no galējībām - pārāk augstiem vai pārāk zemiem tirgus piedāvājumiem. Šim nolūkam tas tiek piemērots ticamības intervāls. Šī pētījuma mērķis ir veikt divu ticamības intervāla aprēķināšanas metožu salīdzinošu analīzi un izvēlēties labāko aprēķina variantu, strādājot ar dažādiem paraugiem sistēmā estimatica.pro.
Ticamības intervāls - aprēķina, pamatojoties uz paraugu, raksturlieluma vērtību intervālu, kas ar zināmu varbūtību satur aprēķināto vispārējās populācijas parametru.
Ticamības intervāla aprēķināšanas nozīme ir tāda intervāla izveidošana, pamatojoties uz izlases datiem, lai ar noteiktu varbūtību varētu apgalvot, ka aplēstā parametra vērtība atrodas šajā intervālā. Citiem vārdiem sakot, ticamības intervāls ar noteiktu varbūtību satur aplēstā daudzuma nezināmo vērtību. Jo plašāks intervāls, jo lielāka ir neprecizitāte.
Ir dažādas metodes ticamības intervāla noteikšanai. Šajā rakstā mēs apsvērsim 2 veidus:
- caur vidējo un standarta novirzi;
- caur t-statistikas kritisko vērtību (Studenta koeficients).
Dažādu CI aprēķināšanas metožu salīdzinošās analīzes posmi:
1. veido datu paraugu;
2. apstrādājam ar statistikas metodēm: aprēķinām vidējo vērtību, mediānu, dispersiju utt.;
3. ticamības intervālu aprēķinām divos veidos;
4. Analizējiet attīrītos paraugus un iegūtos ticamības intervālus.
1. posms. Datu izlase
Izlase veidota, izmantojot estimatica.pro sistēmu. Izlasē tika iekļauts 91 piedāvājums 1-istabas dzīvokļu pārdošanai 3.cenu zonā ar plānojuma veidu "Hruščovs".
1. tabula. Sākotnējais paraugs
|
Cena par 1 kv.m, m.b. |
|
1. att. Sākotnējais paraugs

2. posms. Sākotnējā parauga apstrāde
Paraugu apstrādei ar statistikas metodēm nepieciešams aprēķināt šādas vērtības:
1. Vidējais aritmētiskais

2. Mediāna - skaitlis, kas raksturo izlasi: tieši puse izlases elementu ir lielāki par mediānu, otra puse ir mazāka par mediānu
 (paraugam ar nepāra vērtību skaitu)
(paraugam ar nepāra vērtību skaitu)
3. Diapazons - starpība starp maksimālo un minimālo vērtību paraugā

4. Variance — izmanto, lai precīzāk novērtētu datu variācijas

5. Izlases standarta novirze (turpmāk tekstā – RMS) ir visizplatītākais korekcijas vērtību izkliedes rādītājs ap vidējo aritmētisko.

6. Variācijas koeficients - atspoguļo korekcijas vērtību izkliedes pakāpi

7. svārstību koeficients - atspoguļo izlasē iekļauto cenu galējo vērtību relatīvās svārstības ap vidējo

2. tabula. Sākotnējās izlases statistiskie rādītāji
Variācijas koeficients, kas raksturo datu viendabīgumu, ir 12,29%, bet svārstību koeficients ir pārāk liels. Tādējādi varam apgalvot, ka sākotnējā izlase nav viendabīga, tāpēc pāriesim pie ticamības intervāla aprēķināšanas.
3. posms. Uzticamības intervāla aprēķināšana
1. metode. Aprēķins, izmantojot vidējo un standartnovirzi.
Ticamības intervālu nosaka šādi: minimālā vērtība - no mediānas tiek atņemta standartnovirze; maksimālā vērtība - mediānai tiek pievienota standartnovirze.

Tādējādi ticamības intervāls (47179 CU; 60689 CU)
Rīsi. 2. Vērtības 1. ticamības intervālā.

2. metode. Uzticamības intervāla izveidošana, izmantojot t-statistikas kritisko vērtību (Studenta koeficients)
S.V. Gribovskis grāmatā "Īpašuma vērtības novērtēšanas matemātiskās metodes" apraksta metodi ticamības intervāla aprēķināšanai, izmantojot Studenta koeficientu. Aprēķinot ar šo metodi, novērtētājam pašam ir jāiestata nozīmīguma līmenis ∝, kas nosaka varbūtību, ar kādu tiks izveidots ticamības intervāls. Parasti izmanto nozīmīguma līmeņus 0,1; 0,05 un 0,01. Tās atbilst ticamības varbūtībām 0,9; 0,95 un 0,99. Izmantojot šo metodi, matemātiskās cerības un dispersijas patiesās vērtības tiek uzskatītas par praktiski nezināmām (kas gandrīz vienmēr ir taisnība, risinot praktiskas novērtēšanas problēmas).
Pārliecības intervāla formula:

n - izlases lielums;
t-statistikas (Studenta sadalījumu) kritiskā vērtība ar nozīmības līmeni ∝, brīvības pakāpju skaits n-1, ko nosaka ar speciālām statistikas tabulām vai izmantojot MS Excel (→"Statistical"→ STUDRASPOBR);
∝ - nozīmīguma līmenis, mēs ņemam ∝=0,01.

