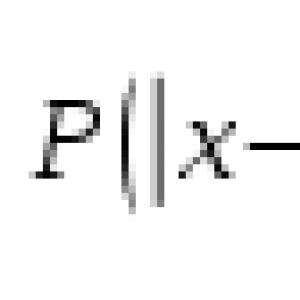The random variable x has a distribution. Normal law of probability distribution
Random variable a variable is called which, as a result of each test, takes on one previously unknown value, depending on random causes. Random variables are denoted by capital Latin letters: $X,\ Y,\ Z,\ \dots $ By their type, random variables can be discrete and continuous.
Discrete random variable- this is such a random variable, the values of which can be no more than countable, that is, either finite or countable. Countability means that the values of a random variable can be enumerated.
Example 1 . Let us give examples of discrete random variables:
a) the number of hits on the target with $n$ shots, here the possible values are $0,\ 1,\ \dots ,\ n$.
b) the number of coats of arms that fell out when tossing a coin, here the possible values are $0,\ 1,\ \dots ,\ n$.
c) the number of ships that arrived on board (a countable set of values).
d) the number of calls arriving at the exchange (a countable set of values).
1. Law of probability distribution of a discrete random variable.
A discrete random variable $X$ can take the values $x_1,\dots ,\ x_n$ with probabilities $p\left(x_1\right),\ \dots ,\ p\left(x_n\right)$. The correspondence between these values and their probabilities is called distribution law of a discrete random variable. As a rule, this correspondence is specified using a table, in the first line of which the values of $x_1,\dots ,\ x_n$ are indicated, and in the second line the probabilities corresponding to these values are $p_1,\dots ,\ p_n$.
$\begin(array)(|c|c|)
\hline
X_i & x_1 & x_2 & \dots & x_n \\
\hline
p_i & p_1 & p_2 & \dots & p_n \\
\hline
\end(array)$
Example 2 . Let the random variable $X$ be the number of points rolled when a dice is rolled. Such a random variable $X$ can take the following values $1,\ 2,\ 3,\ 4,\ 5,\ 6$. The probabilities of all these values are equal to $1/6$. Then the probability distribution law for the random variable $X$:
$\begin(array)(|c|c|)
\hline
1 & 2 & 3 & 4 & 5 & 6 \\
\hline
\hline
\end(array)$
Comment. Since the events $1,\ 2,\ \dots ,\ 6$ form a complete group of events in the distribution law of the discrete random variable $X$, the sum of the probabilities must be equal to one, i.e. $\sum(p_i)=1$.
2. Mathematical expectation of a discrete random variable.
Mathematical expectation of a random variable specifies its "central" value. For a discrete random variable, the mathematical expectation is calculated as the sum of the products of the values $x_1,\dots ,\ x_n$ and the probabilities $p_1,\dots ,\ p_n$ corresponding to these values, i.e.: $M\left(X\right)=\sum ^n_(i=1)(p_ix_i)$. In English literature, another notation $E\left(X\right)$ is used.
Expectation Properties$M\left(X\right)$:
- $M\left(X\right)$ is between the smallest and largest values of the random variable $X$.
- The mathematical expectation of a constant is equal to the constant itself, i.e. $M\left(C\right)=C$.
- The constant factor can be taken out of the expectation sign: $M\left(CX\right)=CM\left(X\right)$.
- The mathematical expectation of the sum of random variables is equal to the sum of their mathematical expectations: $M\left(X+Y\right)=M\left(X\right)+M\left(Y\right)$.
- The mathematical expectation of the product of independent random variables is equal to the product of their mathematical expectations: $M\left(XY\right)=M\left(X\right)M\left(Y\right)$.
Example 3 . Let's find the mathematical expectation of the random variable $X$ from example $2$.
$$M\left(X\right)=\sum^n_(i=1)(p_ix_i)=1\cdot ((1)\over (6))+2\cdot ((1)\over (6) )+3\cdot ((1)\over (6))+4\cdot ((1)\over (6))+5\cdot ((1)\over (6))+6\cdot ((1 )\over (6))=3.5.$$
We can notice that $M\left(X\right)$ is between the smallest ($1$) and largest ($6$) values of the random variable $X$.
Example 4 . It is known that the mathematical expectation of the random variable $X$ is equal to $M\left(X\right)=2$. Find the mathematical expectation of the random variable $3X+5$.
Using the above properties, we get $M\left(3X+5\right)=M\left(3X\right)+M\left(5\right)=3M\left(X\right)+5=3\cdot 2 +5=11$.
Example 5 . It is known that the mathematical expectation of the random variable $X$ is equal to $M\left(X\right)=4$. Find the mathematical expectation of the random variable $2X-9$.
Using the above properties, we get $M\left(2X-9\right)=M\left(2X\right)-M\left(9\right)=2M\left(X\right)-9=2\cdot 4 -9=-1$.
3. Dispersion of a discrete random variable.
Possible values of random variables with equal mathematical expectations can scatter differently around their average values. For example, in two student groups, the average score for the exam in probability theory turned out to be 4, but in one group everyone turned out to be good students, and in the other group - only C students and excellent students. Therefore, there is a need for such a numerical characteristic of a random variable, which would show the spread of the values of a random variable around its mathematical expectation. This characteristic is dispersion.
Dispersion of a discrete random variable$X$ is:
$$D\left(X\right)=\sum^n_(i=1)(p_i(\left(x_i-M\left(X\right)\right))^2).\ $$
In English literature, the notation $V\left(X\right),\ Var\left(X\right)$ is used. Very often the variance $D\left(X\right)$ is calculated by the formula $D\left(X\right)=\sum^n_(i=1)(p_ix^2_i)-(\left(M\left(X \right)\right))^2$.
Dispersion Properties$D\left(X\right)$:
- The dispersion is always greater than or equal to zero, i.e. $D\left(X\right)\ge 0$.
- The dispersion from a constant is equal to zero, i.e. $D\left(C\right)=0$.
- The constant factor can be taken out of the dispersion sign, provided that it is squared, i.e. $D\left(CX\right)=C^2D\left(X\right)$.
- The variance of the sum of independent random variables is equal to the sum of their variances, i.e. $D\left(X+Y\right)=D\left(X\right)+D\left(Y\right)$.
- The variance of the difference of independent random variables is equal to the sum of their variances, i.e. $D\left(X-Y\right)=D\left(X\right)+D\left(Y\right)$.
Example 6 . Let us calculate the variance of the random variable $X$ from example $2$.
$$D\left(X\right)=\sum^n_(i=1)(p_i(\left(x_i-M\left(X\right)\right))^2)=((1)\over (6))\cdot (\left(1-3,5\right))^2+((1)\over (6))\cdot (\left(2-3,5\right))^2+ \dots +((1)\over (6))\cdot (\left(6-3,5\right))^2=((35)\over (12))\approx 2.92.$$
Example 7 . It is known that the variance of the random variable $X$ is equal to $D\left(X\right)=2$. Find the variance of the random variable $4X+1$.
Using the above properties, we find $D\left(4X+1\right)=D\left(4X\right)+D\left(1\right)=4^2D\left(X\right)+0=16D\ left(X\right)=16\cdot 2=32$.
