กฎการกระจายของตัวแปรสุ่มแบบไม่ต่อเนื่อง ตัวอย่างการแก้ปัญหา
คำจำกัดความ 3เอ็กซ์มี กฎการแจกแจงแบบปกติ (กฎของเกาส์)หากความหนาแน่นของการกระจายมีรูปแบบ:
ที่ไหน ม = ม(เอ็กซ์), σ 2 = ง(เอ็กซ์), σ > 0 .
เรียกว่าเส้นโค้งการแจกแจงแบบปกติ เส้นโค้งปกติหรือเกาส์เซียน(รูปที่ 6.7)
เส้นโค้งปกติมีความสมมาตรเกี่ยวกับเส้นตรง x = มมีค่าสูงสุด ณ จุดนั้น x = ม, เท่ากัน .
ฟังก์ชันการกระจาย ตัวแปรสุ่ม X ซึ่งกระจายตามกฎปกติ จะแสดงผ่านฟังก์ชันลาปลาซ Ф( เอ็กซ์) ตามสูตร:
ฉ( x) – ฟังก์ชันลาปลาซ
ความคิดเห็นฟังก์ชัน Ф( เอ็กซ์) เป็นเลขคี่ (Ф(- เอ็กซ์) = -ฉ( เอ็กซ์)) นอกจากนี้ เมื่อใด เอ็กซ์> 5 ถือได้ว่าเป็น Ф( เอ็กซ์) ≈ 1/2.
ตารางค่าของฟังก์ชัน Ф( เอ็กซ์) ระบุไว้ในภาคผนวก (ตาราง P 2.2)
กราฟฟังก์ชันการกระจาย เอฟ(x) แสดงไว้ในรูปที่ 6.8.
ความน่าจะเป็นที่ตัวแปรสุ่ม X จะใช้ค่าที่อยู่ในช่วงเวลา ( ก;ข) คำนวณโดยสูตร:
ร(ก< เอ็กซ์ < b ) = .
ความน่าจะเป็นที่ค่าสัมบูรณ์ของการเบี่ยงเบนของตัวแปรสุ่มจากมัน ความคาดหวังทางคณิตศาสตร์น้อย จำนวนบวกδ คำนวณโดยใช้สูตร:
ป(| เอ็กซ์ - ม| .
โดยเฉพาะเมื่อ ม=0 ความเท่าเทียมกันเป็นจริง:
ป(| เอ็กซ์ | .
“กฎสามซิกมา”
ถ้าเป็นตัวแปรสุ่ม เอ็กซ์มีกฎการแจกแจงแบบปกติพร้อมพารามิเตอร์ มและ σ เกือบจะแน่นอนว่าค่าของมันอยู่ในช่วงเวลา ( ม 3σ; ม+ 3σ) เนื่องจาก ป(| เอ็กซ์ - ม| = 0,9973.
ปัญหา 6.3ตัวแปรสุ่ม เอ็กซ์มีการแจกแจงตามปกติโดยมีค่าคาดหวังทางคณิตศาสตร์เท่ากับ 32 และความแปรปรวนเท่ากับ 16 ค้นหา: ก) ความหนาแน่นของการแจกแจงความน่าจะเป็น ฉ(x- X จะนำค่าจากช่วงเวลา (28;38)
สารละลาย:ตามเงื่อนไข ม= 32, σ 2 = 16 ดังนั้น σ = 4 ดังนั้น
ก)
b) ลองใช้สูตร:
ร(ก< เอ็กซ์ )= .
การทดแทน ก= 28, ข= 38, ม= 32, σ= 4 เราได้
ร(28< เอ็กซ์ < 38)= ฉ(1.5) ฉ(1)
ตามตารางค่าฟังก์ชัน Φ( เอ็กซ์) เราพบว่า Ф(1,5) = 0.4332, Ф(1) = 0.3413
ดังนั้น ความน่าจะเป็นที่ต้องการ:
ป(28 งาน 6.1.
ตัวแปรสุ่ม เอ็กซ์กระจายอย่างสม่ำเสมอในช่วงเวลา (-3;5) หา: ก) ความหนาแน่นของการกระจาย ฉ(x);
b) ฟังก์ชั่นการกระจาย เอฟ(x);
c) ลักษณะเชิงตัวเลข ง) ความน่าจะเป็น ร(4<เอ็กซ์<6). 6.2.
ตัวแปรสุ่ม เอ็กซ์กระจายอย่างสม่ำเสมอในแต่ละส่วน หา: ก) ความหนาแน่นของการกระจาย ฉ(x);
b) ฟังก์ชั่นการกระจาย เอฟ(x);
c) ลักษณะเชิงตัวเลข ง) ความน่าจะเป็น ร(3≤เอ็กซ์≤6). 6.3.
มีไฟจราจรอัตโนมัติบนทางหลวง โดยเปิดไฟเขียว 2 นาที สีเหลือง 3 วินาที สีแดง 30 วินาที เป็นต้น รถยนต์แล่นไปตามทางหลวงในช่วงเวลาสุ่ม จงหาความน่าจะเป็นที่รถจะผ่านสัญญาณไฟจราจรโดยไม่หยุด 6.4.
รถไฟใต้ดินวิ่งเป็นประจำทุกๆ 2 นาที ผู้โดยสารเข้าสู่ชานชาลาในเวลาสุ่ม ความน่าจะเป็นที่ผู้โดยสารต้องรอรถไฟนานกว่า 50 วินาทีเป็นเท่าใด ค้นหาความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่ม เอ็กซ์- เวลารอรถไฟ 6.5.
ค้นหาความแปรปรวนและส่วนเบี่ยงเบนมาตรฐานของการแจกแจงแบบเอ็กซ์โปเนนเชียลที่กำหนดโดยฟังก์ชันการแจกแจง: 6.6.
ตัวแปรสุ่มต่อเนื่อง เอ็กซ์กำหนดโดยความหนาแน่นของการแจกแจงความน่าจะเป็น: ก) ตั้งชื่อกฎการกระจายของตัวแปรสุ่มที่กำลังพิจารณา b) ค้นหาฟังก์ชันการแจกแจง เอฟ(x) และคุณลักษณะเชิงตัวเลขของตัวแปรสุ่ม เอ็กซ์. 6.7.
ตัวแปรสุ่ม เอ็กซ์กระจายตามกฎเลขชี้กำลังที่ระบุโดยความหนาแน่นของการแจกแจงความน่าจะเป็น: เอ็กซ์จะนำค่าจากช่วงเวลา (2.5;5) 6.8.
ตัวแปรสุ่มต่อเนื่อง เอ็กซ์กระจายตามกฎเลขชี้กำลังที่ระบุโดยฟังก์ชันการแจกแจง: ค้นหาความน่าจะเป็นที่เป็นผลจากการทดสอบ เอ็กซ์จะนำค่าจากส่วนนั้น 6.9.
ค่าคาดหวังและค่าเบี่ยงเบนมาตรฐานของตัวแปรสุ่มแบบกระจายปกติคือ 8 และ 2 ตามลำดับ ค้นหา: ก) ความหนาแน่น การแจกแจงฉ(x); b) ความน่าจะเป็นที่เกิดจากการทดสอบ เอ็กซ์จะนำค่าจากช่วงเวลา (10;14) 6.10.
ตัวแปรสุ่ม เอ็กซ์กระจายตามปกติโดยมีค่าคาดหวังทางคณิตศาสตร์ 3.5 และความแปรปรวน 0.04 หา: ก) ความหนาแน่นของการกระจาย ฉ(x); b) ความน่าจะเป็นที่เกิดจากการทดสอบ เอ็กซ์จะนำค่าจากส่วนนั้น 6.11.
ตัวแปรสุ่ม เอ็กซ์ปกติจะแจกกับ ม(เอ็กซ์) =
0 และ ดี(เอ็กซ์)=
1. เหตุการณ์ใด: | เอ็กซ์|≤0.6 หรือ | เอ็กซ์|≥0.6มีแนวโน้มมากขึ้นใช่ไหม? 6.12.
ตัวแปรสุ่ม เอ็กซ์ปกติจะแจกกับ ม(เอ็กซ์) =
0 และ ดี(เอ็กซ์)=
1. จากช่วงเวลาใด (-0.5; -0.1) หรือ (1; 2) มีแนวโน้มที่จะรับค่าระหว่างการทดสอบหนึ่งครั้งมากกว่าหรือไม่ 6.13.
ราคาปัจจุบันต่อหุ้นสามารถจำลองได้โดยใช้การแจกแจงแบบปกติด้วย ม(เอ็กซ์)=
10 วัน หน่วย และ σ( เอ็กซ์) = 0.3 เด็น หน่วย หา: ก) ความน่าจะเป็นที่ราคาหุ้นปัจจุบันจะอยู่ที่ 9.8 Den หน่วย สูงสุด 10.4 วัน หน่วย; b) ใช้ "กฎสามซิกมา" ค้นหาขอบเขตที่ราคาหุ้นปัจจุบันจะเป็น 6.14.
ชั่งน้ำหนักสารโดยไม่มีข้อผิดพลาดอย่างเป็นระบบ ข้อผิดพลาดในการชั่งน้ำหนักแบบสุ่มจะขึ้นอยู่กับกฎปกติโดยมีค่าเบี่ยงเบนมาตรฐาน σ= 5g ค้นหาความน่าจะเป็นที่ในการทดลองอิสระสี่ครั้ง ข้อผิดพลาดในการชั่งน้ำหนักสามครั้งจะไม่เกิน 3 กรัมในค่าสัมบูรณ์ 6.15.
ตัวแปรสุ่ม เอ็กซ์ปกติจะแจกกับ ม(เอ็กซ์)= 12.6. ความน่าจะเป็นที่ตัวแปรสุ่มจะตกอยู่ในช่วง (11.4; 13.8) คือ 0.6826 ค้นหาค่าเบี่ยงเบนมาตรฐาน σ 6.16.
ตัวแปรสุ่ม เอ็กซ์ปกติจะแจกกับ ม(เอ็กซ์) = 12 และ ดี(เอ็กซ์) = 36 ค้นหาช่วงเวลาที่ด้วยความน่าจะเป็น 0.9973 ตัวแปรสุ่มจะลดลงอันเป็นผลมาจากการทดสอบ เอ็กซ์. 6.17.
ชิ้นส่วนที่ผลิตโดยเครื่องจักรอัตโนมัติถือว่ามีข้อบกพร่องหากเบี่ยงเบน เอ็กซ์พารามิเตอร์ที่ควบคุมนั้นเกินค่าที่กำหนด 2 หน่วยการวัด สันนิษฐานว่าเป็นตัวแปรสุ่ม เอ็กซ์ปกติจะแจกกับ ม(เอ็กซ์) = 0 และ σ( เอ็กซ์) = 0.7 เครื่องจักรผลิตชิ้นส่วนที่ชำรุดกี่เปอร์เซ็นต์? 3.18.
พารามิเตอร์ เอ็กซ์ชิ้นส่วนต่างๆ มีการกระจายตามปกติโดยมีค่าคาดหวังทางคณิตศาสตร์เท่ากับ 2 เท่ากับค่าที่ระบุและค่าเบี่ยงเบนมาตรฐานเท่ากับ 0.014 จงหาความน่าจะเป็นที่ส่วนเบี่ยงเบน เอ็กซ์ของมูลค่าระบุจะต้องไม่เกิน 1% ของมูลค่าระบุ คำตอบ วี) ม(เอ็กซ์)=1, ดี(เอ็กซ์)=16/3, σ( เอ็กซ์)= 4/ , ง)1/8. วี) ม(เอ็กซ์)=4,5, ดี(เอ็กซ์) =2 , σ ( เอ็กซ์)= , ง)3/5. 6.3.
40/51. 6.4.
7/12, ม(เอ็กซ์)=1. 6.5.
ดี(เอ็กซ์) = 1/64, σ ( เอ็กซ์)=1/8 6.6.
ม(เอ็กซ์)=1 , ดี(เอ็กซ์) =2 , σ ( เอ็กซ์)= 1 . 6.7.
พี(2.5<เอ็กซ์<5)=จ -1 จ -2 ≈0,2325 6.8.
ป(2≤ เอ็กซ์≤5)=0,252. ข) ร(10 < เอ็กซ์ < 14) ≈ 0,1574. ข) ร(3,1 ≤ เอ็กซ์ ≤ 3,7) ≈ 0,8185. 6.11.
|x|≥0,6. 6.12.
(-0,5; -0,1). 6.13.
ก) P(9.8 ≤ X ≤ 10.4) data 0.6562 6.14.
0,111. ข) (9.1; 10.9) 6.15.
ซิ = 1.2 6.16.
(-6; 30). 6.17.