Rīsi. 2. Vērtības ticamības intervālā 2.

4. solis. Dažādu ticamības intervāla aprēķināšanas veidu analīze
Divas ticamības intervāla aprēķināšanas metodes - caur mediānu un Stjudenta koeficientu - noveda pie dažādām intervālu vērtībām. Attiecīgi tika iegūti divi dažādi attīrīti paraugi.
3. tabula. Statistikas rādītāji trim izlasēm.
|
Rādītājs |
Sākotnējais paraugs |
1 variants |
2. iespēja |
|
Vidējā vērtība |
|||
|
Izkliede |
|||
|
Koef. variācijas |
|||
|
Koef. svārstības |
|||
|
Atbrīvoto objektu skaits, gab. |
|||
Pamatojoties uz veiktajiem aprēķiniem, mēs varam teikt, ka ar dažādām metodēm iegūto ticamības intervālu vērtības krustojas, tāpēc jūs varat izmantot jebkuru no aprēķina metodēm pēc vērtētāja ieskatiem.
Tomēr mēs uzskatām, ka, strādājot estimatica.pro sistēmā, ieteicams izvēlēties metodi ticamības intervāla aprēķināšanai atkarībā no tirgus attīstības pakāpes:
- ja tirgus nav attīstīts, izmantojiet aprēķina metodi, izmantojot mediānu un standartnovirzi, jo izlietoto objektu skaits šajā gadījumā ir mazs;
- ja tirgus ir attīstīts, aprēķinu izmantot caur t-statistikas kritisko vērtību (Studenta koeficients), jo ir iespējams izveidot lielu sākotnējo izlasi.
Sagatavojot rakstu, tika izmantoti:
1. Gribovsky S.V., Sivets S.A., Levykina I.A. Matemātiskās metodes īpašuma vērtības noteikšanai. Maskava, 2014
2. Dati no estimatica.pro sistēmas
Nejaušas kļūdas novērtēšanas metode ir balstīta uz varbūtības teorijas un matemātiskās statistikas principiem. Nejaušu kļūdu iespējams novērtēt tikai tad, ja ir veikti atkārtoti viena un tā paša lieluma mērījumi.
Ļaujiet veikto mērījumu rezultātā P daudzuma vērtības X: X 1 , X 2 , …, x n. Apzīmē ar vidējo aritmētisko
Varbūtību teorijā ir pierādīts, ka, palielinoties mērījumu skaitam P izmērītās vērtības vidējā aritmētiskā vērtība tuvojas patiesajai vērtībai:
Ar nelielu mērījumu skaitu ( P£ 10) vidējā vērtība var būtiski atšķirties no patiesās. Lai zinātu, cik precīzi vērtība raksturo izmērīto vērtību, nepieciešams noteikt iegūtā rezultāta tā saukto ticamības intervālu.
Tā kā absolūti precīzs mērījums nav iespējams, apgalvojuma pareizības varbūtība " x vērtība ir tieši vienāda ar» ir vienāds ar nulli. Izteikuma varbūtība x ir vērtība» ir vienāds ar vienu (100%). Tādējādi jebkura starpteikuma pareizības varbūtība ir diapazonā no 0 līdz 1. Mērījuma mērķis ir atrast tādu intervālu, kurā ar iepriekš noteiktu varbūtību a(0 < a < 1) находится истинное значение измеряемой величины. Этот интервал называется ticamības intervāls , un ar to nesaraujami saistītā vērtība a – pārliecības līmenis (vai uzticamības koeficients). Par intervāla vidu tiek ņemta vidējā vērtība, kas aprēķināta pēc formulas (3). Puse no ticamības intervāla platuma ir nejaušā kļūda D s x(1. att.).
 |
Acīmredzot ticamības intervāla platums (un līdz ar to kļūda D s x) ir atkarīgs no tā, cik daudz ir individuālie mērījumi x i no vidējās vērtības. Mērījumu rezultātu "izkliedi" attiecībā pret vidējo raksturo ar vidējā kvadrātiskā kļūda s, ko atrod pēc formulas
 , (4)
, (4)
Vēlamā ticamības intervāla platums ir tieši proporcionāls kvadrātiskajai kļūdai:
![]() . (5)
. (5)
Proporcionalitātes faktors t n, a sauca Studenta koeficients; tas ir atkarīgs no eksperimentu skaita P un pārliecības līmenis a.
Uz att. 1, a, b Ir skaidri parādīts, ka, ja citas lietas ir vienādas, lai palielinātu varbūtību, ka patiesā vērtība iekrīt ticamības intervālā, ir jāpalielina tā platums (varbūtība, ka vērtība tiks "apsegta" X plašāks intervāls iepriekš). Tāpēc vērtība t n, a jābūt lielākam, jo augstāks ir ticamības līmenis a.
Palielinoties eksperimentu skaitam, vidējā vērtība tuvojas patiesajai vērtībai; tātad ar tādu pašu varbūtību a ticamības intervālu var ņemt šaurāku (sk. 1. att., a, c). Tādējādi ar izaugsmi P sudent koeficientam vajadzētu samazināties. Studenta koeficienta vērtību tabula atkarībā no P Un a sniegts šīs rokasgrāmatas pielikumos.