Example 8 . It is known that the variance of $X$ is equal to $D\left(X\right)=3$. Find the variance of the random variable $3-2X$.
Using the above properties, we find $D\left(3-2X\right)=D\left(3\right)+D\left(2X\right)=0+2^2D\left(X\right)=4D\ left(X\right)=4\cdot 3=12$.
4. Distribution function of a discrete random variable.
The method of representing a discrete random variable in the form of a distribution series is not the only one, and most importantly, it is not universal, since a continuous random variable cannot be specified using a distribution series. There is another way to represent a random variable - the distribution function.
distribution function random variable $X$ is a function $F\left(x\right)$, which determines the probability that the random variable $X$ takes a value less than some fixed value $x$, i.e. $F\left(x\right)$ )=P\left(X< x\right)$
Distribution function properties:
- $0\le F\left(x\right)\le 1$.
- The probability that the random variable $X$ takes values from the interval $\left(\alpha ;\ \beta \right)$ is equal to the difference between the values of the distribution function at the ends of this interval: $P\left(\alpha< X < \beta \right)=F\left(\beta \right)-F\left(\alpha \right)$
- $F\left(x\right)$ - non-decreasing.
- $(\mathop(lim)_(x\to -\infty ) F\left(x\right)=0\ ),\ (\mathop(lim)_(x\to +\infty ) F\left(x \right)=1\ )$.
Example 9 . Let us find the distribution function $F\left(x\right)$ for the distribution law of the discrete random variable $X$ from example $2$.
$\begin(array)(|c|c|)
\hline
1 & 2 & 3 & 4 & 5 & 6 \\
\hline
1/6 & 1/6 & 1/6 & 1/6 & 1/6 & 1/6 \\
\hline
\end(array)$
If $x\le 1$, then obviously $F\left(x\right)=0$ (including $x=1$ $F\left(1\right)=P\left(X< 1\right)=0$).
If $1< x\le 2$, то $F\left(x\right)=P\left(X=1\right)=1/6$.
If $2< x\le 3$, то $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)=1/6+1/6=1/3$.
If $3< x\le 4$, то $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right)=1/6+1/6+1/6=1/2$.
If $4< x\le 5$, то $F\left(X\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right)+P\left(X=4\right)=1/6+1/6+1/6+1/6=2/3$.
If $5< x\le 6$, то $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right)+P\left(X=4\right)+P\left(X=5\right)=1/6+1/6+1/6+1/6+1/6=5/6$.
If $x > 6$ then $F\left(x\right)=P\left(X=1\right)+P\left(X=2\right)+P\left(X=3\right) +P\left(X=4\right)+P\left(X=5\right)+P\left(X=6\right)=1/6+1/6+1/6+1/6+ 1/6+1/6=1$.
So $F(x)=\left\(\begin(matrix)
0,\ at\ x\le 1,\\
1/6, at \ 1< x\le 2,\\
1/3,\ at\ 2< x\le 3,\\
1/2, at \ 3< x\le 4,\\
2/3,\ at\ 4< x\le 5,\\
5/6, \ at \ 4< x\le 5,\\
1,\ for \ x > 6.
\end(matrix)\right.$
Among the distribution laws for discrete random variables, the most common is the binomial distribution law. The binomial distribution takes place under the following conditions. Let a random variable be the number of occurrences of some event in independent trials, the probability of occurrence in a separate trial is . This random variable is a discrete random variable, its possible values are . The probability that a random variable will take a value is calculated by the Bernoulli formula: .
Definition 15. The distribution law of a discrete random variable is called the binomial distribution law if the probabilities of the values of the random variable are calculated using the Bernoulli formula. The distribution series will look like:
Let us make sure that the sum of the probabilities of different values of the random variable is equal to 1. Indeed,
Since these calculations resulted in Newton's binomial formula, therefore, the distribution law is called binomial. If a random variable has a binomial distribution, then its numerical characteristics are found by the formulas:
(42)
![]() (43)
(43)
Example 15 There is a batch of 50 parts. The probability of marriage for one part. Let a random variable be the number of defective parts in a given lot. Find the mathematical expectation, variance and standard deviation of a given random variable. Solution. A random variable has a binomial distribution, since the probability that it will take on a value is calculated using the Bernoulli formula. Then its mathematical expectation is found by formula (41), namely, ; variance is found by formula (42): . Then the standard deviation will be equal to . Question. 200 lottery tickets purchased, the probability of winning one ticket is 0.01. Then the average number of lottery tickets that will win is: a) 10; b) 2; in 20; d) 1.
Poisson distribution law
When solving many practical problems, one has to deal with discrete random variables that obey the Poisson distribution law. Typical examples of a random variable with a Poisson distribution are: the number of calls at the telephone exchange for some time ; the number of failures of complex equipment over time, if it is known that the failures are independent of each other and on average there are failures per unit of time. The distribution series will look like:
That is, the probability that a random variable will take a value is calculated by the Poisson formula: therefore, this law is called the Poisson distribution law. A random variable distributed according to the Poisson law has the following numerical characteristics:
The Poisson distribution depends on one parameter, which is the mean of the random variable. Figure 14 shows a general view of the Poisson distribution polygon for various values of the parameter .

The Poisson distribution can be used as an approximation in cases where the exact distribution of a random variable is a binomial distribution, while the number of trials is large, and the probability of an event occurring in a separate trial is small, therefore the Poisson distribution law is called the law of rare events. And also, if the mathematical expectation differs little from the variance, that is, when . In this regard, the Poisson distribution has a large number of different applications. Example 16 The plant sends 500 high-quality products to the base. The probability that the product will be damaged in transit is 0.002. Find the mathematical expectation of the number of parts damaged during transportation. Solution. The random variable has a Poisson distribution, so . Question. The probability of character distortion during message transmission is 0.004. For the average number of garbled symbols to be 4, 100 symbols must be transmitted.
The distribution function of a random variable X is the function F(x), expressing for each x the probability that the random variable X takes the value, smaller x
Example 2.5. Given a series of distribution of a random variable
Find and graphically depict its distribution function. Solution. According to the definition
F(jc) = 0 for X X
F(x) = 0.4 + 0.1 = 0.5 at 4 F(x) = 0.5 + 0.5 = 1 at X > 5.
So (see Fig. 2.1):


Distribution function properties:
1. The distribution function of a random variable is a non-negative function enclosed between zero and one: ![]()
2. The distribution function of a random variable is a non-decreasing function on the entire number axis, i.e. at X 2 >x
![]()
3. At minus infinity, the distribution function is equal to zero, at plus infinity, it is equal to one, i.e.
4. Probability of hitting a random variable X in the interval is equal to the definite integral of its probability density ranging from a before b(see Fig. 2.2), i.e.

Rice. 2.2
3. The distribution function of a continuous random variable (see Fig. 2.3) can be expressed in terms of the probability density using the formula:
F(x)= Jp(*)*. (2.10)
4. Improper integral in infinite limits of the probability density of a continuous random variable is equal to one:
Geometric properties / and 4 probability densities mean that its plot is distribution curve - lies not below the x-axis, and the total area of the figure, limited distribution curve and x-axis, is equal to one.