0,4 %. – จำนวนเด็กผู้ชายในจำนวนทารกแรกเกิด 10 คน เป็นที่ชัดเจนอย่างยิ่งว่าไม่ทราบจำนวนนี้ล่วงหน้า และเด็ก 10 คนถัดไปที่เกิดอาจรวมถึง: หรือเด็กผู้ชาย - หนึ่งเดียวเท่านั้นจากตัวเลือกที่แสดงไว้ และเพื่อรักษารูปร่างให้มีการพลศึกษาเล็กน้อย: – ระยะกระโดดไกล (ในบางยูนิต). แม้แต่ผู้เชี่ยวชาญด้านกีฬาก็ไม่สามารถคาดเดาได้ :) อย่างไรก็ตาม สมมติฐานของคุณ? 2) ตัวแปรสุ่มต่อเนื่อง – ยอมรับ ทั้งหมดค่าตัวเลขจากช่วงจำกัดหรือช่วงอนันต์ บันทึก
: ตัวย่อ DSV และ NSV เป็นที่นิยมในวรรณกรรมทางการศึกษา ก่อนอื่น เรามาวิเคราะห์ตัวแปรสุ่มแบบไม่ต่อเนื่องกันก่อน จากนั้น - อย่างต่อเนื่อง. - นี้ การโต้ตอบระหว่างค่าที่เป็นไปได้ของปริมาณนี้และความน่าจะเป็น บ่อยครั้งที่กฎหมายเขียนไว้ในตาราง: และตอนนี้ จุดสำคัญมาก: เนื่องจากเป็นตัวแปรสุ่ม จำเป็นจะยอมรับ หนึ่งในค่านิยมจากนั้นเหตุการณ์ที่เกี่ยวข้องจะเกิดขึ้น เต็มกลุ่มและผลรวมของความน่าจะเป็นของการเกิดขึ้นมีค่าเท่ากับหนึ่ง: หรือถ้าเขียนย่อ: ตัวอย่างเช่น กฎการกระจายความน่าจะเป็นของแต้มที่ทอยบนลูกเต๋ามีรูปแบบดังนี้: ไม่มีความคิดเห็น คุณอาจรู้สึกว่าตัวแปรสุ่มแบบแยกสามารถรับเฉพาะค่าจำนวนเต็ม "ดี" เท่านั้น มาปัดเป่าภาพลวงตา - พวกมันสามารถเป็นอะไรก็ได้: ตัวอย่างที่ 1 เกมบางเกมมีกฎการจำหน่ายที่ชนะดังต่อไปนี้: ...คุณคงฝันถึงงานแบบนี้มานานแล้ว :) ฉันจะบอกความลับกับคุณ - ฉันก็เหมือนกัน โดยเฉพาะหลังจากที่ฉันทำงานเสร็จแล้ว ทฤษฎีภาคสนาม. สารละลาย: เนื่องจากตัวแปรสุ่มสามารถรับค่าได้เพียงค่าเดียวจากสามค่า เหตุการณ์จึงจะเกิดขึ้น เต็มกลุ่มซึ่งหมายความว่าผลรวมของความน่าจะเป็นมีค่าเท่ากับหนึ่ง: การเปิดเผย "พรรคพวก": การควบคุม: นั่นคือสิ่งที่เราต้องทำให้แน่ใจ คำตอบ: ไม่ใช่เรื่องแปลกเมื่อคุณจำเป็นต้องร่างกฎหมายการจำหน่ายด้วยตัวเอง สำหรับสิ่งนี้พวกเขาใช้ คำจำกัดความคลาสสิกของความน่าจะเป็น, ทฤษฎีบทการคูณ/การบวกสำหรับความน่าจะเป็นของเหตุการณ์และชิปอื่นๆ เทอร์เวรา: ตัวอย่างที่ 2 ในกล่องประกอบด้วยตั๋วลอตเตอรี 50 ใบ โดย 12 ใบถูกรางวัล และ 2 ใบในนั้นถูกรางวัลละ 1,000 รูเบิล และที่เหลือใบละ 100 รูเบิล ร่างกฎหมายสำหรับการแจกแจงตัวแปรสุ่ม - ขนาดของเงินรางวัลหากมีการสุ่มตั๋วหนึ่งใบจากกล่อง สารละลาย: อย่างที่คุณสังเกต ค่าของตัวแปรสุ่มมักจะถูกวางไว้ในนั้น ตามลำดับจากน้อยไปหามาก- ดังนั้นเราจึงเริ่มต้นด้วยเงินรางวัลที่น้อยที่สุดนั่นคือรูเบิล มีตั๋วทั้งหมด 50 ใบ - 12 = 38 และตาม คำจำกัดความแบบคลาสสิก: ในกรณีอื่นๆ ทุกอย่างก็เรียบง่าย ความน่าจะเป็นที่จะชนะรูเบิลคือ: ตรวจสอบ: – และนี่เป็นช่วงเวลาที่น่ายินดีอย่างยิ่งของงานดังกล่าว! คำตอบ: กฎการกระจายเงินรางวัลที่ต้องการ: งานต่อไปนี้ให้คุณแก้ไขด้วยตัวเอง: ตัวอย่างที่ 3 ความน่าจะเป็นที่ผู้ยิงจะโดนเป้าหมายคือ ร่างกฎการกระจายสำหรับตัวแปรสุ่ม - จำนวนการเข้าชมหลังจาก 2 ช็อต ...ฉันรู้ว่าเธอคิดถึงเขา :) จำไว้นะ ทฤษฎีบทการคูณและการบวก- คำตอบและคำตอบอยู่ท้ายบทเรียน กฎการกระจายอธิบายตัวแปรสุ่มอย่างสมบูรณ์ แต่ในทางปฏิบัติ อาจมีประโยชน์ (และบางครั้งก็มีประโยชน์มากกว่า) ที่รู้เพียงบางส่วนเท่านั้น ลักษณะเชิงตัวเลข
. พูดง่ายๆ ก็คือ นี่คือ มูลค่าที่คาดหวังโดยเฉลี่ยเมื่อทำการทดสอบซ้ำหลายครั้ง ให้ตัวแปรสุ่มนำค่าที่มีความน่าจะเป็น หรือยุบ: ให้เราคำนวณความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่ม - จำนวนคะแนนที่กลิ้งบนลูกเต๋า: ตอนนี้เรามาจำเกมสมมุติของเรา: คำถามเกิดขึ้น: การเล่นเกมนี้มีกำไรหรือไม่? ...ใครมีความประทับใจบ้าง? ดังนั้นคุณไม่สามารถพูดว่า "ตรงไปตรงมา" ได้! แต่คำถามนี้สามารถตอบได้อย่างง่ายดายโดยการคำนวณความคาดหวังทางคณิตศาสตร์ โดยพื้นฐานแล้ว - ถัวเฉลี่ยถ่วงน้ำหนักตามความน่าจะเป็นที่จะชนะ: ดังนั้นความคาดหวังทางคณิตศาสตร์ของเกมนี้ การสูญเสีย. อย่าเชื่อความประทับใจของคุณ - เชื่อตัวเลข! ใช่ ที่นี่คุณสามารถชนะ 10 หรือ 20-30 ครั้งติดต่อกัน แต่ในระยะยาว ความหายนะที่หลีกเลี่ยงไม่ได้รอเราอยู่ และฉันจะไม่แนะนำให้คุณเล่นเกมประเภทนี้ :) อาจจะเท่านั้น เพื่อความสนุกสนาน. จากที่กล่าวมาทั้งหมด เป็นไปตามที่คาดหวังทางคณิตศาสตร์ไม่ใช่ค่าสุ่มอีกต่อไป งานสร้างสรรค์เพื่อการวิจัยอิสระ: ตัวอย่างที่ 4 Mr. X เล่นรูเล็ตยุโรปโดยใช้ระบบต่อไปนี้: เขาเดิมพัน 100 รูเบิลกับ "สีแดง" อย่างต่อเนื่อง ร่างกฎการกระจายของตัวแปรสุ่ม - เงินรางวัล คำนวณความคาดหวังทางคณิตศาสตร์ของการชนะและปัดเศษให้เป็น kopeck ที่ใกล้ที่สุด เท่าไหร่ โดยเฉลี่ยผู้เล่นเสียเงินเดิมพันทุก ๆ ร้อยหรือไม่? อ้างอิง
: ยูโรเปียนรูเล็ตประกอบด้วย 18 สีแดง 18 สีดำ และ 1 สีเขียว (“ศูนย์”) หาก "สีแดง" ปรากฏขึ้น ผู้เล่นจะได้รับเงินเดิมพันสองเท่า มิฉะนั้นจะตกเป็นรายได้ของคาสิโน มีระบบรูเล็ตอื่นๆ อีกมากมายที่คุณสามารถสร้างตารางความน่าจะเป็นของคุณเองได้ แต่ในกรณีนี้คือเมื่อเราไม่ต้องการกฎการแจกแจงหรือตารางใดๆ เนื่องจากมีการกำหนดไว้แล้วว่าความคาดหวังทางคณิตศาสตร์ของผู้เล่นจะเหมือนกันทุกประการ สิ่งเดียวที่เปลี่ยนจากระบบหนึ่งไปอีกระบบหนึ่งคือ 1.2.4. ตัวแปรสุ่มและการแจกแจงของตัวแปรสุ่ม การแจกแจงตัวแปรสุ่มและฟังก์ชันการแจกแจง- การแจกแจงของตัวแปรสุ่มเชิงตัวเลขคือฟังก์ชันที่กำหนดความน่าจะเป็นที่ตัวแปรสุ่มจะใช้ค่าที่กำหนดหรืออยู่ในช่วงที่กำหนดโดยเฉพาะ ประการแรกคือถ้าตัวแปรสุ่มรับค่าจำนวนจำกัด จากนั้นการแจกแจงจะได้รับจากฟังก์ชัน ป(X = x)การกำหนดให้กับแต่ละค่าที่เป็นไปได้ เอ็กซ์ตัวแปรสุ่ม เอ็กซ์ความน่าจะเป็นนั้น เอ็กซ์ = x. ประการที่สองคือถ้าตัวแปรสุ่มรับค่าจำนวนอนันต์ สิ่งนี้เป็นไปได้ก็ต่อเมื่อปริภูมิความน่าจะเป็นที่กำหนดตัวแปรสุ่มนั้นประกอบด้วยเหตุการณ์พื้นฐานจำนวนอนันต์ จากนั้นการแจกแจงจะได้มาจากเซตของความน่าจะเป็น ป(ก <
เอ็กซ์ ป(ก <
เอ็กซ์ ความสัมพันธ์นี้แสดงให้เห็นว่าการแจกแจงทั้งสองสามารถคำนวณได้จากฟังก์ชันการแจกแจง และในทางกลับกัน ฟังก์ชันการแจกแจงสามารถคำนวณได้จากการแจกแจง ใช้ในความน่าจะเป็น วิธีการทางสถิติการตัดสินใจและอื่น ๆ การวิจัยประยุกต์ฟังก์ชันการกระจายเป็นแบบแยกหรือต่อเนื่อง หรือรวมกัน ฟังก์ชันการแจกแจงแบบแยกส่วนสอดคล้องกับตัวแปรสุ่มแบบแยกซึ่งรับค่าหรือค่าจำนวนจำกัดจากชุดที่องค์ประกอบสามารถกำหนดหมายเลขด้วยจำนวนธรรมชาติได้ (ชุดดังกล่าวเรียกว่านับได้ในทางคณิตศาสตร์) กราฟของพวกเขาดูเหมือนบันไดขั้นบันได (รูปที่ 1) ตัวอย่างที่ 1ตัวเลข เอ็กซ์สินค้าที่มีข้อบกพร่องในชุดจะใช้ค่า 0 ด้วยความน่าจะเป็น 0.3 ค่า 1 ด้วยความน่าจะเป็น 0.4 ค่า 2 ด้วยความน่าจะเป็น 0.2 และค่า 3 ด้วยความน่าจะเป็น 0.1 กราฟฟังก์ชันการกระจายของตัวแปรสุ่ม เอ็กซ์แสดงในรูปที่ 1 รูปที่ 1. กราฟแสดงฟังก์ชันการกระจายจำนวนสินค้าที่มีข้อบกพร่อง ฟังก์ชันการกระจายแบบต่อเนื่องไม่มีการข้าม พวกเขาเพิ่มขึ้นแบบซ้ำซากจำเจเมื่ออาร์กิวเมนต์เพิ่มขึ้น - จาก 0 เป็น 1 ที่ ตัวแปรสุ่มที่มีฟังก์ชันการแจกแจงต่อเนื่องเรียกว่าตัวแปรต่อเนื่อง ฟังก์ชันการแจกแจงต่อเนื่องที่ใช้ในวิธีการตัดสินใจทางสถิติความน่าจะเป็นมีอนุพันธ์ อนุพันธ์อันดับหนึ่ง ฉ(x)ฟังก์ชั่นการกระจาย ฉ(x)เรียกว่าความหนาแน่นของความน่าจะเป็น เมื่อใช้ความหนาแน่นของความน่าจะเป็น คุณสามารถกำหนดฟังก์ชันการแจกแจงได้: สำหรับฟังก์ชันการกระจายใดๆ คุณสมบัติที่ระบุไว้ของฟังก์ชันการแจกแจงจะใช้อย่างต่อเนื่องในวิธีการตัดสินใจความน่าจะเป็นและทางสถิติ โดยเฉพาะอย่างยิ่ง ความเท่าเทียมกันสุดท้ายแสดงถึงรูปแบบเฉพาะของค่าคงที่ในสูตรสำหรับความหนาแน่นของความน่าจะเป็นที่พิจารณาด้านล่าง ตัวอย่างที่ 2มักใช้ฟังก์ชันการกระจายต่อไปนี้: ที่ไหน กและ ข– ตัวเลขบางตัว ก - มาหาความหนาแน่นของความน่าจะเป็นของฟังก์ชันการแจกแจงนี้: ( ณ จุด x = กและ x = ขอนุพันธ์ของฟังก์ชัน ฉ(x)ไม่มีอยู่) ตัวแปรสุ่มที่มีฟังก์ชันการกระจาย (1) เรียกว่า “กระจายสม่ำเสมอในช่วงเวลา [ ก; ข]». ฟังก์ชันการกระจายแบบผสมจะเกิดขึ้น โดยเฉพาะอย่างยิ่ง เมื่อการสังเกตหยุดที่จุดใดจุดหนึ่ง ตัวอย่างเช่น เมื่อวิเคราะห์ข้อมูลทางสถิติที่ได้จากการใช้แผนการทดสอบความน่าเชื่อถือที่จัดให้มีการยกเลิกการทดสอบหลังจากช่วงระยะเวลาหนึ่ง หรือเมื่อวิเคราะห์ข้อมูลเกี่ยวกับผลิตภัณฑ์ด้านเทคนิคที่ต้องซ่อมแซมตามการรับประกัน ตัวอย่างที่ 3ตัวอย่างเช่น สมมติว่าอายุการใช้งานของหลอดไฟเป็นตัวแปรสุ่มพร้อมกับฟังก์ชันการกระจาย ฉ(ท)และทำการทดสอบจนกว่าหลอดไฟจะเสียถ้าเกิดขึ้นภายในเวลาไม่ถึง 100 ชั่วโมงนับแต่เริ่มการทดสอบ หรือจนกว่า เสื้อ 0= 100 ชม. อนุญาต ก(ที)– ฟังก์ชันการกระจายเวลาการทำงานของหลอดไฟในสภาพดีระหว่างการทดสอบนี้ แล้ว การทำงาน ก(ที)มีการกระโดดถึงจุดหนึ่ง เสื้อ 0เนื่องจากตัวแปรสุ่มที่สอดคล้องกันรับค่า เสื้อ 0ด้วยความน่าจะเป็น 1- F(เสื้อ 0)> 0.