Jāatzīmē, ka ticamības līmenim nav nekā kopīga ar mērījumu rezultāta precizitāti. Vērtība a ir noteikti iepriekš, pamatojoties uz to uzticamības prasībām. Lielākajā daļā tehnisko eksperimentu un laboratorijas praksē vērtība a tiek pieņemts vienāds ar 0,95.
Nejaušas kļūdas aprēķins daudzuma mērīšanā X veic šādā secībā:
1) aprēķina izmērīto vērtību summu, un pēc tam aprēķina daudzuma vidējo vērtību pēc formulas (3);
2) katram i eksperimentā tiek aprēķināta starpība starp izmērītajām un vidējām vērtībām, kā arī šīs starpības (novirzes) kvadrāts (D x i) 2 ;
3) tiek atrasta noviržu kvadrātā summa un pēc tam vidējā kvadrātiskā kļūda s saskaņā ar formulu (4);
4) atbilstoši noteiktajam ticamības līmenim a un eksperimentu skaitu P no tabulas lpp. 149 pieteikumi izvēlas atbilstošu Studenta koeficienta vērtību t n, a un nejaušā kļūda D s x saskaņā ar formulu (5).
Aprēķinu ērtībai un starprezultātu pārbaudei datus ievada tabulā, kuras pēdējās trīs ailes aizpilda pēc 1.tabulas parauga.
1. tabula
| Pieredzes numurs | … | X | D X | (D X) 2 |
| … | ||||
| … | ||||
| … | … | |||
| P | … | |||
| S= | S= |
Katrā konkrētajā gadījumā vērtība X ir noteikta fiziska nozīme un atbilstošas mērvienības. Tas var būt, piemēram, brīvā kritiena paātrinājums g (jaunkundze 2), šķidruma viskozitāte h (Pa×s) utt. Tabulā trūkst kolonnu. 1 var saturēt starpposma izmērītās vērtības, kas nepieciešamas atbilstošo vērtību aprēķināšanai X.
1. piemērs Lai noteiktu paātrinājumu Aķermeņa kustības mērīts laiks t ejot garām S nav sākuma ātruma. Izmantojot zināmo attiecību , iegūstam aprēķina formulu
Ceļa mērīšanas rezultāti S un laiks t ir doti tabulas otrajā un trešajā slejā. 2. Pēc aprēķinu veikšanas, izmantojot formulu (6), aizpildām
ceturtā kolonna ar paātrinājuma vērtībām a i un atrodiet to summu, ko mēs ierakstām zem šīs kolonnas šūnā "S =". Pēc tam mēs aprēķinām vidējo vērtību pēc formulas (3)
![]() .
.
2. tabula
| Pieredzes numurs | S, m | t, c | A, jaunkundze 2 | D A, jaunkundze 2 | (D A) 2 , (jaunkundze 2) 2 |
| 2,20 | 2,07 | 0,04 | 0,0016 | ||
| 2,68 | 1,95 | -0,08 | 0,0064 | ||
| 2,91 | 2,13 | 0,10 | 0,0100 | ||
| 3,35 | 1,96 | -0,07 | 0,0049 | ||
| S= | 8,11 | S= | 0,0229 |
Atņemot no katras vērtības a i vidēji, atrodiet atšķirības D a i un ievietojiet tos tabulas piektajā kolonnā. Izvērtējot šīs atšķirības kvadrātā, mēs aizpildām pēdējo kolonnu. Tad mēs aprēķinām noviržu kvadrātā summu un ierakstām to otrajā šūnā "S =". Saskaņā ar formulu (4) mēs nosakām vidējo kvadrātisko kļūdu:
 .
.
Ņemot vērā ticamības varbūtības vērtību a= 0,95, eksperimentu skaitam P= 4 no tabulas pielikumos (149. lpp.) izvēlieties Studenta koeficienta vērtību t n, a= 3,18; izmantojot formulu (5), mēs novērtējam nejaušo kļūdu paātrinājuma mērīšanā
D s a= 3,18 × 0,0437 » 0,139 ( jaunkundze 2) .
Uzticamības intervālu novērtējums
Mācību mērķi
Statistika ņem vērā sekojošo divi galvenie uzdevumi:
Mums ir daži aprēķini, kuru pamatā ir izlases dati, un mēs vēlamies sniegt varbūtības apgalvojumu par to, kur atrodas aplēstā parametra patiesā vērtība.
Mums ir konkrēta hipotēze, kas ir jāpārbauda, pamatojoties uz izlases datiem.
Šajā tēmā mēs aplūkojam pirmo problēmu. Mēs arī ieviešam ticamības intervāla definīciju.
Ticamības intervāls ir intervāls, kas tiek veidots ap aplēsto parametra vērtību un parāda, kur atrodas aplēstā parametra patiesā vērtība ar a priori noteiktu varbūtību.
Izpētījis materiālu par šo tēmu, jūs:
uzzināt, kāds ir novērtējuma ticamības intervāls;
iemācīties klasificēt statistikas problēmas;
apgūt ticamības intervālu konstruēšanas tehniku, gan izmantojot statistikas formulas, gan izmantojot programmatūras rīkus;
iemācīties noteikt nepieciešamos izlases lielumus, lai sasniegtu noteiktus statistisko aplēšu precizitātes parametrus.
Izlases raksturlielumu sadalījumi
T-sadale