For a continuous random variable X expected value M(X) and variance D(X) are determined by the formulas:
(if the integral converges absolutely); or 
(if the reduced integrals converge).
Along with the numerical characteristics noted above, the concept of quantiles and percentage points is used to describe a random variable.
q level quantile(or q-quantile) is such a valuex qrandom variable, at which its distribution function takes the value, equal to q, i.e.
- 100The q%-ou point is the quantile X~ q .
- ? Example 2.8.
According to example 2.6 find the quantile xqj and 30% random variable point x.
Solution. By definition (2.16) F(xo t3)= 0.3, i.e.
~Y~ = 0.3, whence the quantile x 0 3 = 0.6. 30% random variable point X, or quantile Х)_о,з = xoj» is found similarly from the equation ^ = 0.7. whence *,= 1.4. ?
Among the numerical characteristics of a random variable, there are initial v* and central R* k-th order moments, determined for discrete and continuous random variables by the formulas:

Definition 3. X has normal distribution law (Gaussian law), if its distribution density has the form:
where m = M(X), σ 2=D(X), σ > 0 .
The normal distribution curve is called normal or gaussian curve(Fig. 6.7).
A normal curve is symmetrical about a straight line x = m, has a maximum at the point x = m, equal .
The distribution function of a random variable X, distributed according to the normal law, is expressed in terms of the Laplace function Ф( X) according to the formula:
F( x) is the Laplace function.
Comment. Function F( X) is odd (Ф(- X) = -Ф( X)), in addition, when X> 5 can be considered F( X) ≈ 1/2.
Table of values of function Ф( X) is given in the appendix (Table P 2.2).
Distribution function plot F(x) is shown in Fig. 6.8.
The probability that a random variable X will take values belonging to the interval ( a;b) are calculated by the formula:
R(a< X < b ) = .
The probability that the absolute value of the deviation of a random variable from its mathematical expectation is less than a positive number δ is calculated by the formula:
P(| X -m| .
In particular, when m=0 the equality is true:
P(| X | .
"Three Sigma Rule"
If the random variable X has a normal distribution law with parameters m and σ, then it is almost certain that its values are contained in the interval ( m 3σ; m+ 3σ), because P(| X -m| = 0,9973.
Problem 6.3. Random value X distributed normally with mean 32 and variance 16. Find: a) probability distribution density f(x); X will take a value from the interval (28;38).
Solution: By condition m= 32, σ 2 = 16, therefore, σ= 4, then
a)
b) Let's use the formula:
R(a< X )= .
Substituting a= 28, b= 38, m= 32, σ= 4, we get
R(28< X < 38)= F(1.5) F(1)
According to the table of values of the function Ф( X) we find Ф(1.5) = 0.4332, Ф(1) = 0.3413.
So the desired probability is:
P(28 Tasks 6.1.
Random value X evenly distributed in the interval (-3;5). Find: a) distribution density f(x);
b) distribution functions F(x);
c) numerical characteristics; d) probability R(4<X<6). 6.2.
Random value X evenly distributed over the segment. Find: a) distribution density f(x);
b) distribution function F(x);
c) numerical characteristics; d) probability R(3≤X≤6). 6.3.
An automatic traffic light is installed on the highway, in which the green light is on for 2 minutes, yellow for 3 seconds and red for 30 seconds, etc. A car is driving down the highway at a random time. Find the probability that the car passes the traffic light without stopping. 6.4.
Subway trains run regularly at intervals of 2 minutes. The passenger enters the platform at a random time. What is the probability that the passenger will have to wait more than 50 seconds for the train? Find the mathematical expectation of a random variable X- train waiting time. 6.5.
Find the variance and standard deviation of the exponential distribution given by the distribution function: 6.6.
Continuous random variable X given by the probability distribution density: a) Name the law of distribution of the considered random variable. b) Find the distribution function F(x) and numerical characteristics of the random variable X. 6.7.
Random value X distributed according to the exponential law, given by the probability distribution density: X will take a value from the interval (2.5;5). 6.8.
Continuous random variable X distributed according to the exponential law given by the distribution function: Find the probability that as a result of the test X will take the value from the interval . 6.9.
The mathematical expectation and standard deviation of a normally distributed random variable are 8 and 2, respectively. Find: a) density distribution f(x); b) the probability that as a result of the test X will take a value from the interval (10;14). 6.10.
Random value X normally distributed with mean 3.5 and variance 0.04. Find: a) distribution density f(x); b) the probability that as a result of the test X will take the value from the interval . 6.11.
Random value X distributed normally with M(X) =
0 and D(X)=
1. Which of the events: | X|≤0.6 or | X|≥0.6 has a high probability? 6.12.
Random value X distributed normally with M(X) =
0 and D(X)=
1. From which interval (-0.5; -0.1) or (1; 2) in one test will it take on a value with a greater probability? 6.13.
The current price per share can be modeled using the normal distribution with M(X)=
10 days units and σ( X) = 0.3 den. units Find: a) the probability that the current share price will be from 9.8 den. units up to 10.4 den. units; b) using the "rule of three sigma" to find the boundaries in which the current price of the stock will be. 6.14.
The substance is weighed without systematic errors. Random weighing errors are subject to the normal law with the standard deviation σ= 5r. Find the probability that in four independent experiments the error in three weighings will not exceed 3 g in absolute value. 6.15.
Random value X distributed normally with M(X)= 12.6. The probability of a random variable falling into the interval (11.4; 13.8) is 0.6826. Find the standard deviation σ. 6.16.
Random value X distributed normally with M(X) = 12 and D(X) = 36. Find the interval in which, with a probability of 0.9973, the random variable will fall as a result of the test X. 6.17.
A part produced by an automatic machine is considered defective if the deviation X its controlled parameter from the nominal value exceeds by modulo 2 units of measurement. It is assumed that the random variable X distributed normally with M(X) = 0 and σ( X) = 0.7. What percentage of defective parts does the machine give out? 3.18.
Parameter X parts are normally distributed with a mathematical expectation of 2 equal to the nominal value and a standard deviation of 0.014. Find the probability that the deviation X from the face value modulo will not exceed 1% of the face value. Answers in) M(X)=1, D(X)=16/3, σ( X)= 4/ , d)1/8. in) M(X)=4,5, D(X) =2 , σ ( X)= , d)3/5. 6.3.
40/51. 6.4.
7/12, M(X)=1. 6.5.
D(X) = 1/64, σ ( X)=1/8 6.6.
M(X)=1 , D(X) =2 , σ ( X)= 1 . 6.7.
P(2.5<X<5)=e -1 e -2 ≈0,2325 6.8.
Р(2≤ X≤5)=0,252. b) R(10 < X < 14) ≈ 0,1574. b) R(3,1 ≤ X ≤ 3,7) ≈ 0,8185. 6.11.
|x|≥0,6. 6.12.