ลักษณะของตัวแปรสุ่มในวิธีการตัดสินใจทางสถิติความน่าจะเป็น มีการใช้คุณลักษณะจำนวนหนึ่งของตัวแปรสุ่ม ซึ่งแสดงผ่านฟังก์ชันการแจกแจงและความหนาแน่นของความน่าจะเป็น เมื่ออธิบายความแตกต่างของรายได้ เมื่อค้นหาขีดจำกัดความเชื่อมั่นสำหรับพารามิเตอร์ของการแจกแจงของตัวแปรสุ่ม และในกรณีอื่นๆ จำนวนมาก จะใช้แนวคิดเช่น "ลำดับควอนไทล์" ร" โดยที่ 0< พี < 1 (обозначается เอ็กซ์พี- สั่งซื้อควอนไทล์ ร– ค่าของตัวแปรสุ่มที่ฟังก์ชันการแจกแจงรับค่า รหรือมี “การกระโดด” จากค่าที่น้อยกว่า รให้มีค่ามากขึ้น ร(รูปที่ 2) อาจเกิดขึ้นได้ว่าเงื่อนไขนี้เป็นไปตามค่า x ทั้งหมดที่อยู่ในช่วงเวลานี้ (เช่น ฟังก์ชันการแจกแจงคงที่ในช่วงเวลานี้และเท่ากับ ร- จากนั้นแต่ละค่าดังกล่าวจะเรียกว่า "ปริมาณการสั่งซื้อ" ร- สำหรับฟังก์ชันการแจกแจงแบบต่อเนื่อง ตามกฎแล้วจะมีควอไทล์เดียว เอ็กซ์พีคำสั่ง ร(รูปที่ 2) และ ฉ(x พี) = พี. (2) รูปที่ 2. ความหมายของควอนไทล์ เอ็กซ์พีคำสั่ง ร. ตัวอย่างที่ 4มาหาควอไทล์กันดีกว่า เอ็กซ์พีคำสั่ง รสำหรับฟังก์ชันการกระจาย ฉ(x)จาก (1) เวลา 0< พี <
1 квантиль เอ็กซ์พีหาได้จากสมการ เหล่านั้น. เอ็กซ์พี
= ก + พี(ข – ก) = ก( 1- น) +bp- ที่ พี= 0 ใดๆ x <
กเป็นปริมาณของการสั่งซื้อ พี= 0. ปริมาณการสั่งซื้อ พี= 1 คือตัวเลขใดๆ x >
ข. สำหรับการแจกแจงแบบแยกส่วน ตามกฎแล้วไม่มี เอ็กซ์พี, สมการที่น่าพอใจ (2) แม่นยำยิ่งขึ้นหากได้รับการกระจายของตัวแปรสุ่มในตารางที่ 1 โดยที่ x1< x 2 < … < x k
แล้วความเท่าเทียมกัน (2) ถือเป็นสมการเทียบกับ เอ็กซ์พีมีวิธีแก้ปัญหาเฉพาะสำหรับ เคค่านิยม พีกล่าวคือ พี = พี 1 , พี = พี 1 + พี 2 , พี = พี 1 + พี 2 + พี 3 , พี = พี 1 + พี 2 + …+
บ่ายโมง, 3 <
ม <
เค,
พี =
พี 1
+
พี 2
+ … +
พีเค.
ตารางที่ 1. การกระจายตัวของตัวแปรสุ่มแบบไม่ต่อเนื่อง สำหรับผู้ที่อยู่ในรายการ เคค่าความน่าจะเป็น พีสารละลาย เอ็กซ์พีสมการ (2) ไม่ซ้ำกัน กล่าวคือ ฉ(x) = หน้า 1 + หน้า 2 + … + หน้า ม สำหรับทุกคน เอ็กซ์เช่นนั้น x ม< x <
x ม+1 .เหล่านั้น. เอ็กซ์พี –หมายเลขใดๆ จากช่วงเวลา (x ม.; x ม.+1 ].สำหรับคนอื่นๆ รจากช่วงเวลา (0;1) ซึ่งไม่รวมอยู่ในรายการ (3) จะมี "การกระโดด" จากค่าที่น้อยกว่า รให้มีค่ามากขึ้น ร- กล่าวคือถ้า พี 1 + พี 2 + … + พี ม ที่ x พี = x ม.+1. คุณสมบัติที่พิจารณาของการแจกแจงแบบไม่ต่อเนื่องทำให้เกิดปัญหาอย่างมากเมื่อทำการจัดตารางและใช้การแจกแจงดังกล่าวเนื่องจากเป็นไปไม่ได้ที่จะรักษาค่าตัวเลขทั่วไปของลักษณะการแจกแจงอย่างแม่นยำ โดยเฉพาะอย่างยิ่งสิ่งนี้เป็นจริงสำหรับค่าวิกฤตและระดับนัยสำคัญของการทดสอบทางสถิติแบบไม่อิงพารามิเตอร์ (ดูด้านล่าง) เนื่องจากการแจกแจงสถิติของการทดสอบเหล่านี้ไม่ต่อเนื่องกัน ลำดับเชิงปริมาณมีความสำคัญอย่างยิ่งในสถิติ ร= ½. เรียกว่า ค่ามัธยฐาน (ตัวแปรสุ่ม) เอ็กซ์หรือฟังก์ชันการกระจายของมัน เอฟ(เอ็กซ์))และถูกกำหนดไว้ ฉัน(เอ็กซ์)ในเรขาคณิต มีแนวคิดเรื่อง "ค่ามัธยฐาน" ซึ่งเป็นเส้นตรงที่ลากผ่านจุดยอดของรูปสามเหลี่ยมและแบ่งด้านตรงข้ามออกเป็นสองส่วน ในสถิติทางคณิตศาสตร์ ค่ามัธยฐานจะแบ่งครึ่งหนึ่งไม่ใช่ด้านข้างของสามเหลี่ยม แต่เป็นการแจกแจงของตัวแปรสุ่ม: ความเท่าเทียมกัน ฉ(x 0.5)= 0.5 หมายถึง ความน่าจะเป็นที่จะไปทางซ้าย x0.5และความน่าจะเป็นที่จะไปทางขวา x0.5(หรือโดยตรงที่ x0.5) เท่ากันและเท่ากับ ½ นั่นคือ ป(เอ็กซ์ < x 0,5) = ป(เอ็กซ์ >
x 0.5) = ½ ค่ามัธยฐานหมายถึง "ศูนย์กลาง" ของการแจกแจง จากมุมมองของหนึ่งในแนวคิดสมัยใหม่ - ทฤษฎีของขั้นตอนทางสถิติที่เสถียร - ค่ามัธยฐานเป็นคุณลักษณะที่ดีกว่าของตัวแปรสุ่มมากกว่าที่คาดหวังทางคณิตศาสตร์ เมื่อประมวลผลผลการวัดในระดับลำดับ (ดูบทเกี่ยวกับทฤษฎีการวัด) สามารถใช้ค่ามัธยฐานได้ แต่ความคาดหวังทางคณิตศาสตร์ไม่สามารถใช้ได้ คุณลักษณะของตัวแปรสุ่ม เช่น โหมด มีความหมายที่ชัดเจน - ค่า (หรือค่า) ของตัวแปรสุ่มที่สอดคล้องกับค่าสูงสุดเฉพาะของความหนาแน่นของความน่าจะเป็นสำหรับตัวแปรสุ่มแบบต่อเนื่อง หรือค่าสูงสุดเฉพาะของความน่าจะเป็นสำหรับตัวแปรสุ่มแบบแยกส่วน . ถ้า x 0– โหมดของตัวแปรสุ่มที่มีความหนาแน่น ฉ(x)จากนั้น ดังที่ทราบจากแคลคูลัสเชิงอนุพันธ์ . ตัวแปรสุ่มสามารถมีได้หลายโหมด ดังนั้นสำหรับการกระจายสม่ำเสมอ (1) แต่ละจุด เอ็กซ์เช่นนั้น ก< x < b
คือแฟชั่น อย่างไรก็ตาม นี่เป็นข้อยกเว้น ตัวแปรสุ่มส่วนใหญ่ที่ใช้ในวิธีทางสถิติความน่าจะเป็นในการตัดสินใจและการวิจัยประยุกต์อื่นๆ มีรูปแบบเดียว ตัวแปรสุ่ม ความหนาแน่น การแจกแจงที่มีโหมดเดียวเรียกว่า ยูนิโมดัล เอ็กซ์ความคาดหวังทางคณิตศาสตร์สำหรับตัวแปรสุ่มแบบแยกส่วนที่มีค่าจำนวนจำกัดจะกล่าวถึงในบท “เหตุการณ์และความน่าจะเป็น” สำหรับตัวแปรสุ่มต่อเนื่อง ความคาดหวังทางคณิตศาสตร์เอ็ม(เอ็กซ์) ตอบสนองความเท่าเทียมกัน ซึ่งเป็นความคล้ายคลึงของสูตร (5) จากข้อความที่ 2 ของบท “เหตุการณ์และความน่าจะเป็น”ตัวอย่างที่ 5 เอ็กซ์ความคาดหวังของตัวแปรสุ่มแบบกระจายสม่ำเสมอ สำหรับตัวแปรสุ่มที่พิจารณาในบทนี้ คุณสมบัติทั้งหมดของความคาดหวังและความแปรปรวนทางคณิตศาสตร์ที่พิจารณาก่อนหน้านี้สำหรับตัวแปรสุ่มแบบไม่ต่อเนื่องที่มีค่าจำนวนจำกัดจะเป็นจริง อย่างไรก็ตาม เราไม่ได้ให้ข้อพิสูจน์เกี่ยวกับคุณสมบัติเหล่านี้ เนื่องจากคุณสมบัติเหล่านี้ต้องมีการลงลึกในรายละเอียดปลีกย่อยทางคณิตศาสตร์ ซึ่งไม่จำเป็นสำหรับการทำความเข้าใจและการประยุกต์ใช้วิธีการตัดสินใจทางสถิติความน่าจะเป็นและสถิติที่เหมาะสม ความคิดเห็นหนังสือเรียนเล่มนี้หลีกเลี่ยงความละเอียดอ่อนทางคณิตศาสตร์ที่เกี่ยวข้องกับแนวคิดของเซตที่วัดได้และฟังก์ชันที่วัดได้ พีชคณิตของเหตุการณ์ ฯลฯ อย่างมีสติ ผู้ที่ต้องการเชี่ยวชาญแนวคิดเหล่านี้ควรหันไปหาวรรณกรรมเฉพาะทาง โดยเฉพาะสารานุกรม ลักษณะเฉพาะทั้งสามประการ ได้แก่ ความคาดหวังทางคณิตศาสตร์ ค่ามัธยฐาน โหมด อธิบายถึง "จุดศูนย์กลาง" ของการแจกแจงความน่าจะเป็น แนวคิดของ "ศูนย์กลาง" สามารถกำหนดได้หลายวิธี - จึงมีคุณลักษณะที่แตกต่างกันสามประการ อย่างไรก็ตาม สำหรับคลาสของการแจกแจงที่สำคัญ—แบบสมมาตรเดียว—ทั้งสามลักษณะจะเหมือนกัน ความหนาแน่นของการกระจาย ฉ(x)– ความหนาแน่นของการแจกแจงแบบสมมาตร ถ้ามีตัวเลข x 0เช่นนั้น ความเท่าเทียมกัน (3) หมายความว่ากราฟของฟังก์ชัน ย = ฉ(x)สมมาตรเกี่ยวกับเส้นแนวตั้งที่ลากผ่านจุดศูนย์กลางสมมาตร เอ็กซ์ = เอ็กซ์ 0 . จาก (3) เป็นไปตามที่ฟังก์ชันการแจกแจงแบบสมมาตรเป็นไปตามความสัมพันธ์ สำหรับการแจกแจงแบบสมมาตรด้วยโหมดเดียว ค่าคาดหวังทางคณิตศาสตร์ ค่ามัธยฐาน และโหมดจะตรงกันและเท่ากัน x 0. กรณีที่สำคัญที่สุดคือสมมาตรประมาณ 0 เช่น x 0= 0 จากนั้น (3) และ (4) จึงเท่ากัน ตามลำดับ ความสัมพันธ์ข้างต้นแสดงให้เห็นว่าไม่จำเป็นต้องจัดตารางการแจกแจงแบบสมมาตรสำหรับทุกคน เอ็กซ์ก็เพียงพอที่จะมีโต๊ะที่ x >
x 0. ขอให้เราสังเกตคุณสมบัติอีกอย่างหนึ่งของการแจกแจงแบบสมมาตร ซึ่งใช้อย่างต่อเนื่องในวิธีการตัดสินใจทางสถิติความน่าจะเป็นและการวิจัยประยุกต์อื่นๆ สำหรับฟังก์ชันการกระจายต่อเนื่อง ป(|X| <
ก) = พี(-ก <
เอ็กซ์ <
ก) = F(ก) – F(-a) ที่ไหน เอฟ– ฟังก์ชันการกระจายของตัวแปรสุ่ม เอ็กซ์- ถ้าฟังก์ชันการกระจาย เอฟมีความสมมาตรประมาณ 0 นั่นคือ สูตร (6) ก็ใช้ได้สำหรับมันแล้ว ป(|X| <
ก) = 2F(ก) – 1.