Kā minēts iepriekš, gadījuma lieluma sadalījums ir tuvu standartizētam normālajam sadalījumam ar parametriem 0 un 1. Tā kā mēs nezinām σ vērtību, mēs to aizstājam ar kādu novērtējumu s . Daudzumam jau ir atšķirīgs sadalījums, proti, vai Studentu sadalījums, ko nosaka ar parametru n -1 (brīvības pakāpju skaits). Šis sadalījums ir tuvu normālajam sadalījumam (jo lielāks n, jo tuvāki sadalījumi).
Uz att. 95  Tiek parādīts studentu sadalījums ar 30 brīvības pakāpēm. Kā redzat, tas ir ļoti tuvu normālajam sadalījumam.
Tiek parādīts studentu sadalījums ar 30 brīvības pakāpēm. Kā redzat, tas ir ļoti tuvu normālajam sadalījumam.
Līdzīgi kā funkcijām darbam ar normālo sadalījumu NORMDIST un NORMINV, ir arī funkcijas darbam ar t sadalījumu - STUDIST (TDIST) un STUDRASPBR (TINV). Šo funkciju izmantošanas piemēru var atrast STUDRIST.XLS failā (veidne un risinājums) un att. 96  .
.
Citu raksturlielumu sadalījumi
Kā mēs jau zinām, lai noteiktu gaidu aplēses precizitāti, mums ir nepieciešams t sadalījums. Lai novērtētu citus parametrus, piemēram, dispersiju, ir nepieciešami citi sadalījumi. Divi no tiem ir F sadalījums un x 2 -sadale.
Pārliecības intervāls vidējam
Ticamības intervāls ir intervāls, kas tiek veidots ap aplēsto parametra vērtību un parāda, kur atrodas aprēķinātā parametra patiesā vērtība ar a priori noteiktu varbūtību.
Tiek izveidots ticamības intervāls vidējai vērtībai šādā veidā:
Piemērs
Ātrās ēdināšanas restorāns plāno paplašināt savu sortimentu ar jauna veida sviestmaizi. Lai novērtētu pieprasījumu pēc tā, vadītājs plāno nejauši atlasīt 40 apmeklētājus no jau izmēģinājušiem un lūgt novērtēt savu attieksmi pret jauno produktu skalā no 1 līdz 10. Vadītājs vēlas novērtēt paredzamo punktu skaitu, ko jaunais produkts saņems, un izveidot šī novērtējuma 95% ticamības intervālu. Kā to izdarīt? (skatiet failu SANDWICH1.XLS (veidne un risinājums).
Risinājums
Lai atrisinātu šo problēmu, varat izmantot. Rezultāti ir parādīti attēlā. 97  .
.
Kopējās vērtības ticamības intervāls
Dažkārt pēc izlases datiem ir jānovērtē nevis matemātiskā cerība, bet gan vērtību kopējā summa. Piemēram, situācijā ar revidentu var būt interesanti novērtēt nevis rēķina vidējo vērtību, bet gan visu rēķinu summu.
Ļaujiet N ir kopējais elementu skaits, n ir izlases lielums, T 3 ir izlasē esošo vērtību summa, T" ir summas aprēķins visā populācijā, tad , un ticamības intervālu aprēķina pēc formulas , kur s ir izlases standartnovirzes novērtējums, ir izlases vidējās vērtības novērtējums.
Piemērs
Pieņemsim, ka nodokļu iestāde vēlas aprēķināt kopējo nodokļu atmaksas summu 10 000 nodokļu maksātājiem. Nodokļu maksātājs vai nu saņem atmaksu, vai arī maksā papildu nodokļus. Atrodiet 95% ticamības intervālu atmaksas summai, pieņemot, ka izlases lielums ir 500 personas (skatiet failu REFUND AMOUNT.XLS (veidne un risinājums).
Risinājums
Šim gadījumam StatPro nav īpašas procedūras, taču var redzēt, ka robežas var iegūt no vidējā lieluma robežām, izmantojot iepriekš minētās formulas (98. att.  ).
).
Pārliecības intervāls proporcijai
Ļaujiet p apzīmēt klientu daļu, bet pv ir šīs daļas novērtējums, kas iegūts no n lieluma izlases. Var pierādīt, ka pietiekami lielai  aplēses sadalījums būs tuvu normālam ar vidējo p un standarta novirzi
aplēses sadalījums būs tuvu normālam ar vidējo p un standarta novirzi ![]() . Novērtējuma standartkļūda šajā gadījumā tiek izteikta kā
. Novērtējuma standartkļūda šajā gadījumā tiek izteikta kā  , un ticamības intervāls kā
, un ticamības intervāls kā  .
.
Piemērs
Ātrās ēdināšanas restorāns plāno paplašināt savu sortimentu ar jauna veida sviestmaizi. Lai novērtētu pieprasījumu pēc tā, vadītājs nejauši izvēlējās 40 apmeklētājus no jau izmēģinājušajiem un lūdza novērtēt savu attieksmi pret jauno produktu skalā no 1 līdz 10. Vadītājs vēlas novērtēt paredzamo to klientu īpatsvaru, kuri jauno produktu novērtēs vismaz ar 6 ballēm (viņš paredz, ka šie klienti būs jaunā produkta patērētāji).