(-0,5; -0,1). 6.13.
a) Р(9.8 ≤ Х ≤ 10.4) ≈ 0.6562 6.14.
0,111. b) (9.1; 10.9). 6.15.
σ = 1.2. 6.16.
(-6; 30). 6.17.
0,4 %. 1.2.4. Random variables and their distributions Distributions of random variables and distribution functions. The distribution of a numerical random variable is a function that uniquely determines the probability that a random variable takes a given value or belongs to some given interval. The first is if the random variable takes on a finite number of values. Then the distribution is given by the function P(X = x), giving each possible value X random variable X the likelihood that X = x. The second is if the random variable takes on infinitely many values. This is possible only when the probability space on which the random variable is defined consists of an infinite number of elementary events. Then the distribution is given by the set of probabilities P(a <
X P(a <
X This relationship shows that just as the distribution can be calculated from the distribution function, so, conversely, the distribution function can be calculated from the distribution. The distribution functions used in probabilistic-statistical decision-making methods and other applied research are either discrete or continuous, or combinations thereof. Discrete distribution functions correspond to discrete random variables that take on a finite number of values or values from a set whose elements can be renumbered by natural numbers (such sets are called countable in mathematics). Their graph looks like a step ladder (Fig. 1). Example 1 Number X of defective items in the batch takes the value 0 with a probability of 0.3, the value 1 with a probability of 0.4, the value 2 with a probability of 0.2 and the value 3 with a probability of 0.1. Graph of the distribution function of a random variable X shown in Fig.1. Fig.1. Graph of the distribution function of the number of defective products. Continuous distribution functions do not have jumps. They increase monotonically as the argument increases, from 0 for to 1 for . Random variables with continuous distribution functions are called continuous. Continuous distribution functions used in probabilistic-statistical decision-making methods have derivatives. First derivative f(x) distribution functions F(x) is called the probability density, The distribution function can be determined from the probability density: For any distribution function The listed properties of distribution functions are constantly used in probabilistic-statistical decision-making methods. In particular, the last equality implies a specific form of the constants in the formulas for the probability densities considered below. Example 2 The following distribution function is often used: where a and b- some numbers a . Let's find the probability density of this distribution function: (at points x = a and x = b function derivative F(x) does not exist). A random variable with distribution function (1) is called "uniformly distributed on the interval [ a; b]». Mixed distribution functions occur, in particular, when observations stop at some point. For example, when analyzing statistical data obtained using reliability test plans that provide for the termination of tests after a certain period of time. Or when analyzing data on technical products that required warranty repairs. Example 3 Let, for example, the service life of an electric light bulb be a random variable with a distribution function F(t), and the test is carried out until the light bulb fails, if this occurs less than 100 hours from the start of the test, or until the moment t0= 100 hours. Let G(t)- distribution function of the operating time of the lamp in good condition in this test. Then Function G(t) has a jump at a point t0, since the corresponding random variable takes the value t0 with probability 1- F(t0)> 0.
Characteristics of random variables. In probabilistic-statistical decision-making methods, a number of characteristics of random variables are used, expressed through distribution functions and probability density. When describing income differentiation, when finding confidence limits for the parameters of distributions of random variables, and in many other cases, such a concept as “order quantile” is used. R", where 0< p < 1 (обозначается x p). Order quantile R is the value of a random variable for which the distribution function takes the value R or there is a "jump" from a value less than R up to a value greater R(Fig. 2). It may happen that this condition is satisfied for all values of x belonging to this interval (i.e., the distribution function is constant on this interval and is equal to R). Then each such value is called a "quantile of the order R". For continuous distribution functions, as a rule, there is a single quantile x p order R(Fig. 2), and F(x p) = p. (2) Fig.2. Definition of a quantile x p order R. Example 4 Let's find the quantile x p order R for the distribution function F(x) from (1). At 0< p <
1 квантиль x p is found from the equation those. x p
= a + p(b – a) = a( 1- p)+bp. At p= 0 any x <
a is the order quantile p= 0. Order quantile p= 1 is any number x >
b. For discrete distributions, as a rule, there is no x p satisfying equation (2). More precisely, if the distribution of a random variable is given in Table 1, where x 1< x 2 < … < x k
, then equality (2), considered as an equation with respect to x p, has solutions only for k values p, namely, p \u003d p 1, p \u003d p 1 + p 2, p \u003d p 1 + p 2 + p 3, p \u003d p 1 + p 2 + ...+
pm, 3 <
m <
k,
p =
p 1
+
p 2
+ … +
p k.
Table 1. Distribution of a discrete random variable For the listed k probability values p solution x p equation (2) is not unique, namely, F(x) = p 1 + p 2 + ... + p m for all X such that x m< x <
xm+1 . Those. x p - any number from the range (x m ; x m+1 ]. For everyone else R from the interval (0;1) not included in the list (3), there is a “jump” from a value less than R up to a value greater R. Namely, if p 1 + p 2 + … + p m then x p \u003d x m + 1. The considered property of discrete distributions creates significant difficulties in tabulating and using such distributions, since it is impossible to accurately maintain the typical numerical values of the distribution characteristics. In particular, this is true for the critical values and significance levels of nonparametric statistical tests (see below), since the distributions of the statistics of these tests are discrete. The order quantile is of great importance in statistics. R= ½. It is called the median (random variable X or its distribution function F(x)) and denoted Me(X). In geometry, there is the concept of "median" - a straight line passing through the vertex of a triangle and dividing its opposite side in half. In mathematical statistics, the median bisects not the side of the triangle, but the distribution of a random variable: equality F(x0.5)= 0.5 means that the probability of getting to the left x0.5 and the probability of getting right x0.5(or directly to x0.5) are equal to each other and equal to ½, i.e. P(X < x 0,5) = P(X >
x 0.5) = ½. The median indicates the "center" of the distribution. From the point of view of one of the modern concepts - the theory of stable statistical procedures - the median is a better characteristic of a random variable than the mathematical expectation. When processing measurement results in an ordinal scale (see the chapter on measurement theory), the median can be used, but the mathematical expectation cannot. Such a characteristic of a random variable as a mode has a clear meaning - the value (or values) of a random variable corresponding to a local maximum of the probability density for a continuous random variable or a local maximum of the probability for a discrete random variable. If a x0 is the mode of a random variable with density f(x), then, as is known from differential calculus, . A random variable can have many modes. So, for uniform distribution (1) each point X such that a< x < b
, is fashion. However, this is an exception. Most of the random variables used in probabilistic-statistical decision-making methods and other applied research have one mode. Random variables, densities, distributions that have one mode are called unimodal. The mathematical expectation for discrete random variables with a finite number of values is considered in the chapter "Events and Probabilities". For a continuous random variable X expected value M(X) satisfies the equality which is an analogue of formula (5) from statement 2 of the chapter "Events and probabilities". Example 5 Mathematical expectation for a uniformly distributed random variable X equals For the random variables considered in this chapter, all those properties of mathematical expectations and variances that were considered earlier for discrete random variables with a finite number of values are true. However, we do not provide proofs of these properties, since they require deepening into mathematical subtleties, which is not necessary for understanding and qualified application of probabilistic-statistical decision-making methods. Comment. In this textbook, mathematical subtleties are deliberately avoided, connected, in particular, with the concepts of measurable sets and measurable functions, the -algebra of events, and so on. Those wishing to master these concepts should refer to the specialized literature, in particular, to the encyclopedia. Each of the three characteristics - mathematical expectation, median, mode - describes the "center" of the probability distribution. The concept of "center" can be defined in different ways - hence the three different characteristics. However, for an important class of distributions - symmetric unimodal - all three characteristics coincide. Distribution density f(x) is the density of the symmetric distribution, if there is a number x 0 such that Equality (3) means that the graph of the function y = f(x) symmetrical about a vertical line passing through the center of symmetry X = X 0 . From (3) it follows that the symmetric distribution function satisfies the relation For a symmetrical distribution with one mode, the mean, median, and mode are the same and equal x 0. The most important case is symmetry with respect to 0, i.e. x 0= 0. Then (3) and (4) become equalities respectively. The above relations show that there is no need to tabulate symmetric distributions for all X, it suffices to have tables for x >
x0. We note one more property of symmetric distributions, which is constantly used in probabilistic-statistical decision-making methods and other applied research. For a continuous distribution function P(|X| <
a) = P(-a <
X <
a) = F(a) – F(-a), where F is the distribution function of the random variable X. If the distribution function F is symmetric with respect to 0, i.e. formula (6) is valid for it, then P(|X| <
a) = 2F(a) – 1.