มักใช้รูปแบบอื่นของข้อความที่เป็นปัญหา: ถ้า ถ้า และ เป็นปริมาณของลำดับ และตามลำดับ (ดู (2)) ของฟังก์ชันการแจกแจงแบบสมมาตรประมาณ 0 จากนั้นจาก (6) จะได้ว่า จากลักษณะของตำแหน่ง - ความคาดหวังทางคณิตศาสตร์, ค่ามัธยฐาน, โหมด - มาดูคุณสมบัติของการแพร่กระจายของตัวแปรสุ่มกัน เอ็กซ์: ความแปรปรวน ส่วนเบี่ยงเบนมาตรฐาน และสัมประสิทธิ์ของการแปรผัน โวลต์- คำจำกัดความและคุณสมบัติของการกระจายตัวของตัวแปรสุ่มแบบไม่ต่อเนื่องได้ถูกกล่าวถึงในบทที่แล้ว สำหรับตัวแปรสุ่มต่อเนื่อง ค่าเบี่ยงเบนมาตรฐานคือค่าที่ไม่เป็นลบของรากที่สองของความแปรปรวน: ค่าสัมประสิทธิ์ของการแปรผันคืออัตราส่วนของค่าเบี่ยงเบนมาตรฐานต่อค่าคาดหวังทางคณิตศาสตร์: ค่าสัมประสิทธิ์ของการแปรผันจะใช้เมื่อ เอ็ม(เอ็กซ์)> 0. วัดค่าสเปรดในหน่วยสัมพัทธ์ ในขณะที่ค่าเบี่ยงเบนมาตรฐานอยู่ในหน่วยสัมบูรณ์ ตัวอย่างที่ 6สำหรับตัวแปรสุ่มแบบกระจายสม่ำเสมอ เอ็กซ์ลองหาการกระจายตัว ส่วนเบี่ยงเบนมาตรฐาน และสัมประสิทธิ์ของการแปรผัน ความแปรปรวนคือ: การเปลี่ยนตัวแปรทำให้สามารถเขียนได้: ที่ไหน ค = (ข –
ก)/
2. ดังนั้น ค่าเบี่ยงเบนมาตรฐานจึงเท่ากับ และค่าสัมประสิทธิ์ของการแปรผันคือ: สำหรับตัวแปรสุ่มแต่ละตัว เอ็กซ์กำหนดปริมาณอีกสามปริมาณ - อยู่ตรงกลาง ยทำให้เป็นมาตรฐาน วีและมอบให้ คุณ- ตัวแปรสุ่มแบบตั้งศูนย์กลาง ยคือความแตกต่างระหว่างตัวแปรสุ่มที่กำหนด เอ็กซ์และความคาดหวังทางคณิตศาสตร์ของมัน ม(เอ็กซ์)เหล่านั้น. ย = X – ม(X)ความคาดหวังของตัวแปรสุ่มที่มีศูนย์กลาง ยเท่ากับ 0 และความแปรปรวนคือความแปรปรวนของตัวแปรสุ่มที่กำหนด: ม(ย)
= 0, ดี(ย) =
ดี(เอ็กซ์).
ฟังก์ชันการกระจาย เอฟ วาย(x)
ตัวแปรสุ่มแบบกึ่งกลาง ยที่เกี่ยวข้องกับฟังก์ชันการกระจาย เอฟ(x)
ตัวแปรสุ่มดั้งเดิม เอ็กซ์อัตราส่วน: เอฟ วาย(x) =
เอฟ(x +
ม(เอ็กซ์)).
ความหนาแน่นของตัวแปรสุ่มเหล่านี้เป็นไปตามความเท่าเทียมกัน ฉ(x) =
ฉ(x +
ม(เอ็กซ์)).
ตัวแปรสุ่มที่ทำให้เป็นมาตรฐาน วีคืออัตราส่วนของตัวแปรสุ่มที่กำหนด เอ็กซ์ถึงค่าเบี่ยงเบนมาตรฐาน เช่น - ความคาดหวังและความแปรปรวนของตัวแปรสุ่มที่ทำให้เป็นมาตรฐาน วีแสดงออกผ่านลักษณะเฉพาะ เอ็กซ์ดังนั้น: ที่ไหน โวลต์– สัมประสิทธิ์ของการแปรผันของตัวแปรสุ่มดั้งเดิม เอ็กซ์- สำหรับฟังก์ชันการกระจาย เอฟ วี(x)
และความหนาแน่น ฉ วี(x)
ตัวแปรสุ่มที่ทำให้เป็นมาตรฐาน วีเรามี: ที่ไหน เอฟ(x)
– ฟังก์ชันการกระจายของตัวแปรสุ่มดั้งเดิม เอ็กซ์, ก ฉ(x)
– ความหนาแน่นของความน่าจะเป็น ตัวแปรสุ่มลดลง คุณเป็นตัวแปรสุ่มแบบกึ่งกลางและแบบมาตรฐาน: สำหรับตัวแปรสุ่มที่กำหนด ตัวแปรสุ่มที่ทำให้เป็นมาตรฐาน ศูนย์กลาง และลดลงจะถูกใช้อย่างต่อเนื่องทั้งในการศึกษาเชิงทฤษฎีและในอัลกอริธึม ผลิตภัณฑ์ซอฟต์แวร์ เอกสารด้านกฎระเบียบ เทคนิค และการเรียนการสอน โดยเฉพาะเพราะความเท่าเทียมกัน มีการใช้การแปลงตัวแปรสุ่มและตัวแปรทั่วไป ถ้าอย่างนั้น ย = ขวาน + ข, ที่ไหน กและ ข– ตัวเลขบางส่วนแล้ว ตัวอย่างที่ 7ถ้าอย่างนั้น ยคือตัวแปรสุ่มแบบรีดิวซ์ และสูตร (8) เปลี่ยนเป็นสูตร (7) โดยมีตัวแปรสุ่มแต่ละตัว เอ็กซ์คุณสามารถเชื่อมโยงตัวแปรสุ่มได้หลายตัว ยกำหนดโดยสูตร ย = ขวาน + ขที่แตกต่างกัน ก>
0 และ ข.
ชุดนี้มีชื่อว่า ครอบครัวที่เปลี่ยนขนาดสร้างโดยตัวแปรสุ่ม เอ็กซ์- ฟังก์ชันการกระจาย เอฟ วาย(x)
ประกอบด้วยกลุ่มการแจกแจงแบบเลื่อนขนาดที่สร้างขึ้นโดยฟังก์ชันการแจกแจง เอฟ(x).