Risinājums
Sākotnēji mēs izveidojam jaunu kolonnu, pamatojoties uz 1, ja klienta rezultāts bija lielāks par 6 punktiem un 0 pārējā gadījumā (skatiet failu SANDWICH2.XLS (veidne un risinājums).
1. metode
Saskaitot summu 1, mēs novērtējam daļu un pēc tam izmantojam formulas.
Z cr vērtība tiek ņemta no īpašām normālā sadalījuma tabulām (piemēram, 1,96 95% ticamības intervālam).
Izmantojot šo pieeju un konkrētus datus, lai izveidotu 95% intervālu, mēs iegūstam šādus rezultātus (99. att.  ). Parametra z cr kritiskā vērtība ir 1,96. Novērtējuma standartkļūda ir 0,077. Uzticamības intervāla apakšējā robeža ir 0,475. Ticamības intervāla augšējā robeža ir 0,775. Tādējādi vadītājs ar 95% pārliecību var pieņemt, ka to klientu procentuālais daudzums, kuri jauno produktu novērtē ar 6 vai vairāk punktiem, būs no 47,5 līdz 77,5.
). Parametra z cr kritiskā vērtība ir 1,96. Novērtējuma standartkļūda ir 0,077. Uzticamības intervāla apakšējā robeža ir 0,475. Ticamības intervāla augšējā robeža ir 0,775. Tādējādi vadītājs ar 95% pārliecību var pieņemt, ka to klientu procentuālais daudzums, kuri jauno produktu novērtē ar 6 vai vairāk punktiem, būs no 47,5 līdz 77,5.
2. metode
Šo problēmu var atrisināt, izmantojot standarta StatPro rīkus. Lai to izdarītu, pietiek atzīmēt, ka daļa šajā gadījumā sakrīt ar kolonnas Tips vidējo vērtību. Nākamais pieteikties StatPro/Statistikas secinājumi/Viena parauga analīze lai izveidotu ticamības intervālu vidējai vērtībai (paredzamā aplēse) kolonnai Tips. Šajā gadījumā iegūtie rezultāti būs ļoti tuvi 1. metodes rezultātam (99. att.).
Standarta novirzes ticamības intervāls
s izmanto kā standartnovirzes aprēķinu (formula dota 1. sadaļā). Novērtējuma s blīvuma funkcija ir hī kvadrāta funkcija, kurai, tāpat kā t sadalījumam, ir n-1 brīvības pakāpe. Ir īpašas funkcijas darbam ar šo izplatīšanu CHI2DIST (CHIDIST) un CHI2OBR (CHIINV) .
Uzticamības intervāls šajā gadījumā vairs nebūs simetrisks. Robežu nosacītā shēma parādīta att. 100 .
Piemērs
Mašīnai vajadzētu ražot detaļas ar diametru 10 cm. Tomēr dažādu apstākļu dēļ rodas kļūdas. Kvalitātes kontrolieri uztrauc divas lietas: pirmkārt, vidējai vērtībai jābūt 10 cm; otrkārt, pat šajā gadījumā, ja novirzes ir lielas, daudzas detaļas tiks noraidītas. Katru dienu viņš izgatavo 50 detaļu paraugu (skat. failu QUALITY CONTROL.XLS (veidne un risinājums). Kādus secinājumus šāds paraugs var dot?
Risinājums
Mēs veidojam 95% ticamības intervālus vidējam un standarta novirzei, izmantojot StatPro / statistikas secinājumi / viena parauga analīze(101. att  ).
).
Tālāk, izmantojot pieņēmumu par normālu diametru sadalījumu, mēs aprēķinām bojāto izstrādājumu proporciju, nosakot maksimālo novirzi 0,065. Izmantojot uzmeklēšanas tabulas iespējas (divu parametru gadījums), konstruējam noraidīto procentuālās daļas atkarību no vidējās vērtības un standartnovirzes (102. att.  ).
).
Pārliecības intervāls divu vidējo starpībai
Šis ir viens no svarīgākajiem statistikas metožu pielietojumiem. Situāciju piemēri.
Apģērbu veikala vadītāja vēlas uzzināt, cik daudz vairāk vai mazāk vidējā pircēja sieviete veikalā tērē nekā vīrietis.
Abas aviosabiedrības veic lidojumus līdzīgos maršrutos. Patērētāju organizācija vēlas salīdzināt abu aviosabiedrību vidējo paredzamo lidojumu kavēšanās laiku atšķirību.
Uzņēmums izsūta kuponus noteikta veida precēm vienā pilsētā un neizsūta citā. Vadītāji vēlas salīdzināt vidējos šo preču pirkumus nākamo divu mēnešu laikā.
Automašīnu tirgotājs prezentācijās bieži nodarbojas ar precētiem pāriem. Lai saprastu viņu personīgās reakcijas uz prezentāciju, pāri bieži tiek intervēti atsevišķi. Vadītājs vēlas novērtēt vīriešu un sieviešu sniegto vērtējumu atšķirību.
Neatkarīgu paraugu gadījums
Vidējai starpībai būs t sadalījums ar n 1 + n 2 - 2 brīvības pakāpēm. Ticamības intervālu μ 1 - μ 2 izsaka ar attiecību:

Šo problēmu var atrisināt ne tikai ar iepriekš minētajām formulām, bet arī ar standarta StatPro rīkiem. Lai to izdarītu, pietiek ar pieteikumu
Pārliecības intervāls starpībai starp proporcijām
Ļaut būt matemātiskām akcijām. Ļaujiet būt viņu izlases aplēsēm, kas balstītas uz attiecīgi n 1 un n 2 lieluma paraugiem. Tad ir aplēse par starpību. Tāpēc šīs atšķirības ticamības intervāls tiek izteikts šādi:
Šeit z cr ir vērtība, kas iegūta no speciālo tabulu normālā sadalījuma (piemēram, 1,96 95% ticamības intervālam).
Novērtējuma standarta kļūdu šajā gadījumā izsaka ar attiecību:
 .
.
Piemērs
Veikals, gatavojoties lielajai izpārdošanai, veica šādu mārketinga pētījumu. Tika atlasīti 300 labākie pircēji un nejauši sadalīti divās grupās pa 150 dalībniekiem katrā. Visiem atlasītajiem pircējiem tika nosūtīti uzaicinājumi piedalīties izpārdošanā, bet tikai pirmās grupas dalībniekiem tika pievienots kupons, kas dod tiesības uz 5% atlaidi. Izpārdošanas laikā tika fiksēti visu 300 atlasīto pircēju pirkumi. Kā vadītājs var interpretēt rezultātus un pieņemt lēmumu par kuponu efektivitāti? (Skatiet failu COUPONS.XLS (veidne un risinājums)).
Risinājums
Mūsu konkrētajā gadījumā no 150 klientiem, kuri saņēma atlaižu kuponu, 55 veica pirkumu izpārdošanā, bet no 150, kas kuponu nesaņēma, tikai 35 veica pirkumu (103. att.  ). Tad parauga proporciju vērtības ir attiecīgi 0,3667 un 0,2333. Un izlases starpība starp tām ir attiecīgi vienāda ar 0,1333. Pieņemot, ka ticamības intervāls ir 95%, no normālā sadalījuma tabulas atrodam z cr = 1,96. Izlases starpības standartkļūdas aprēķins ir 0,0524. Visbeidzot, mēs iegūstam, ka 95% ticamības intervāla apakšējā robeža ir attiecīgi 0,0307 un augšējā robeža ir attiecīgi 0,2359. Iegūtos rezultātus var interpretēt tā, ka uz katriem 100 klientiem, kuri saņēma atlaižu kuponu, varam sagaidīt no 3 līdz 23 jauniem klientiem. Taču jāpatur prātā, ka šis secinājums pats par sevi nenozīmē kuponu izmantošanas efektivitāti (jo, nodrošinot atlaidi, mēs zaudējam peļņu!). Pierādīsim to uz konkrētiem datiem. Pieņemsim, ka vidējā pirkuma summa ir 400 rubļu, no kuriem 50 rubļi. ir veikala peļņa. Tad paredzamā peļņa uz 100 klientiem, kuri nesaņēma kuponu, ir vienāda ar:
). Tad parauga proporciju vērtības ir attiecīgi 0,3667 un 0,2333. Un izlases starpība starp tām ir attiecīgi vienāda ar 0,1333. Pieņemot, ka ticamības intervāls ir 95%, no normālā sadalījuma tabulas atrodam z cr = 1,96. Izlases starpības standartkļūdas aprēķins ir 0,0524. Visbeidzot, mēs iegūstam, ka 95% ticamības intervāla apakšējā robeža ir attiecīgi 0,0307 un augšējā robeža ir attiecīgi 0,2359. Iegūtos rezultātus var interpretēt tā, ka uz katriem 100 klientiem, kuri saņēma atlaižu kuponu, varam sagaidīt no 3 līdz 23 jauniem klientiem. Taču jāpatur prātā, ka šis secinājums pats par sevi nenozīmē kuponu izmantošanas efektivitāti (jo, nodrošinot atlaidi, mēs zaudējam peļņu!). Pierādīsim to uz konkrētiem datiem. Pieņemsim, ka vidējā pirkuma summa ir 400 rubļu, no kuriem 50 rubļi. ir veikala peļņa. Tad paredzamā peļņa uz 100 klientiem, kuri nesaņēma kuponu, ir vienāda ar:
50 0,2333 100 \u003d 1166,50 rubļi.
Līdzīgi aprēķini 100 pircējiem, kuri saņēma kuponu, sniedz:
30 0,3667 100 \u003d 1100,10 rubļi.
Vidējās peļņas samazinājums līdz 30 skaidrojams ar to, ka, izmantojot atlaidi, pircēji, kuri saņēmuši kuponu, vidēji iepirksies par 380 rubļiem.
Tādējādi gala secinājums norāda uz šādu kuponu izmantošanas neefektivitāti konkrētajā situācijā.
komentēt. Šo problēmu var atrisināt, izmantojot standarta StatPro rīkus. Lai to izdarītu, pietiek ar šo problēmu reducēt līdz divu vidējo rādītāju starpības noteikšanai ar metodi un pēc tam piemērot StatPro/Statistikas secinājumi/Divu paraugu analīze lai izveidotu ticamības intervālu starpībai starp divām vidējām vērtībām.
Pārliecības intervāla kontrole
Uzticamības intervāla garums ir atkarīgs no šādiem nosacījumiem:
tieši dati (standarta novirze);
nozīmīguma līmenis;
parauga lielums.
Izlases lielums vidējās vērtības noteikšanai
Vispirms apskatīsim problēmu vispārīgā gadījumā. Apzīmēsim pusi no mums dotā ticamības intervāla garuma vērtību kā B (104. att.  ). Mēs zinām, ka kāda nejauša lieluma X vidējās vērtības ticamības intervāls ir izteikts kā
). Mēs zinām, ka kāda nejauša lieluma X vidējās vērtības ticamības intervāls ir izteikts kā ![]() , Kur
, Kur ![]() . Pieņemot:
. Pieņemot:
![]() un izsakot n , mēs iegūstam .
un izsakot n , mēs iegūstam .
Diemžēl mēs nezinām precīzu nejaušā lieluma X dispersijas vērtību. Turklāt mēs nezinām t cr vērtību, jo tā ir atkarīga no n caur brīvības pakāpju skaitu. Šajā situācijā mēs varam rīkoties šādi. Dispersijas s vietā mēs izmantojam dažus dispersijas aprēķinus dažām pieejamajām pētāmā nejaušā mainīgā realizācijas iespējām. T cr vērtības vietā mēs izmantojam z cr vērtību normālajam sadalījumam. Tas ir diezgan pieņemami, jo blīvuma funkcijas normālajam un t sadalījumam ir ļoti tuvas (izņemot mazo n gadījumu). Tādējādi vēlamā formula iegūst šādu formu:
 .
.
Tā kā formula sniedz, vispārīgi runājot, rezultātus, kas nav veseli, noapaļošana ar rezultāta pārsniegumu tiek uzskatīta par vēlamo izlases lielumu.
Piemērs
Ātrās ēdināšanas restorāns plāno paplašināt savu sortimentu ar jauna veida sviestmaizi. Lai novērtētu pieprasījumu pēc tā, vadītājs pēc nejaušības principa plāno atlasīt apmeklētāju skaitu no tiem, kas to jau ir izmēģinājuši, un lūgt viņus novērtēt savu attieksmi pret jauno produktu skalā no 1 līdz 10. Vadītājs vēlas novērtēt paredzamo punktu skaitu, ko jaunais produkts saņems, un izveidot šī novērtējuma 95% ticamības intervālu. Tomēr viņš vēlas, lai puse no ticamības intervāla platuma nepārsniegtu 0,3. Cik apmeklētāju viņam vajag, lai aptaujātu?
sekojoši:

Šeit r ots ir daļas p novērtējums, un B ir dotā puse no ticamības intervāla garuma. Izmantojot vērtību, var iegūt n palielināto vērtību r ots= 0,5. Šajā gadījumā ticamības intervāla garums nepārsniegs doto vērtību B nevienai patiesajai p vērtībai.
Piemērs
Ļaujiet vadītājam no iepriekšējā piemēra plānot to klientu īpatsvaru, kuri dod priekšroku jauna veida produktam. Viņš vēlas izveidot 90% ticamības intervālu, kura pusgarums ir mazāks vai vienāds ar 0,05. Cik daudz klientu vajadzētu izlases veidā atlasīt?
Risinājums
Mūsu gadījumā z cr vērtība = 1,645. Tāpēc nepieciešamais daudzums tiek aprēķināts kā  .
.
Ja vadītājam būtu pamats uzskatīt, ka vēlamā p vērtība ir, piemēram, aptuveni 0,3, tad, aizvietojot šo vērtību iepriekš minētajā formulā, mēs iegūtu mazāku nejaušās izlases vērtību, proti, 228.
Formula noteikšanai izlases lielumi, ja atšķiras divi vidējie rādītāji rakstīts kā:
 .
.
Piemērs
Dažiem datoru uzņēmumiem ir klientu apkalpošanas centrs. Pēdējā laikā pieaudzis klientu sūdzību skaits par slikto servisa kvalitāti. Servisa centrā galvenokārt strādā divu veidu darbinieki: tie ar nelielu pieredzi, bet ir izgājuši speciālos apmācību kursus, un tie, kuriem ir liela praktiskā pieredze, bet kuri nav izgājuši speciālos kursus. Uzņēmums vēlas analizēt klientu sūdzības pēdējo sešu mēnešu laikā un salīdzināt to vidējo skaitu uz katru no divām darbinieku grupām. Tiek pieņemts, ka skaitļi izlasēs abām grupām būs vienādi. Cik darbinieku jāiekļauj izlasē, lai iegūtu 95% intervālu ar pusgarumu ne vairāk kā 2?
Risinājums
Šeit σ ots ir abu nejaušo mainīgo standartnovirzes aprēķins, pieņemot, ka tie ir tuvu. Tādējādi mūsu uzdevumā mums ir kaut kādā veidā jāiegūst šī aplēse. To var izdarīt, piemēram, šādi. Aplūkojot datus par klientu sūdzībām pēdējo sešu mēnešu laikā, vadītājs var pamanīt, ka uz vienu darbinieku parasti ir no 6 līdz 36 sūdzībām. Zinot, ka normālam sadalījumam praktiski visas vērtības ir ne vairāk kā trīs standarta novirzes no vidējā, viņš var pamatoti uzskatīt, ka:
No kurienes σ ots = 5.
Aizvietojot šo vērtību formulā, mēs iegūstam  .
.
Formula noteikšanai nejaušās izlases lielums, ja tiek novērtēta starpība starp daļām izskatās kā:

Piemērs
Dažam uzņēmumam ir divas rūpnīcas līdzīgu produktu ražošanai. Uzņēmuma vadītājs vēlas salīdzināt abu rūpnīcu defektu rādītājus. Saskaņā ar pieejamo informāciju noraidījumu līmenis abās rūpnīcās ir no 3 līdz 5%. Ir paredzēts izveidot 99% ticamības intervālu ar pusgarumu, kas nepārsniedz 0,005 (vai 0,5%). Cik daudz produktu jāizvēlas no katras rūpnīcas?
Risinājums
Šeit p 1ot un p 2ot ir aplēses par divām nezināmām atkritumiem 1. un 2. rūpnīcā. Ja liksim p 1ots \u003d p 2ots \u003d 0,5, tad n iegūsim pārvērtētu vērtību. Bet, tā kā mūsu gadījumā mums ir zināma a priori informācija par šīm akcijām, tad mēs ņemam šo akciju augšējo tāmi, proti, 0,05. Mēs saņemam
Kad daži populācijas parametri tiek novērtēti no izlases datiem, ir lietderīgi nodrošināt ne tikai parametra punktveida novērtējumu, bet arī ticamības intervālu, kas parāda, kur var atrasties aplēstā parametra precīzā vērtība.
Šajā nodaļā iepazināmies arī ar kvantitatīvajām sakarībām, kas ļauj veidot šādus intervālus dažādiem parametriem; uzzināja veidus, kā kontrolēt ticamības intervāla garumu.
Mēs arī atzīmējam, ka izlases lieluma noteikšanas problēmu (eksperimenta plānošanas problēmu) var atrisināt, izmantojot standarta StatPro rīkus, proti, StatPro/Statistikas secinājumi/Parauga lieluma izvēle.