Another formulation of the statement under consideration is often used: if If and are quantiles of the order and, respectively (see (2)) of a distribution function symmetric with respect to 0, then it follows from (6) that From the characteristics of the position - the mathematical expectation, median, mode - let's move on to the characteristics of the spread of a random variable X: variance , standard deviation and coefficient of variation v. The definition and properties of the variance for discrete random variables were considered in the previous chapter. For continuous random variables The standard deviation is the non-negative value of the square root of the variance: The coefficient of variation is the ratio of the standard deviation to the mathematical expectation: The coefficient of variation is applied when M(X)> 0. It measures the spread in relative units, while the standard deviation is in absolute units. Example 6 For a uniformly distributed random variable X find the variance, standard deviation and coefficient of variation. The dispersion is: Variable substitution makes it possible to write: where c = (b –
a)/
2. Therefore, the standard deviation is equal to and the coefficient of variation is: For every random variable X determine three more quantities - centered Y, normalized V and given U. Centered random variable Y is the difference between the given random variable X and its mathematical expectation M(X), those. Y = X - M(X). Mathematical expectation of a centered random variable Y is equal to 0, and the variance is the variance of the given random variable: M(Y)
= 0, D(Y) =
D(X).
distribution function F Y(x)
centered random variable Y related to the distribution function F(x)
initial random variable X ratio: F Y(x) =
F(x +
M(X)).
For the densities of these random variables, the equality f Y(x) =
f(x +
M(X)).
Normalized random variable V is the ratio of this random variable X to its standard deviation , i.e. . Mathematical expectation and variance of a normalized random variable V expressed through characteristics X So: where v is the coefficient of variation of the original random variable X. For the distribution function F V(x)
and density f V(x)
normalized random variable V we have: where F(x)
is the distribution function of the original random variable X, a f(x)
is its probability density. Reduced random variable U is a centered and normalized random variable: For a reduced random variable Normalized, centered and reduced random variables are constantly used both in theoretical research and in algorithms, software products, regulatory and technical and instructive and methodological documentation. In particular, because the equalities Transformations of random variables and more general plan are used. So if Y = aX + b, where a and b are some numbers, then Example 7 If then Y is the reduced random variable, and formulas (8) are transformed into formulas (7). With every random variable X you can connect a lot of random variables Y given by the formula Y = aX + b at various a>
0 and b.
This set is called scale-shift family, generated by a random variable X. Distribution functions F Y(x)
constitute a scale-shift family of distributions generated by the distribution function F(x).
Instead of Y = aX + b frequently used notation Number With is called the shift parameter, and the number d- scale parameter. Formula (9) shows that X- the result of measuring a certain quantity - goes into At- the result of the measurement of the same value, if the beginning of the measurement is moved to the point With, and then use the new unit of measure, in d times greater than the old one. For the scale-shift family (9), the distribution X is called standard. In probabilistic-statistical decision-making methods and other applied research, the standard normal distribution, the standard Weibull-Gnedenko distribution, the standard gamma distribution, etc. are used (see below). Other transformations of random variables are also used. For example, for a positive random variable X consider Y= log X, where lg X is the decimal logarithm of the number X. Chain of equalities F Y (x) = P( lg X< x) = P(X
< 10x) = F( 10x) relates distribution functions X and Y. When processing data, such characteristics of a random variable are used X like moments of order q, i.e. mathematical expectations of a random variable X q, q= 1, 2, … Thus, the mathematical expectation itself is a moment of order 1. For a discrete random variable, the moment of order q can be calculated as For a continuous random variable Moments of order q also called the initial moments of the order q,
in contrast to related characteristics - the central moments of the order q,
given by the formula Thus, dispersion is a central moment of order 2. Normal distribution and the central limit theorem. In probabilistic-statistical decision-making methods, we often talk about a normal distribution. Sometimes they try to use it to model the distribution of the initial data (these attempts are not always justified - see below). More importantly, many data processing methods are based on the fact that the calculated values have distributions that are close to normal. Let X 1
,
X 2
,…,
X n M(X i) =
m and dispersions D(X i)
= , i
= 1, 2,…, n,… As follows from the results of the previous chapter, Consider the reduced random variable U n for the amount As follows from formulas (7), M(U n)
= 0, D(U n)
= 1. (for identically distributed terms). Let X 1
,
X 2
,…,
X n, … are independent identically distributed random variables with mathematical expectations M(X i) =
m and dispersions D(X i)
= , i
= 1, 2,…, n,… Then for any x there is a limit where F(x) is the standard normal distribution function. More about the function F(x) - below (it reads “fi from x”, because F- Greek capital letter "phi"). The Central Limit Theorem (CLT) takes its name from the fact that it is the central, most frequently used mathematical result of probability theory and mathematical statistics. The history of the CLT takes about 200 years - from 1730, when the English mathematician A. De Moivre (1667-1754) published the first result related to the CLT (see below about the Moivre-Laplace theorem), until the twenties - thirties of the twentieth century, when Finn J.W. Lindeberg, Frenchman Paul Levy (1886-1971), Yugoslav V. Feller (1906-1970), Russian A.Ya. Khinchin (1894-1959) and other scientists obtained necessary and sufficient conditions for the validity of the classical central limit theorem. The development of the subject under consideration did not stop there at all - they studied random variables that do not have dispersion, i.e. those for whom (academician B.V. Gnedenko and others), the situation when random variables (more precisely, random elements) of a more complex nature than numbers are summed up (academicians Yu.V. Prokhorov, A.A. Borovkov and their associates), etc. .d. distribution function F(x) is given by the equality where is the density of the standard normal distribution, which has a rather complicated expression: Here \u003d 3.1415925 ... is a number known in geometry, equal to the ratio of the circumference to the diameter, e
\u003d 2.718281828 ... - the base of natural logarithms (to remember this number, note that 1828 is the year of birth of the writer Leo Tolstoy). As is known from mathematical analysis, When processing the results of observations, the normal distribution function is not calculated according to the above formulas, but is found using special tables or computer programs. The best in Russian “Tables of Mathematical Statistics” were compiled by Corresponding Members of the USSR Academy of Sciences L.N. Bolshev and N.V. Smirnov. The form of the density of the standard normal distribution follows from the mathematical theory, which we cannot consider here, as well as the proof of the CLT. For illustration, we present small tables of the distribution function F(x)(Table 2) and its quantiles (Table 3). Function F(x) is symmetrical with respect to 0, which is reflected in Tables 2-3. Table 2. Function of the standard normal distribution. If the random variable X has a distribution function F(x), then M(X) = 0, D(X)
= 1. This statement is proved in probability theory based on the form of the probability density . It agrees with a similar statement for the characteristics of the reduced random variable U n, which is quite natural, since the CLT states that with an infinite increase in the number of terms, the distribution function U n tends to the standard normal distribution function F(x), and for any X. Table 3 Quantiles of the standard normal distribution. Order quantile R Order quantile R Let us introduce the concept of a family of normal distributions. By definition, a normal distribution is the distribution of a random variable X, for which the distribution of the reduced random variable is F(x). As follows from the general properties of scale-shift families of distributions (see above), the normal distribution is the distribution of a random variable where X is a random variable with distribution F(X), and m =
M(Y),
= D(Y).