แทน ย = ขวาน + ขมักใช้การบันทึก ตัวเลข กับเรียกว่าพารามิเตอร์ shift และตัวเลข ง- พารามิเตอร์มาตราส่วน สูตร (9) แสดงว่า เอ็กซ์– ผลลัพธ์ของการวัดปริมาณหนึ่ง – เข้าสู่ คุณ– ผลลัพธ์ของการวัดปริมาณเท่ากันหากจุดเริ่มต้นของการวัดถูกย้ายไปยังจุด กับแล้วใช้หน่วยวัดใหม่เข้า งใหญ่กว่าอันเก่าหลายเท่า สำหรับตระกูลสเกลกะ (9) การแจกแจงของ X เรียกว่ามาตรฐาน ในวิธีการทางสถิติความน่าจะเป็นในการตัดสินใจและการวิจัยประยุกต์อื่นๆ จะใช้การแจกแจงแบบปกติมาตรฐาน การแจกแจงแบบ Weibull-Gnedenko แบบมาตรฐาน การแจกแจงแกมมามาตรฐาน ฯลฯ (ดูด้านล่าง) การแปลงตัวแปรสุ่มแบบอื่นๆ ก็ใช้เช่นกัน ตัวอย่างเช่น สำหรับตัวแปรสุ่มเชิงบวก เอ็กซ์กำลังพิจารณา ย= บันทึก เอ็กซ์ที่ไหนแอลจี เอ็กซ์– ลอการิทึมทศนิยมของตัวเลข เอ็กซ์- ห่วงโซ่แห่งความเท่าเทียมกัน ปี (x) = P(แอลจี เอ็กซ์< x) = P(X
< 10x) = ฉ( 10เอ็กซ์) เชื่อมต่อฟังก์ชันการกระจาย เอ็กซ์และ ย. เมื่อประมวลผลข้อมูล จะใช้คุณลักษณะต่อไปนี้ของตัวแปรสุ่ม เอ็กซ์เป็นช่วงเวลาแห่งการสั่งซื้อ ถาม, เช่น. ความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่ม เอ็กซ์คิว, ถาม= 1, 2, ... ดังนั้น ความคาดหวังทางคณิตศาสตร์ก็คือโมเมนต์ของลำดับ 1 สำหรับตัวแปรสุ่มแบบไม่ต่อเนื่อง โมเมนต์ของลำดับ ถามสามารถคำนวณได้เป็น สำหรับตัวแปรสุ่มต่อเนื่อง ช่วงเวลาของการสั่งซื้อ ถามเรียกอีกอย่างว่าช่วงเวลาเริ่มต้นของการสั่งซื้อ ถาม,
ตรงกันข้ามกับลักษณะที่เกี่ยวข้อง - ช่วงเวลาสำคัญของการสั่งซื้อ ถาม,
กำหนดโดยสูตร ดังนั้น การกระจายตัวจึงเป็นช่วงเวลาสำคัญของลำดับที่ 2 การแจกแจงแบบปกติและทฤษฎีบทขีดจำกัดกลางในวิธีการตัดสินใจทางสถิติความน่าจะเป็น เรามักพูดถึงการแจกแจงแบบปกติ บางครั้งพวกเขาพยายามใช้มันเพื่อสร้างแบบจำลองการกระจายข้อมูลเริ่มต้น (ความพยายามเหล่านี้ไม่ได้มีเหตุผลเสมอไป - ดูด้านล่าง) ที่สำคัญกว่านั้นวิธีการประมวลผลข้อมูลหลายวิธีนั้นขึ้นอยู่กับความจริงที่ว่าค่าที่คำนวณได้นั้นมีการกระจายที่ใกล้เคียงกับปกติ อนุญาต เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็น ม(เอ็กซ์ ฉัน) =
มและความแปรปรวน ดี(เอ็กซ์ ฉัน)
= , ฉัน
= 1, 2,…, n,... ดังนี้จากผลของบทที่แล้ว พิจารณาตัวแปรสุ่มรีดิวซ์ คุณสำหรับจำนวนเงิน ดังต่อไปนี้จากสูตร (7) ม(คุณ)
= 0, ดี(คุณ)
= 1. (สำหรับเงื่อนไขที่กระจายเหมือนกัน) อนุญาต เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็น, … – ตัวแปรสุ่มที่แจกแจงอย่างเป็นอิสระเหมือนกันพร้อมความคาดหวังทางคณิตศาสตร์ ม(เอ็กซ์ ฉัน) =
มและความแปรปรวน ดี(เอ็กซ์ ฉัน)
= , ฉัน
= 1, 2,…, n,... ดังนั้นสำหรับ x ใดๆ จะมีขีดจำกัด ที่ไหน ฉ(x)– ฟังก์ชันของการแจกแจงแบบปกติมาตรฐาน ข้อมูลเพิ่มเติมเกี่ยวกับคุณลักษณะนี้ ฉ(x) –ด้านล่าง (อ่านว่า “phi จาก x” เพราะ เอฟ- อักษรกรีกตัวพิมพ์ใหญ่ "phi") ทฤษฎีบทขีดจำกัดกลาง (CLT) ได้ชื่อมาเนื่องจากเป็นผลทางคณิตศาสตร์ส่วนกลางที่ใช้กันมากที่สุดของทฤษฎีความน่าจะเป็นและสถิติทางคณิตศาสตร์ ประวัติความเป็นมาของ CLT ใช้เวลาประมาณ 200 ปี - ตั้งแต่ปี 1730 เมื่อนักคณิตศาสตร์ชาวอังกฤษ A. Moivre (1667-1754) ตีพิมพ์ผลลัพธ์แรกที่เกี่ยวข้องกับ CLT (ดูด้านล่างเกี่ยวกับทฤษฎีบท Moivre-Laplace) จนถึงช่วงทศวรรษที่ 20 และ 30 ศตวรรษที่ 20 เมื่อ Finn J.W. Lindeberg, ชาวฝรั่งเศส Paul Levy (2429-2514), ยูโกสลาเวีย V. Feller (2449-2513), รัสเซีย A.Ya. Khinchin (1894-1959) และนักวิทยาศาสตร์คนอื่นๆ ได้รับเงื่อนไขที่จำเป็นและเพียงพอสำหรับความถูกต้องของทฤษฎีบทขีดจำกัดกลางแบบคลาสสิก การพัฒนาหัวข้อที่อยู่ระหว่างการพิจารณาไม่ได้หยุดอยู่แค่นั้น - พวกเขาศึกษาตัวแปรสุ่มที่ไม่มีการกระจายตัวเช่น เหล่านั้นเพื่อใคร (นักวิชาการ B.V. Gnedenko และคนอื่น ๆ ) สถานการณ์เมื่อมีการสรุปตัวแปรสุ่ม (องค์ประกอบสุ่มที่แม่นยำยิ่งขึ้น) ที่มีลักษณะที่ซับซ้อนมากกว่าตัวเลข (นักวิชาการ Yu.V. Prokhorov, A.A. Borovkov และผู้ร่วมงาน) ฯลฯ .d. ฟังก์ชันการกระจาย ฉ(x)จะได้รับจากความเท่าเทียมกัน โดยที่ความหนาแน่นของการแจกแจงแบบปกติมาตรฐานซึ่งมีการแสดงออกค่อนข้างซับซ้อน: โดยที่ =3.1415925… เป็นตัวเลขที่รู้จักในเรขาคณิต ซึ่งเท่ากับอัตราส่วนของเส้นรอบวงต่อเส้นผ่านศูนย์กลาง จ
= 2.718281828... - ฐานของลอการิทึมธรรมชาติ (โปรดจำตัวเลขนี้ โปรดทราบว่า 1828 เป็นปีเกิดของนักเขียน L.N. Tolstoy) ดังที่ทราบจากการวิเคราะห์ทางคณิตศาสตร์ เมื่อประมวลผลผลการสังเกต ฟังก์ชันการแจกแจงแบบปกติจะไม่คำนวณโดยใช้สูตรที่กำหนด แต่พบได้โดยใช้ตารางพิเศษหรือโปรแกรมคอมพิวเตอร์ "ตารางสถิติทางคณิตศาสตร์" ที่ดีที่สุดในรัสเซียรวบรวมโดยสมาชิกของ USSR Academy of Sciences L.N. Bolshev และ N.V. Smirnov รูปแบบของความหนาแน่นของการแจกแจงแบบปกติมาตรฐานเป็นไปตามทฤษฎีทางคณิตศาสตร์ ซึ่งเราไม่สามารถพิจารณาได้ในที่นี้ เช่นเดียวกับการพิสูจน์ของ CLT เพื่อเป็นตัวอย่าง เรามีตารางเล็กๆ ของฟังก์ชันการแจกแจง ฉ(x)(ตารางที่ 2) และปริมาณของมัน (ตารางที่ 3) การทำงาน ฉ(x)สมมาตรประมาณ 0 ซึ่งสะท้อนอยู่ในตารางที่ 2-3 ตารางที่ 2. ฟังก์ชันการแจกแจงแบบปกติมาตรฐาน ถ้าเป็นตัวแปรสุ่ม เอ็กซ์มีฟังก์ชั่นการกระจาย ฉ(x)ที่ ความคาดหวังทางคณิตศาสตร์ = 0, ดี(เอ็กซ์)
= 1 ข้อความนี้ได้รับการพิสูจน์แล้วในทฤษฎีความน่าจะเป็นโดยพิจารณาจากรูปแบบของความหนาแน่นของความน่าจะเป็น ซึ่งสอดคล้องกับข้อความที่คล้ายกันสำหรับคุณลักษณะของตัวแปรสุ่มแบบรีดิวซ์ คุณซึ่งค่อนข้างเป็นธรรมชาติ เนื่องจาก CLT ระบุว่าฟังก์ชันการแจกแจงมีจำนวนเพิ่มขึ้นไม่จำกัด คุณมีแนวโน้มที่จะใช้ฟังก์ชันการแจกแจงแบบปกติมาตรฐาน ฉ(x)และเพื่ออะไรก็ตาม เอ็กซ์. ตารางที่ 3. ปริมาณของการแจกแจงแบบปกติมาตรฐาน สั่งซื้อควอนไทล์ ร สั่งซื้อควอนไทล์ ร ให้เราแนะนำแนวคิดเรื่องตระกูลของการแจกแจงแบบปกติ ตามคำนิยาม การแจกแจงแบบปกติคือการแจกแจงของตัวแปรสุ่ม เอ็กซ์ซึ่งการกระจายตัวของตัวแปรสุ่มแบบรีดิวซ์คือ ฉ(x)ดังต่อไปนี้จากคุณสมบัติทั่วไปของตระกูลการแจกแจงแบบเลื่อนระดับ (ดูด้านบน) การแจกแจงแบบปกติคือการแจกแจงของตัวแปรสุ่ม ที่ไหน เอ็กซ์– ตัวแปรสุ่มพร้อมการแจกแจง เอฟ(เอ็กซ์)และ ม =
ม(ย),
= ดี(ย).
การกระจายแบบปกติด้วยพารามิเตอร์การเปลี่ยนแปลง มและมักจะระบุขนาดไว้ เอ็น(ม, )
(บางครั้งใช้สัญกรณ์ เอ็น(ม, )
). ดังต่อไปนี้จาก (8) ความหนาแน่นของความน่าจะเป็นของการแจกแจงแบบปกติ เอ็น(ม, )
มี การแจกแจงแบบปกติก่อให้เกิดตระกูลการเปลี่ยนขนาด ในกรณีนี้ พารามิเตอร์มาตราส่วนคือ ง= 1/ และพารามิเตอร์ shift ค = -
ม/ . สำหรับโมเมนต์กลางของการแจกแจงแบบปกติลำดับที่สามและสี่ ความเท่าเทียมกันต่อไปนี้ใช้ได้: ความเท่าเทียมกันเหล่านี้เป็นพื้นฐานของวิธีการดั้งเดิมในการตรวจสอบว่าการสังเกตเป็นไปตามการแจกแจงแบบปกติ ปัจจุบันมักแนะนำให้ทดสอบภาวะปกติโดยใช้เกณฑ์ วชาปิโร - วิลก้า ปัญหาของการทดสอบภาวะปกติมีดังต่อไปนี้ ถ้าเป็นตัวแปรสุ่ม เอ็กซ์ 1และ เอ็กซ์ 2มีฟังก์ชั่นการกระจาย เอ็น(ม 1
, 1)
และ เอ็น(ม 2
, 2)
ตามนั้น เอ็กซ์ 1+ เอ็กซ์ 2มีการกระจาย มีการกระจาย เอ็น(ม, )
- คุณสมบัติของการแจกแจงแบบปกติเหล่านี้ถูกนำมาใช้อย่างต่อเนื่องในวิธีการตัดสินใจเชิงความน่าจะเป็นและทางสถิติต่างๆ โดยเฉพาะอย่างยิ่งในการควบคุมทางสถิติของกระบวนการทางเทคโนโลยีและในการควบคุมการยอมรับทางสถิติตามเกณฑ์เชิงปริมาณ เมื่อใช้การแจกแจงแบบปกติ การแจกแจงสามแบบถูกกำหนดไว้ซึ่งปัจจุบันมักใช้ในการประมวลผลข้อมูลทางสถิติ การแจกแจง (ไค - สแควร์) – การแจกแจงของตัวแปรสุ่ม ตัวแปรสุ่มอยู่ที่ไหน เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็นเป็นอิสระและมีการกระจายตัวเหมือนกัน เอ็น(0,1) ในกรณีนี้จำนวนเทอมคือ nเรียกว่า “จำนวนองศาอิสระ” ของการแจกแจงแบบไคสแควร์ การกระจาย ที t ของนักเรียนคือการแจกแจงของตัวแปรสุ่ม ตัวแปรสุ่มอยู่ที่ไหน คุณและ เอ็กซ์เป็นอิสระ, คุณมีการแจกแจงแบบปกติมาตรฐาน เอ็น(0.1) และ เอ็กซ์– การกระจายไค – กำลังสอง c
nระดับความเป็นอิสระ ในเวลาเดียวกัน nเรียกว่า “จำนวนองศาอิสระ” ของการแจกแจงนักศึกษา การจำหน่ายนี้เปิดตัวในปี 1908 โดยนักสถิติชาวอังกฤษ W. Gosset ซึ่งทำงานในโรงงานเบียร์แห่งหนึ่ง โรงงานแห่งนี้ใช้วิธีการความน่าจะเป็นและสถิติในการตัดสินใจทางเศรษฐกิจและทางเทคนิค ดังนั้นฝ่ายบริหารจึงห้ามไม่ให้ V. Gosset เผยแพร่บทความทางวิทยาศาสตร์ภายใต้ชื่อของเขาเอง ด้วยวิธีนี้ ความลับทางการค้าและ "ความรู้" ในรูปแบบของวิธีการความน่าจะเป็นและสถิติที่พัฒนาโดย V. Gosset ได้รับการปกป้อง อย่างไรก็ตามเขาได้มีโอกาสตีพิมพ์โดยใช้นามแฝงว่า "นักศึกษา" ประวัติความเป็นมาของ Gosset-Student แสดงให้เห็นว่าเป็นเวลากว่าร้อยปีที่ผู้จัดการในสหราชอาณาจักรตระหนักถึงประสิทธิภาพทางเศรษฐกิจที่มากขึ้นของวิธีการตัดสินใจเชิงสถิติความน่าจะเป็น ตัวแปรสุ่มอยู่ที่ไหน เอ็กซ์ 1และ เอ็กซ์ 2การแจกแจงแบบฟิชเชอร์คือการแจกแจงของตัวแปรสุ่ม เค 1