Normal distribution with shift parameters m and scale is usually denoted N(m, )
(sometimes the notation N(m, )
). As follows from (8), the probability density of the normal distribution N(m, )
there is Normal distributions form a scale-shift family. In this case, the scale parameter is d= 1/ , and the shift parameter c = -
m/ . For the central moments of the third and fourth order of the normal distribution, the equalities are true These equalities underlie the classical methods of checking that the results of observations follow a normal distribution. At present, normality is usually recommended to be checked by the criterion W Shapiro - Wilka. The normality check problem is discussed below. If random variables X 1 and X 2 have distribution functions N(m 1
, 1)
and N(m 2
, 2)
respectively, then X 1+ X 2 has a distribution has a distribution N(m, )
. These properties of the normal distribution are constantly used in various probabilistic-statistical decision-making methods, in particular, in the statistical control of technological processes and in statistical acceptance control by a quantitative attribute. The normal distribution defines three distributions that are now commonly used in statistical data processing. Distribution (chi - square) - distribution of a random variable where random variables X 1
,
X 2
,…,
X n are independent and have the same distribution N(0.1). In this case, the number of terms, i.e. n, is called the "number of degrees of freedom" of the chi-squared distribution. Distribution t Student is the distribution of a random variable where random variables U and X independent, U has a standard normal distribution N(0,1) and X– distribution chi – square with
n degrees of freedom. Wherein n is called the "number of degrees of freedom" of the Student's distribution. This distribution was introduced in 1908 by the English statistician W. Gosset, who worked at a beer factory. Probabilistic-statistical methods were used to make economic and technical decisions at this factory, so its management forbade V. Gosset to publish scientific articles under his own name. In this way, a trade secret was protected, "know-how" in the form of probabilistic-statistical methods developed by W. Gosset. However, he was able to publish under the pseudonym "Student". The history of Gosset - Student shows that for another hundred years the great economic efficiency of probabilistic-statistical decision-making methods was obvious to British managers. The Fisher distribution is the distribution of a random variable where random variables X 1 and X 2 are independent and have chi distributions - the square with the number of degrees of freedom k 1
and k 2
respectively. At the same time, a couple (k 1
,
k 2
)
is a pair of "numbers of degrees of freedom" of the Fisher distribution, namely, k 1
is the number of degrees of freedom of the numerator, and k 2
is the number of degrees of freedom of the denominator. The distribution of the random variable F is named after the great English statistician R. Fisher (1890-1962), who actively used it in his work. Expressions for the distribution functions of chi - square, Student and Fisher, their densities and characteristics, as well as tables can be found in the special literature (see, for example,). As already noted, normal distributions are currently often used in probabilistic models in various applied fields. Why is this two-parameter family of distributions so widespread? It is clarified by the following theorem. Central limit theorem(for differently distributed terms). Let X 1
,
X 2
,…,
X n,… are independent random variables with mathematical expectations M(X 1
), M(X 2
),…, M(X n), … and dispersions D(X 1
),
D(X 2
),…,
D(X n), … respectively. Let Then, under the validity of certain conditions that ensure the smallness of the contribution of any of the terms to U n, for anyone X. The conditions in question will not be formulated here. They can be found in the specialized literature (see, for example,). "Clarifying the conditions under which the CPT operates is the merit of the outstanding Russian scientists A.A. Markov (1857-1922) and, in particular, A.M. Lyapunov (1857-1918)" . The central limit theorem shows that in the case when the result of measurement (observation) is formed under the influence of many reasons, each of them making only a small contribution, and the cumulative result is determined by additively, i.e. by addition, then the distribution of the measurement (observation) result is close to normal. It is sometimes believed that for the distribution to be normal it is sufficient that the result of the measurement (observation) X formed under the influence of many causes, each of which has a small effect. This is not true. What matters is how these causes work. If additive, then X has an approximately normal distribution. If a multiplicatively(that is, the actions of individual causes are multiplied, not added), then the distribution X not close to normal, but to the so-called. logarithmically normal, i.e. not X, and lg X has an approximately normal distribution. If there are no grounds to believe that one of these two mechanisms for the formation of the final result (or some other well-defined mechanism) is operating, then about the distribution X nothing definite can be said. From what has been said, it follows that in a specific applied problem, the normality of the results of measurements (observations), as a rule, cannot be established from general considerations, it should be checked using statistical criteria. Or use non-parametric statistical methods that are not based on assumptions about the distribution functions of measurement results (observations) belonging to one or another parametric family. Continuous distributions used in probabilistic-statistical decision-making methods. In addition to the scale-shift family of normal distributions, a number of other distribution families are widely used - logarithmically normal, exponential, Weibull-Gnedenko, gamma distributions. Let's take a look at these families. Random value X has a log-normal distribution if the random variable Y= log X has a normal distribution. Then Z=ln X = 2,3026…Y also has a normal distribution
N(a 1
,σ 1), where ln X- natural logarithm X. The density of the log-normal distribution is: It follows from the central limit theorem that the product X =
X 1
X 2
…
X n independent positive random variables X i,
i = 1, 2,…, n, at large n
can be approximated by a log-normal distribution. In particular, the multiplicative model of the formation of wages or income leads to the recommendation to approximate the distributions of wages and incomes by logarithmically normal laws. For Russia, this recommendation turned out to be justified - the statistics confirm it. There are other probabilistic models that lead to the log-normal law. A classical example of such a model is given by A.N. ball mills have a log-normal distribution. Let's move on to another family of distributions, widely used in various probabilistic-statistical decision-making methods and other applied research, the family of exponential distributions. Let's start with a probabilistic model that leads to such distributions. To do this, consider the "stream of events", i.e. a sequence of events occurring one after the other at some point in time. Examples are: call flow at the telephone exchange; the flow of equipment failures in the technological chain; flow of product failures during product testing; the flow of customer requests to the bank branch; the flow of buyers applying for goods and services, etc. In the theory of event flows, a theorem similar to the central limit theorem is valid, but it does not deal with the summation of random variables, but with the summation of event flows. We consider a total flow composed of a large number of independent flows, none of which has a predominant effect on the total flow. For example, the flow of calls arriving at the telephone exchange is made up of a large number of independent call flows originating from individual subscribers. It is proved that in the case when the characteristics of the flows do not depend on time, the total flow is completely described by one number - the intensity of the flow. For the total flow, consider a random variable X- the length of the time interval between successive events. Its distribution function has the form This distribution is called the exponential distribution because formula (10) involves the exponential function e -λ
x. The value 1/λ is a scale parameter. Sometimes a shift parameter is also introduced With, exponential is the distribution of a random variable X + c, where the distribution X is given by formula (10). Exponential distributions are a special case of the so-called. Weibull - Gnedenko distributions. They are named after the engineer W. Weibull, who introduced these distributions into the practice of analyzing the results of fatigue tests, and the mathematician B.V. Gnedenko (1912-1995), who received such distributions as limiting ones when studying the maximum of the test results. Let X- a random variable that characterizes the duration of the operation of a product, complex system, element (i.e. resource, operating time to the limit state, etc.), the duration of the operation of an enterprise or the life of a living being, etc. Failure rate plays an important role where F(x)
and f(x)
- distribution function and density of a random variable X. Let us describe the typical behavior of the failure rate. The entire time interval can be divided into three periods. On the first of them, the function λ(x) has high values and a clear tendency to decrease (most often it decreases monotonically). This can be explained by the presence in the batch under consideration of product units with obvious and latent defects, which lead to a relatively quick failure of these product units. The first period is called the "break-in" (or "break-in") period. This is usually covered by the warranty period. Then comes the period of normal operation, characterized by an approximately constant and relatively low failure rate. The nature of failures during this period is of a sudden nature (accidents, errors of operating personnel, etc.) and does not depend on the duration of operation of a product unit. Finally, the last period of operation is the period of aging and wear. The nature of failures during this period is in irreversible physical, mechanical and chemical changes in materials, leading to a progressive deterioration in the quality of a unit of production and its final failure. Each period has its own type of function λ(x). Consider the class of power dependencies λ(х) = λ0bxb -1
,
(12) where λ 0 >
0 and b> 0 - some numeric parameters. Values b < 1, b= 0 and b> 1 correspond to the type of failure rate during the periods of running-in, normal operation and aging, respectively. Relation (11) for a given failure rate λ(x)- differential equation with respect to the function F(x).
It follows from the theory of differential equations that Substituting (12) into (13), we get that The distribution given by formula (14) is called the Weibull - Gnedenko distribution. Because the then it follows from formula (14) that the quantity a, given by formula (15), is a scaling parameter. Sometimes a shift parameter is also introduced, i.e. Weibull - Gnedenko distribution functions are called F(x - c), where F(x) is given by formula (14) for some λ 0 and b. The density of the Weibull - Gnedenko distribution has the form where a> 0 - scale parameter, b> 0 - form parameter, With- shift parameter. In this case, the parameter a from formula (16) is related to the parameter λ
0 from formula (14) by the ratio indicated in formula (15). The exponential distribution is a very special case of the Weibull - Gnedenko distribution, corresponding to the value of the shape parameter b = 1. The Weibull - Gnedenko distribution is also used in the construction of probabilistic models of situations in which the behavior of an object is determined by the "weakest link". An analogy with a chain is implied, the safety of which is determined by that link that has the lowest strength. In other words, let X 1
,
X 2
,…,
X n are independent identically distributed random variables, X(1)=min( X 1 , X 2 ,…, X n), X(n)=max( X 1 , X 2 ,…, X n). In a number of applied problems, an important role is played by X(1)
and X(n)
, in particular, when studying the maximum possible values ("records") of certain values, for example, insurance payments or losses due to commercial risks, when studying the limits of elasticity and endurance of steel, a number of reliability characteristics, etc. It is shown that for large n the distributions X(1)
and X(n)
, as a rule, are well described by Weibull - Gnedenko distributions. Foundational contributions to the study of distributions X(1)
and X(n)
was introduced by the Soviet mathematician B.V. Gnedenko. The works of V. Weibull, E. Gumbel, V.B. Nevzorova, E.M. Kudlaev and many other specialists. Let's move on to the family of gamma distributions. They are widely used in economics and management, theory and practice of reliability and testing, in various fields of technology, meteorology, etc. In particular, in many situations, the gamma distribution is subject to such quantities as the total service life of the product, the length of the chain of conductive dust particles, the time it takes the product to reach the limit state during corrosion, the operating time up to k th refusal, k= 1, 2, …, etc. The life expectancy of patients with chronic diseases, the time to achieve a certain effect in the treatment in some cases have a gamma distribution. This distribution is the most adequate for describing demand in economic and mathematical models of inventory management (logistics). The density of the gamma distribution has the form The probability density in formula (17) is determined by three parameters a,
b,
c, where a>0, b>0. Wherein a is a form parameter, b- scale parameter and With- shift parameter. Factor 1/Γ(a) is a normalization, it is introduced in order to Here Γ(а)- one of the special functions used in mathematics, the so-called "gamma function", by which the distribution given by formula (17) is also named, At a fixed a formula (17) defines a scale-shift family of distributions generated by a distribution with density The distribution of the form (18) is called the standard gamma distribution. It is obtained from formula (17) with b= 1 and With= 0. A special case of gamma distributions at a= 1 are exponential distributions (with λ = 1/b). With natural a and With=0 gamma distributions are called Erlang distributions. From the works of the Danish scientist K.A. Erlang (1878-1929), an employee of the Copenhagen telephone company, who studied in 1908-1922. the functioning of telephone networks, the development of the theory of queuing began. This theory is engaged in probabilistic-statistical modeling of systems in which the flow of requests is serviced in order to make optimal decisions. Erlang distributions are used in the same application areas as exponential distributions. This is based on the following mathematical fact: the sum of k independent random variables exponentially distributed with the same parameters λ and With, has a gamma distribution with shape parameter a =k, scale parameter b= 1/λ and the shift parameter kc. At With= 0 we get the Erlang distribution. If the random variable X has a gamma distribution with shape parameter a such that d = 2
a- an integer, b= 1 and With= 0, then 2 X has a chi-squared distribution with d degrees of freedom. Random value X with gvmma-distribution has the following characteristics: Expected value M(X) =ab +
c, dispersion D(X) =
σ
2
=
ab 2
, The coefficient of variation asymmetry Excess The normal distribution is an extreme case of the gamma distribution. More precisely, let Z be a random variable with a standard gamma distribution given by formula (18). Then for any real number X, where F(x)- standard normal distribution function N(0,1). In applied research, other parametric families of distributions are also used, of which the Pearson curve system, Edgeworth and Charlier series are the most well-known. They are not considered here. Discrete distributions used in probabilistic-statistical decision-making methods. Most often, three families of discrete distributions are used - binomial, hypergeometric and Poisson, as well as some other families - geometric, negative binomial, multinomial, negative hypergeometric, etc. As already mentioned, the binomial distribution takes place in independent trials, in each of which with a probability R event appears BUT. If the total number of trials n given, then the number of trials Y, in which the event appeared BUT, has a binomial distribution. For a binomial distribution, the probability of being accepted as a random variable Y values y is determined by the formula Number of combinations from n elements by y known from combinatorics. For all y, except for 0, 1, 2, …, n, we have P(Y=
y)=
0. Binomial distribution with a fixed sample size n is set by the parameter p, i.e. binomial distributions form a one-parameter family. They are used in the analysis of sample research data, in particular, in the study of consumer preferences, selective control of product quality according to single-stage control plans, when testing populations of individuals in demography, sociology, medicine, biology, etc. If a Y 1
and Y 2
- independent binomial random variables with the same parameter p 0
determined by samples with volumes n 1
and n 2
respectively, then Y 1
+ Y 2
- binomial random variable with distribution (19) with R = p 0
and n
= n 1
+ n 2
. This remark expands the applicability of the binomial distribution, allowing you to combine the results of several groups of tests, when there is reason to believe that the same parameter corresponds to all these groups. The characteristics of the binomial distribution were calculated earlier: M(Y) =
np,
D(Y) =
np( 1-
p).