และ เค 2
มีความเป็นอิสระและมีการแจกแจงแบบไคสแควร์ด้วยจำนวนดีกรีอิสระ (เค 1
,
เค 2
)
ตามลำดับ ขณะเดียวกันทั้งคู่ เค 1
– คู่ “องศาอิสระ” ของการแจกแจงแบบฟิชเชอร์ กล่าวคือ เค 2
คือจำนวนองศาอิสระของตัวเศษ และ – จำนวนดีกรีอิสระของตัวส่วน การแจกแจงของตัวแปรสุ่ม F ได้รับการตั้งชื่อตามนักสถิติชาวอังกฤษผู้ยิ่งใหญ่ อาร์. ฟิชเชอร์ (พ.ศ. 2433-2505) ซึ่งใช้ตัวแปรสุ่มนี้ในงานของเขาอย่างแข็งขัน นิพจน์สำหรับฟังก์ชันการแจกแจงไคสแควร์ ฟังก์ชันการแจกแจงแบบ Student และ Fisher ความหนาแน่นและคุณลักษณะ ตลอดจนตารางสามารถพบได้ในเอกสารเฉพาะทาง (ดูตัวอย่าง) ดังที่ได้กล่าวไปแล้ว การแจกแจงแบบปกติมักใช้ในแบบจำลองความน่าจะเป็นในด้านต่างๆ ที่นำไปใช้ อะไรคือสาเหตุของการแจกแจงตระกูลสองพารามิเตอร์นี้ที่แพร่หลายมาก?มันถูกชี้แจงโดยทฤษฎีบทต่อไปนี้ เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็นทฤษฎีบทขีดจำกัดกลาง ม(เอ็กซ์ 1
(สำหรับข้อกำหนดที่มีการกระจายต่างกัน) อนุญาตเอ็กซ์ 2
,… - ตัวแปรสุ่มอิสระพร้อมความคาดหวังทางคณิตศาสตร์เอ็กซ์), ม( ดี(เอ็กซ์ 1
),
ดี(เอ็กซ์ 2
),…,
ดี(เอ็กซ์),…, ม( n), ... และความแปรปรวน คุณ, น) ... ตามลำดับ อนุญาต เอ็กซ์. จากนั้น หากเงื่อนไขบางประการเป็นจริงซึ่งรับประกันการมีส่วนร่วมเล็กน้อยของข้อกำหนดใดๆ ใน ทฤษฎีบทขีดจำกัดกลางแสดงให้เห็นว่าในกรณีที่ผลลัพธ์ของการวัด (การสังเกต) เกิดขึ้นภายใต้อิทธิพลของสาเหตุหลายประการ แต่ละสาเหตุมีส่วนช่วยเพียงเล็กน้อยเท่านั้น และผลลัพธ์ทั้งหมดจะถูกกำหนด นอกจากนี้, เช่น. นอกจากนี้แล้วการกระจายตัวของผลการวัด (การสังเกต) ก็ใกล้เคียงกับปกติ บางครั้งเชื่อกันว่าเพื่อให้การกระจายตัวเป็นปกติก็เพียงพอแล้วที่ผลการวัด (การสังเกต) เอ็กซ์เกิดขึ้นภายใต้อิทธิพลของหลายสาเหตุ ซึ่งแต่ละเหตุผลก็มีผลกระทบเพียงเล็กน้อย นี่เป็นสิ่งที่ผิด สิ่งที่สำคัญคือสาเหตุเหล่านี้ทำงานอย่างไร ถ้าเสริมแล้ว เอ็กซ์มีการกระจายตัวแบบปกติโดยประมาณ ถ้า คูณ(เช่น การกระทำของแต่ละสาเหตุจะถูกคูณและไม่บวก) จากนั้นจึงเป็นการกระจาย เอ็กซ์ใกล้ไม่ปกติ แต่เป็นสิ่งที่เรียกว่า ลอการิทึมปกติเช่น ไม่ เอ็กซ์และบันทึก X มีการแจกแจงแบบปกติโดยประมาณ เอ็กซ์หากไม่มีเหตุผลที่จะเชื่อว่าหนึ่งในสองกลไกในการสร้างผลลัพธ์สุดท้ายนั้นอยู่ที่ทำงาน (หรือกลไกอื่น ๆ ที่กำหนดไว้อย่างดี) จากนั้นจึงเกี่ยวกับการกระจาย ไม่มีอะไรแน่นอนสามารถพูดได้ จากที่กล่าวมาข้างต้นว่าตามกฎแล้วไม่สามารถกำหนดความเป็นปกติของผลการวัด (การสังเกต) จากการพิจารณาทั่วไปได้ ดังนั้น ควรตรวจสอบโดยใช้เกณฑ์ทางสถิติ หรือใช้วิธีการทางสถิติแบบไม่อิงพารามิเตอร์ซึ่งไม่ได้ขึ้นอยู่กับสมมติฐานเกี่ยวกับการเป็นสมาชิกของฟังก์ชันการกระจายของผลการวัด (การสังเกต) ไปยังตระกูลพาราเมตริกหนึ่งหรืออีกตระกูลหนึ่งการแจกแจงแบบต่อเนื่องที่ใช้ในการตัดสินใจเชิงความน่าจะเป็นและเชิงสถิติ นอกจากตระกูลการแจกแจงแบบปกติที่เลื่อนระดับแล้ว ยังมีการใช้ตระกูลการแจกแจงอื่น ๆ อีกจำนวนหนึ่งอย่างแพร่หลาย เช่น การแจกแจงแบบ lognormal, เอ็กซ์โปเนนเชียล, Weibull-Gnedenko, การแจกแจงแกมมา เอ็กซ์มาดูครอบครัวเหล่านี้กันดีกว่า ย= บันทึก เอ็กซ์ตัวแปรสุ่ม มีการแจกแจงแบบ lognormal หากเป็นตัวแปรสุ่มมีการกระจายตัวแบบปกติ แล้ว เอ็กซ์ = 2,3026…ยซี
เอ็น(ก 1
= บันทึกมีการแจกแจงแบบปกติด้วย เอ็กซ์,σ 1) เอ็กซ์ที่ไหน ln - ลอการิทึมธรรมชาติ เอ็กซ์ =
เอ็กซ์ 1
เอ็กซ์ 2
…
เอ็กซ์ เอ็น- ความหนาแน่นของการแจกแจงแบบลอจิคัลคือ: เอ็กซ์ ฉัน,
ฉัน = 1, 2,…, nจากทฤษฎีบทขีดจำกัดกลางเป็นไปตามที่ผลิตภัณฑ์ n
สามารถประมาณได้โดยการแจกแจงแบบลอจิกนอร์มอล โดยเฉพาะอย่างยิ่ง แบบจำลองการคูณของการก่อตัวของค่าจ้างหรือรายได้นำไปสู่คำแนะนำในการประมาณการกระจายของค่าจ้างและรายได้ตามกฎปกติแบบลอการิทึม สำหรับรัสเซีย คำแนะนำนี้พิสูจน์แล้วว่ามีเหตุผล - ข้อมูลทางสถิติยืนยันแล้ว มีแบบจำลองความน่าจะเป็นอื่นๆ ที่นำไปสู่กฎลอจิกนอร์มอล ตัวอย่างคลาสสิกของแบบจำลองดังกล่าวได้รับจาก A.N. Kolmogorov ซึ่งจากระบบสมมุติฐานทางกายภาพได้สรุปว่าขนาดของอนุภาคเมื่อบดแร่ถ่านหิน ฯลฯ ในโรงสีลูกกลมมีการแจกแจงแบบลอจิกนอร์มอล เอ็กซ์เรามาดูการแจกแจงอีกตระกูลหนึ่งซึ่งใช้กันอย่างแพร่หลายในวิธีการตัดสินใจทางสถิติความน่าจะเป็นและการวิจัยประยุกต์อื่น ๆ - ตระกูลของการแจกแจงแบบเอ็กซ์โปเนนเชียล เริ่มจากแบบจำลองความน่าจะเป็นที่นำไปสู่การแจกแจงดังกล่าว หากต้องการทำสิ่งนี้ ให้พิจารณา "กระแสของเหตุการณ์" เช่น ลำดับเหตุการณ์ที่เกิดขึ้นต่อเนื่องกัน ณ จุดใดจุดหนึ่ง ตัวอย่างได้แก่: ลำดับการโทรที่ชุมสายโทรศัพท์; การไหลของความล้มเหลวของอุปกรณ์ในห่วงโซ่เทคโนโลยี การไหลของความล้มเหลวของผลิตภัณฑ์ในระหว่างการทดสอบผลิตภัณฑ์ กระแสคำขอของลูกค้าไปยังสาขาของธนาคาร กระแสของผู้ซื้อที่สมัครสินค้าและบริการ ฯลฯ ในทฤษฎีเรื่องการไหลของเหตุการณ์ ทฤษฎีบทที่คล้ายกับทฤษฎีบทขีดจำกัดจุดศูนย์กลางนั้นใช้ได้ แต่มันไม่เกี่ยวกับผลรวมของตัวแปรสุ่ม แต่เกี่ยวกับผลรวมของกระแสเหตุการณ์ เราพิจารณาการไหลรวมที่ประกอบด้วยการไหลอิสระจำนวนมาก ซึ่งไม่มีการไหลใดที่มีอิทธิพลเหนือการไหลทั้งหมด ตัวอย่างเช่น กระแสการโทรเข้าสู่การแลกเปลี่ยนทางโทรศัพท์ประกอบด้วยกระแสการโทรอิสระจำนวนมากที่มีต้นกำเนิดจากสมาชิกแต่ละราย ได้รับการพิสูจน์แล้วว่าในกรณีที่ลักษณะของการไหลไม่ขึ้นอยู่กับเวลา การไหลทั้งหมดจะถูกอธิบายอย่างสมบูรณ์ด้วยตัวเลขเดียว - ความเข้มของการไหล สำหรับการไหลรวม ให้พิจารณาตัวแปรสุ่ม - ระยะเวลาระหว่างเหตุการณ์ต่อเนื่องกัน ฟังก์ชันการกระจายมีรูปแบบ จ -λ
การแจกแจงนี้เรียกว่าการแจกแจงแบบเอ็กซ์โพเนนเชียลเพราะว่า สูตร (10) เกี่ยวข้องกับฟังก์ชันเลขชี้กำลัง x กับ- ค่า 1/แล คือพารามิเตอร์มาตราส่วน บางครั้งก็มีการแนะนำพารามิเตอร์ shift ด้วย การแจกแจงของตัวแปรสุ่มเรียกว่าเลขชี้กำลังเอ็กซ์ + ส เอ็กซ์ซึ่งจะมีการกระจายสินค้า การแจกแจงแบบเอ็กซ์โปเนนเชียลเป็นกรณีพิเศษของสิ่งที่เรียกว่า การแจกแจงแบบ Weibull - Gnedenko ตั้งชื่อตามชื่อของวิศวกร V. Weibull ซึ่งแนะนำการแจกแจงเหล่านี้ในการฝึกวิเคราะห์ผลลัพธ์ของการทดสอบความล้า และนักคณิตศาสตร์ B.V. Gnedenko (1912-1995) ซึ่งได้รับการแจกแจงดังกล่าวเป็นขีดจำกัดเมื่อศึกษาค่าสูงสุด ผลการทดสอบ อนุญาต เอ็กซ์- ตัวแปรสุ่มที่แสดงลักษณะระยะเวลาการดำเนินงานของผลิตภัณฑ์ ระบบที่ซับซ้อน องค์ประกอบ (เช่น ทรัพยากร เวลาการดำเนินงานไปสู่สภาวะที่จำกัด ฯลฯ) ระยะเวลาการดำเนินงานขององค์กร หรือชีวิตของสิ่งมีชีวิต เป็นต้น ความรุนแรงของความล้มเหลวมีบทบาทสำคัญ ที่ไหน เอฟ(x)
และ ฉ(x)
- ฟังก์ชันการกระจายและความหนาแน่นของตัวแปรสุ่ม เอ็กซ์. ให้เราอธิบายพฤติกรรมทั่วไปของอัตราความล้มเหลว ช่วงเวลาทั้งหมดสามารถแบ่งออกเป็นสามช่วง ประการแรกคือฟังก์ชั่น แล(x)มีค่าสูงและมีแนวโน้มที่จะลดลงอย่างชัดเจน (ส่วนใหญ่มักจะลดลงแบบน่าเบื่อ) สิ่งนี้สามารถอธิบายได้จากการมีอยู่ในชุดของหน่วยผลิตภัณฑ์ที่มีปัญหาซึ่งมีข้อบกพร่องที่ชัดเจนและซ่อนเร้น ซึ่งนำไปสู่ความล้มเหลวที่ค่อนข้างรวดเร็วของหน่วยผลิตภัณฑ์เหล่านี้ ช่วงแรกเรียกว่า “ระยะบุก” (หรือ “ระยะบุก”) โดยปกติระยะเวลาการรับประกันจะครอบคลุมถึงนี้ จากนั้นถึงช่วงของการทำงานปกติซึ่งมีอัตราความล้มเหลวคงที่โดยประมาณและค่อนข้างต่ำ ลักษณะของความล้มเหลวในช่วงเวลานี้เกิดขึ้นอย่างกะทันหัน (อุบัติเหตุ ข้อผิดพลาดของเจ้าหน้าที่ปฏิบัติงาน ฯลฯ) และไม่ขึ้นอยู่กับระยะเวลาการทำงานของหน่วยผลิตภัณฑ์ ในที่สุดช่วงสุดท้ายของการทำงานคือช่วงอายุและการสึกหรอ ลักษณะของความล้มเหลวในช่วงเวลานี้คือการเปลี่ยนแปลงทางกายภาพ ทางกล และทางเคมีของวัสดุที่ไม่สามารถย้อนกลับได้ ซึ่งนำไปสู่การเสื่อมถอยของคุณภาพของหน่วยผลิตภัณฑ์และความล้มเหลวขั้นสุดท้าย แต่ละช่วงเวลามีประเภทของฟังก์ชันของตัวเอง แล(x)- ให้เราพิจารณาระดับของการพึ่งพาอำนาจ แล(x) = แล 0ขxข -1
,
(12) ที่ไหน λ 0 >
0 และ ข> 0 - พารามิเตอร์ตัวเลขบางตัว ค่านิยม ข < 1, ข= 0 และ ข> 1 สอดคล้องกับประเภทของอัตราความล้มเหลวในช่วงระยะเวลาของการรันอิน การทำงานปกติ และการเสื่อมสภาพ ตามลำดับ ความสัมพันธ์ (11) ในอัตราความล้มเหลวที่กำหนด แล(x)- สมการเชิงอนุพันธ์ของฟังก์ชัน เอฟ(x).