In the section "Events and probabilities" for a binomial random variable, the law of large numbers is proved: for anyone . With the help of the central limit theorem, the law of large numbers can be refined by indicating how Y/
n differs from R. De Moivre-Laplace theorem. For any numbers a and
b, a<
b, we have where F(X) is a standard normal distribution function with mean 0 and variance 1. To prove it, it suffices to use the representation Y as a sum of independent random variables corresponding to the outcomes of individual trials, formulas for M(Y)
and D(Y)
and the central limit theorem. This theorem is for the case R= ½ was proved by the English mathematician A. Moivre (1667-1754) in 1730. In the above formulation, it was proved in 1810 by the French mathematician Pierre Simon Laplace (1749-1827). Hypergeometric distribution takes place during selective control of a finite set of objects of volume N according to an alternative feature. Each controlled object is classified either as having the attribute BUT, or as not possessing this feature. The hypergeometric distribution has a random variable Y, equal to the number of objects that have the attribute BUT in a random sample of volume n, where n<
N. For example, number Y defective units of products in a random sample of volume n from batch volume N has a hypergeometric distribution if n<
N.
Another example is the lottery. Let the sign BUT a ticket is a sign of “being winning”. Let all the tickets N,
and some person has acquired n of them. Then the number of winning tickets for this person has a hypergeometric distribution. For a hypergeometric distribution, the probability that a random variable Y takes the value y has the form where D is the number of objects that have the attribute BUT, in the considered set of volume N. Wherein y takes values from max(0, n - (N -
D)) to min( n,
D), with other y the probability in formula (20) is equal to 0. Thus, the hypergeometric distribution is determined by three parameters - the volume of the general population N,
number of objects D in it, possessing the considered feature BUT, and sample size n.
Simple random sampling n from the total volume N is called a sample obtained as a result of random selection, in which any of the sets from n objects has the same probability of being selected. Methods for random selection of samples of respondents (interviewees) or units of piece products are considered in the instructive-methodical and normative-technical documents. One of the selection methods is as follows: objects are selected one from the other, and at each step each of the remaining objects in the set has the same chance of being selected. In the literature, for the type of samples under consideration, the terms “random sample”, “random sample without replacement” are also used. Since the volumes of the general population (lots) N and samples n are commonly known, then the hypergeometric distribution parameter to be estimated is D. In statistical methods of product quality management D- usually the number of defective units in the batch. Of interest is also the characteristic of the distribution D/
N- defect level. For hypergeometric distribution The last factor in the variance expression is close to 1 if N>10
n. If, at the same time, we make the substitution p =
D/
N,
then the expressions for the mathematical expectation and variance of the hypergeometric distribution will turn into expressions for the mathematical expectation and variance of the binomial distribution. This is no coincidence. It can be shown that at N>10
n,
where p =
D/
N.
The limiting ratio is valid and this limiting relation can be used for N>10
n.
The third widely used discrete distribution is the Poisson distribution. A random variable Y has a Poisson distribution if where λ is the Poisson distribution parameter, and P(Y=
y)=
0 for all others y(for y=0, 0!=1 is denoted). For the Poisson distribution M(Y)
= λ, D(Y)
= λ. This distribution is named after the French mathematician C.D. Poisson (1781-1840), who first derived it in 1837. The Poisson distribution is an extreme case of the binomial distribution, where the probability R implementation of the event is small, but the number of trials n great, and np= λ. More precisely, the limit relation Therefore, the Poisson distribution (in the old terminology "distribution law") is often also called the "law of rare events". The Poisson distribution arises in the theory of event flows (see above). It is proved that for the simplest flow with constant intensity Λ, the number of events (calls) that occurred during the time t, has a Poisson distribution with parameter λ = Λ t. Therefore, the probability that in time t no event will occur e -
Λ t, i.e. the distribution function of the length of the interval between events is exponential. The Poisson distribution is used in the analysis of the results of selective marketing surveys of consumers, the calculation of the operational characteristics of statistical acceptance control plans in the case of small values of the acceptance level of defectiveness, to describe the number of breakdowns of a statistically controlled technological process per unit of time, the number of "requirements for service" arriving per unit of time in queuing system, statistical patterns of accidents and rare diseases, etc. The description of other parametric families of discrete distributions and the possibility of their practical use are considered in the literature. In some cases, for example, when studying prices, output volumes or total time between failures in reliability problems, the distribution functions are constant on certain intervals in which the values of the random variables under study cannot fall.![]()
 (1)
(1)


![]()
![]() . (3)
. (3)![]() (4)
(4)![]() (6)
(6)![]() .
.
![]() ,
,![]() .
.![]() make it possible to simplify the substantiation of methods, formulations of theorems, and calculation formulas.
make it possible to simplify the substantiation of methods, formulations of theorems, and calculation formulas.![]()
![]()
![]()
![]() , namely,
, namely,![]()
![]()
![]()
![]() ,
,![]() .
.![]()

![]()
![]() Therefore, if the random variables X 1
,
X 2
,…,
X n N(m, )
, then their arithmetic mean
Therefore, if the random variables X 1
,
X 2
,…,
X n N(m, )
, then their arithmetic mean![]()
![]()

 (10)
(10)![]() (11)
(11) (13)
(13) (14)
(14) (16)
(16) (17)
(17)![]()

 (18)
(18)![]()
![]()
![]()
![]()
![]()

 (20)
(20)
![]() ,
,Previous