จากทฤษฎีสมการเชิงอนุพันธ์จึงเป็นไปตามนั้น เมื่อแทน (12) ลงใน (13) เราจะได้สิ่งนั้น การแจกแจงที่กำหนดโดยสูตร (14) เรียกว่าการแจกแจงแบบ Weibull - Gnedenko เนื่องจาก จากสูตร (14) จึงเป็นไปตามปริมาณ กที่กำหนดโดยสูตร (15) คือพารามิเตอร์มาตราส่วน เอฟ(x - คบางครั้งก็มีการแนะนำพารามิเตอร์ shift เช่น ฟังก์ชันการแจกแจง Weibull-Gnedenko เรียกว่า เอฟ(x), ที่ไหน ข. ) กำหนดโดยสูตร (14) สำหรับบาง แล 0 และ ที่ไหน กความหนาแน่นของการกระจาย Weibull-Gnedenko มีรูปแบบ ข> 0 - พารามิเตอร์สเกล กับ> 0 - พารามิเตอร์แบบฟอร์ม ก- พารามิเตอร์กะ ในกรณีนี้คือพารามิเตอร์ λ
จากสูตร (16) เชื่อมโยงกับพารามิเตอร์ 0 จากสูตร (14) ตามความสัมพันธ์ที่ระบุในสูตร (15) ข = 1. การแจกแจงแบบเลขชี้กำลังเป็นกรณีพิเศษมากของการแจกแจงแบบ Weibull-Gnedenko ซึ่งสอดคล้องกับค่าของพารามิเตอร์รูปร่าง เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็นการแจกแจงแบบ Weibull-Gnedenko ยังใช้ในการสร้างแบบจำลองความน่าจะเป็นของสถานการณ์ ซึ่งพฤติกรรมของวัตถุถูกกำหนดโดย "จุดอ่อนที่สุด" มีความคล้ายคลึงกับโซ่ซึ่งความปลอดภัยจะถูกกำหนดโดยลิงค์ที่มีความแข็งแรงน้อยที่สุด กล่าวอีกนัยหนึ่งให้ - ตัวแปรสุ่มที่กระจายอย่างอิสระเหมือนกันเอ็กซ์(1) =นาที(), X 1, X 2,…, Xnเอ็กซ์(เอ็น) =สูงสุด(). X 1, X 2,…, Xn เอ็กซ์(1)
และ เอ็กซ์(n)
ในปัญหาที่นำไปใช้หลายประการ ปัญหาเหล่านี้มีบทบาทสำคัญ เอ็กซ์(1)
และ เอ็กซ์(n)
โดยเฉพาะอย่างยิ่งเมื่อศึกษาค่าสูงสุดที่เป็นไปได้ ("บันทึก") ของค่าบางค่า เช่น การจ่ายเงินประกันหรือการสูญเสียเนื่องจากความเสี่ยงทางการค้า เมื่อศึกษาขีดจำกัดความยืดหยุ่นและความทนทานของเหล็ก คุณลักษณะความน่าเชื่อถือจำนวนหนึ่ง เป็นต้น . แสดงว่าสำหรับการแจกแจงขนาดใหญ่ เอ็กซ์(1)
และ เอ็กซ์(n)
ตามกฎแล้ว มีการอธิบายไว้อย่างดีโดยการแจกแจงแบบ Weibull-Gnedenko การมีส่วนร่วมขั้นพื้นฐานในการศึกษาการแจกแจง สนับสนุนโดยนักคณิตศาสตร์ชาวโซเวียต B.V. Gnedenko ผลงานของ V. Weibull, E. Gumbel, V.B. ทุ่มเทให้กับการใช้ผลลัพธ์ที่ได้รับในด้านเศรษฐศาสตร์ การจัดการ เทคโนโลยี และสาขาอื่นๆ เนฟโซโรวา, E.M. กุดเลฟ และผู้เชี่ยวชาญอื่นๆ อีกมากมาย เคมาดูตระกูลของการแจกแจงแกมมากันดีกว่า มีการใช้กันอย่างแพร่หลายในด้านเศรษฐศาสตร์และการจัดการ ทฤษฎีและการปฏิบัติเกี่ยวกับความน่าเชื่อถือและการทดสอบ ในสาขาเทคโนโลยีต่างๆ อุตุนิยมวิทยา ฯลฯ โดยเฉพาะอย่างยิ่ง ในหลาย ๆ สถานการณ์ การกระจายแกมม่าขึ้นอยู่กับปริมาณ เช่น อายุการใช้งานรวมของผลิตภัณฑ์ ความยาวของสายโซ่ของอนุภาคฝุ่นที่เป็นสื่อกระแสไฟฟ้า เวลาที่ผลิตภัณฑ์ถึงสภาวะจำกัดระหว่างการกัดกร่อน เวลาในการทำงานถึง เค- การปฏิเสธครั้งที่ = 1, 2, … ฯลฯ อายุขัยของผู้ป่วยโรคเรื้อรังและเวลาในการบรรลุผลบางอย่างระหว่างการรักษาในบางกรณีมีการกระจายแกมมา การกระจายนี้เพียงพอที่สุดสำหรับการอธิบายความต้องการในรูปแบบทางเศรษฐกิจและคณิตศาสตร์ของการจัดการสินค้าคงคลัง (โลจิสติกส์) ความหนาแน่นของความน่าจะเป็นในสูตร (17) ถูกกำหนดโดยพารามิเตอร์สามตัว ก,
ข,
ค, ที่ไหน ก>0, ข>0. ในเวลาเดียวกัน กเป็นพารามิเตอร์แบบฟอร์ม ข- พารามิเตอร์มาตราส่วนและ กับ- พารามิเตอร์กะ ปัจจัย 1/Γ(ก)กำลังทำให้เป็นมาตรฐาน มันถูกแนะนำให้รู้จักกับ ที่นี่ Γ(ก)- หนึ่งในฟังก์ชันพิเศษที่ใช้ในคณิตศาสตร์ที่เรียกว่า "ฟังก์ชันแกมมา" หลังจากนั้นจึงตั้งชื่อการแจกแจงตามสูตร (17) คงที่ กสูตร (17) ระบุตระกูลการแจกแจงแบบเลื่อนขนาดซึ่งเกิดจากการแจกแจงแบบมีความหนาแน่น การกระจายตัวของรูปแบบ (18) เรียกว่าการแจกแจงแกมมามาตรฐาน ได้มาจากสูตร (17) ณ ข= 1 และ กับ= 0. กรณีพิเศษของการแจกแจงแกมมาสำหรับ ก= 1 เป็นการแจกแจงแบบเอ็กซ์โปเนนเชียล (ด้วย แล = 1/ข- ด้วยความเป็นธรรมชาติ กและ กับการแจกแจงแกมมา =0 เรียกว่าการแจกแจงแบบ Erlang จากผลงานของนักวิทยาศาสตร์ชาวเดนมาร์ก K.A. Erlang (พ.ศ. 2421-2472) พนักงานของ บริษัท โทรศัพท์โคเปนเฮเกนซึ่งศึกษาในปี พ.ศ. 2451-2465 การทำงานของเครือข่ายโทรศัพท์ การพัฒนาทฤษฎีคิวเริ่มขึ้น ทฤษฎีนี้เกี่ยวข้องกับการสร้างแบบจำลองความน่าจะเป็นและทางสถิติของระบบซึ่งมีการให้บริการคำขอต่างๆ เพื่อการตัดสินใจที่เหมาะสมที่สุด การแจกแจง Erlang ถูกใช้ในพื้นที่แอปพลิเคชันเดียวกันกับที่ใช้การแจกแจงแบบเอ็กซ์โปเนนเชียล ขึ้นอยู่กับสิ่งต่อไปนี้ข้อเท็จจริงทางคณิตศาสตร์ กับ: ผลรวมของตัวแปรสุ่มอิสระ k ซึ่งกระจายแบบเอกซ์โปเนนเชียลด้วยพารามิเตอร์เดียวกัน แล และ มีการกระจายแกมมาพร้อมพารามิเตอร์รูปร่างเคก = ข, พารามิเตอร์มาตราส่วน = 1/แล และพารามิเตอร์ชิฟต์- ที่ กับเคซี ถ้าเป็นตัวแปรสุ่ม เอ็กซ์= 0 เราได้รับการแจกแจง Erlang กมีการแจกแจงแกมมาพร้อมพารามิเตอร์รูปร่าง ง = 2
กเช่นนั้น ข= 1 และ กับ- จำนวนเต็ม เอ็กซ์= 0 จากนั้น 2 งมีการแจกแจงแบบไคสแควร์ด้วย นอกจากตระกูลการแจกแจงแบบปกติที่เลื่อนระดับแล้ว ยังมีการใช้ตระกูลการแจกแจงอื่น ๆ อีกจำนวนหนึ่งอย่างแพร่หลาย เช่น การแจกแจงแบบ lognormal, เอ็กซ์โปเนนเชียล, Weibull-Gnedenko, การแจกแจงแกมมา เอ็กซ์ระดับความเป็นอิสระ ด้วยการแจกแจงแบบ gvmma มีลักษณะดังต่อไปนี้: ความคาดหวังม(เอ็กซ์) = +
ค, เกี่ยวกับ ดี(เอ็กซ์) =
σ
2
=
ม(เอ็กซ์) = 2
, ความแปรปรวน ค่าสัมประสิทธิ์ของการแปรผัน ความไม่สมมาตร ส่วนเกิน น) ... ตามลำดับ อนุญาต การแจกแจงแบบปกติถือเป็นกรณีที่รุนแรงของการแจกแจงแกมมา ถ้าให้เจาะจงกว่านั้น ให้ Z เป็นตัวแปรสุ่มที่มีการแจกแจงแกมมามาตรฐานตามสูตร (18) แล้ว เอ็กซ์จำนวนจริง ฉ(x), ที่ไหน เอ็น(0,1). - ฟังก์ชั่นการแจกแจงแบบปกติมาตรฐาน ในการวิจัยประยุกต์ ยังใช้ตระกูลการแจกแจงแบบพาราเมตริกอื่นๆ อีกด้วย ซึ่งระบบที่มีชื่อเสียงที่สุดคือระบบเส้นโค้ง Pearson, ซีรีส์ Edgeworth และ Charlier พวกเขาไม่ได้พิจารณาที่นี่ ไม่ต่อเนื่องที่ใช้กันมากที่สุดคือสามตระกูลของการแจกแจงแบบไม่ต่อเนื่อง - ทวินาม, ไฮเปอร์จีโอเมตริกและปัวซองรวมถึงตระกูลอื่น ๆ - เรขาคณิต, ทวินามลบ, พหุนาม, ไฮเปอร์เรขาคณิตเชิงลบ ฯลฯ ดังที่ได้กล่าวไปแล้ว การแจกแจงแบบทวินามเกิดขึ้นในการทดลองอิสระ ซึ่งในแต่ละการทดลองมีความน่าจะเป็น รเหตุการณ์ปรากฏขึ้น ก- ถ้าจำนวนการทดลองทั้งหมด nกำหนดไว้แล้วจำนวนการทดสอบ ยซึ่งเหตุการณ์ดังกล่าวก็ปรากฏขึ้น กมีการกระจายตัวแบบทวินาม สำหรับ การแจกแจงแบบทวินามความน่าจะเป็นที่จะได้รับการยอมรับเป็นตัวแปรสุ่ม ยค่านิยม ยถูกกำหนดโดยสูตร จำนวนชุดค่าผสมของ nองค์ประกอบโดย ยรู้จักจากศาสตร์เชิงผสม สำหรับทุกคน ยยกเว้น 0, 1, 2, …, nเรามี ป(ย=
ย)=
0. การแจกแจงแบบทวินามที่มีขนาดตัวอย่างคงที่ nถูกระบุโดยพารามิเตอร์ พี, เช่น. การแจกแจงแบบทวินามเป็นตระกูลที่มีพารามิเตอร์เดียว ใช้ในการวิเคราะห์ข้อมูลจากการศึกษาตัวอย่าง โดยเฉพาะอย่างยิ่งในการศึกษาความชอบของผู้บริโภค การควบคุมการเลือกคุณภาพผลิตภัณฑ์ตามแผนการควบคุมขั้นตอนเดียว เมื่อทดสอบประชากรของบุคคลในสาขาประชากรศาสตร์ สังคมวิทยา การแพทย์ ชีววิทยา ฯลฯ . ถ้า ย 1
และ ย 2
- ตัวแปรสุ่มทวินามอิสระที่มีพารามิเตอร์เดียวกัน พี 0
พิจารณาจากตัวอย่างที่มีปริมาตร n 1
และ n 2
ตามนั้น ย 1
+ ย 2
- ตัวแปรสุ่มทวินามที่มีการแจกแจง (19) ด้วย ร = พี 0
และ n
= n 1
+ n 2
- หมายเหตุนี้ขยายขอบเขตการใช้งานของการแจกแจงแบบทวินามโดยอนุญาตให้นำผลลัพธ์ของการทดสอบหลายกลุ่มมารวมกันเมื่อมีเหตุผลที่เชื่อได้ว่าพารามิเตอร์เดียวกันนั้นสอดคล้องกับกลุ่มเหล่านี้ทั้งหมด คุณลักษณะของการแจกแจงแบบทวินามถูกคำนวณก่อนหน้านี้: ม(ย) =
n.p.,
ดี(ย) =
n.p.( 1-
พี).
ในส่วน "เหตุการณ์และความน่าจะเป็น" กฎของจำนวนมากได้รับการพิสูจน์แล้วสำหรับตัวแปรสุ่มแบบทวินาม: สำหรับใครก็ตาม เมื่อใช้ทฤษฎีบทขีดจำกัดจุดศูนย์กลาง กฎของจำนวนมากสามารถปรับปรุงได้โดยการระบุจำนวน ย/
nแตกต่างจาก ร. ทฤษฎีบทเดอมัวฟวร์-ลาปลาซสำหรับตัวเลขใดๆ a และ
ข, ก<
ขเรามี ที่ไหน เอฟ(เอ็กซ์) เป็นฟังก์ชันของการแจกแจงแบบปกติมาตรฐานที่มีค่าคาดหวังทางคณิตศาสตร์เป็น 0 และความแปรปรวน 1 เพื่อพิสูจน์มัน ก็เพียงพอแล้วที่จะใช้การเป็นตัวแทน ยในรูปแบบของผลรวมของตัวแปรสุ่มอิสระที่สอดคล้องกับผลลัพธ์ของการทดสอบแต่ละรายการ สูตรสำหรับ ม(ย)
และ ดี(ย)
และทฤษฎีบทขีดจำกัดจุดศูนย์กลาง ทฤษฎีบทนี้มีไว้สำหรับกรณีนี้ ร= ½ ได้รับการพิสูจน์โดยนักคณิตศาสตร์ชาวอังกฤษ A. Moivre (1667-1754) ในปี 1730 ในสูตรข้างต้น ได้รับการพิสูจน์ในปี 1810 โดยนักคณิตศาสตร์ชาวฝรั่งเศส Pierre Simon Laplace (1749 - 1827) การกระจายแบบไฮเปอร์เรขาคณิตเกิดขึ้นระหว่างการควบคุมแบบเลือกชุดของวัตถุที่มีปริมาตร N ตามเกณฑ์ทางเลือก แต่ละอ็อบเจ็กต์ที่ถูกควบคุมจะถูกจัดประเภทว่ามีแอ็ตทริบิวต์ กหรือไม่มีลักษณะเช่นนี้ การแจกแจงแบบไฮเปอร์เรขาคณิตมีตัวแปรสุ่ม ย, เท่ากับจำนวนวัตถุที่มีลักษณะเฉพาะ กในตัวอย่างปริมาตรแบบสุ่ม n, ที่ไหน n<
เอ็น- เช่น ตัวเลข ยหน่วยของผลิตภัณฑ์ที่มีข้อบกพร่องในตัวอย่างปริมาตรแบบสุ่ม nจากปริมาณแบทช์ เอ็นมีการกระจายแบบไฮเปอร์เรขาคณิตถ้า n<
เอ็น.
อีกตัวอย่างหนึ่งคือลอตเตอรี ให้สัญญาณ กตั๋วเป็นสัญลักษณ์ของ "การเป็นผู้ชนะ" ให้นับจำนวนตั๋วทั้งหมด เอ็น,
และบุคคลบางคนได้รับมา nของพวกเขา จำนวนตั๋วที่ชนะสำหรับบุคคลนี้มีการกระจายแบบไฮเปอร์เรขาคณิต สำหรับการแจกแจงแบบไฮเปอร์เรขาคณิต ความน่าจะเป็นที่ตัวแปรสุ่ม Y ยอมรับค่า y จะมีรูปแบบ ที่ไหน ดี– จำนวนวัตถุที่มีคุณสมบัติ กในชุดปริมาตรที่พิจารณา เอ็น- ในเวลาเดียวกัน ยรับค่าจากสูงสุด (0, n - (เอ็น -
ดี)) ถึงนาที( n,
ดี) สิ่งอื่นๆ ยความน่าจะเป็นในสูตร (20) เท่ากับ 0 ดังนั้นการแจกแจงแบบไฮเปอร์เรขาคณิตจึงถูกกำหนดโดยพารามิเตอร์สามตัว - ปริมาตร ประชากร เอ็น,
จำนวนวัตถุ ดีอยู่ในนั้นโดยมีลักษณะเฉพาะนั้น กและขนาดตัวอย่าง n.
การสุ่มตัวอย่างด้วยปริมาตรแบบสุ่มอย่างง่าย nจากปริมาตรรวม เอ็นคือตัวอย่างที่ได้จากการสุ่มเลือกชุดใดชุดหนึ่ง nวัตถุมีความน่าจะเป็นเท่ากันในการเลือก วิธีการสุ่มเลือกตัวอย่างของผู้ตอบแบบสอบถาม (ผู้ให้สัมภาษณ์) หรือหน่วยของสินค้าเป็นชิ้นจะกล่าวถึงในเอกสารคำแนะนำ วิธีการ และข้อบังคับ หนึ่งในวิธีการเลือกคือ: วัตถุจะถูกเลือกจากอีกวัตถุหนึ่ง และในแต่ละขั้นตอน แต่ละวัตถุที่เหลืออยู่ในชุดจะมีโอกาสถูกเลือกเท่ากัน ในวรรณกรรม คำว่า "ตัวอย่างสุ่ม" และ "ตัวอย่างสุ่มโดยไม่มีการส่งคืน" ยังใช้สำหรับประเภทของตัวอย่างที่อยู่ระหว่างการพิจารณาด้วย เนื่องจากปริมาณประชากร (ชุด) เอ็นและตัวอย่าง nโดยทั่วไปจะทราบอยู่แล้ว ดังนั้นพารามิเตอร์ของการแจกแจงแบบไฮเปอร์เรขาคณิตที่จะประมาณก็คือ ดี- ในวิธีทางสถิติของการจัดการคุณภาพผลิตภัณฑ์ ดี– โดยปกติคือจำนวนหน่วยที่ชำรุดในชุด ดี/
เอ็นลักษณะการกระจายก็น่าสนใจเช่นกัน – ระดับของข้อบกพร่อง สำหรับการกระจายแบบไฮเปอร์เรขาคณิต เอ็น>10
nตัวประกอบสุดท้ายในนิพจน์สำหรับความแปรปรวนมีค่าใกล้เคียงกับ 1 if พี =
ดี/
เอ็น,
จากนั้นนิพจน์สำหรับความคาดหวังทางคณิตศาสตร์และความแปรปรวนของการแจกแจงแบบไฮเปอร์จีโอเมตริกจะกลายเป็นนิพจน์สำหรับความคาดหวังทางคณิตศาสตร์และความแปรปรวนของการแจกแจงแบบทวินาม นี่ไม่ใช่อุบัติเหตุ ก็สามารถแสดงได้ว่า ที่ เอ็น>10
n,
ที่ไหน พี =
ดี/
เอ็น.
อัตราส่วนจำกัดถูกต้อง และความสัมพันธ์อันจำกัดนี้สามารถใช้ได้เมื่อใด เอ็น>10
n.
การแจกแจงแบบไม่ต่อเนื่องแบบที่สามที่ใช้กันอย่างแพร่หลายคือการแจกแจงแบบปัวซง ตัวแปรสุ่ม Y มีการแจกแจงปัวซองถ้า ป(ย=
ย)=
โดยที่ แล คือพารามิเตอร์การแจกแจงปัวซอง และ ย 0 สำหรับคนอื่นๆ ทั้งหมด ม(ย)
= λ, ดี(ย)
= λ. (สำหรับ y=0 กำหนดให้เป็น 0! =1) สำหรับการกระจายปัวซอง รการแจกแจงนี้ตั้งชื่อตามนักคณิตศาสตร์ชาวฝรั่งเศส เอส. ดี. ปัวซอง (ค.ศ. 1781-1840) ซึ่งได้รับการกระจายครั้งแรกในปี ค.ศ. 1837 การแจกแจงแบบปัวซองเป็นกรณีที่จำกัดของการแจกแจงแบบทวินาม เมื่อความน่าจะเป็น nการดำเนินกิจกรรมมีขนาดเล็กแต่มีจำนวนการทดสอบ n.p.เยี่ยมยอดและ = แล. แม่นยำยิ่งขึ้น ความสัมพันธ์ขีดจำกัดนั้นถูกต้อง ดังนั้นการกระจายปัวซอง (ในคำศัพท์เก่า "กฎการกระจาย") จึงมักถูกเรียกว่า "กฎของเหตุการณ์ที่หายาก" ทีการแจกแจงแบบปัวซองมีต้นกำเนิดมาจากทฤษฎีการไหลของเหตุการณ์ (ดูด้านบน) ได้รับการพิสูจน์แล้วว่าสำหรับการไหลที่ง่ายที่สุดที่มีความเข้มข้นคงที่ Λ คือจำนวนเหตุการณ์ (การโทร) ที่เกิดขึ้นในช่วงเวลานั้น ทีมีการแจกแจงแบบปัวซองพร้อมพารามิเตอร์ แล = Λ ที- ดังนั้นความน่าจะเป็นนั้นในระหว่างช่วงเวลานั้น จ -
Λ ไม่มีเหตุการณ์ใดเกิดขึ้นเท่ากับที , เช่น. ฟังก์ชันการกระจายของความยาวของช่วงเวลาระหว่างเหตุการณ์เป็นแบบเลขชี้กำลัง การแจกแจงแบบปัวซองใช้เมื่อวิเคราะห์ผลการสำรวจการตลาดตัวอย่างผู้บริโภคโดยคำนวณลักษณะการปฏิบัติงานของแผนควบคุมการยอมรับทางสถิติในกรณีที่มีค่าน้อยของระดับการยอมรับข้อบกพร่องเพื่ออธิบายจำนวนการแยกย่อยของข้อบกพร่องที่ควบคุมทางสถิติกระบวนการทางเทคโนโลยี ต่อหน่วยเวลา จำนวน “คำขอรับบริการ” ที่เข้าระบบคิวต่อหน่วยเวลา รูปแบบสถิติอุบัติเหตุและโรคหายาก เป็นต้น คำอธิบายของกลุ่มพารามิเตอร์อื่นๆ ของการแจกแจงแบบแยกส่วนและความเป็นไปได้การใช้งานจริง ได้รับการพิจารณาในวรรณคดี ก่อนหน้า การแจกแจงแบบปกติหมายถึงสิ่งต่อไปนี้
: มีค่าความสูงของมนุษย์, มวลของปลาในสายพันธุ์เดียวกัน, ซึ่งรับรู้โดยสัญชาตญาณว่าเป็น "ปกติ" (และในความเป็นจริง, โดยเฉลี่ย) และในกลุ่มตัวอย่างที่มีขนาดใหญ่เพียงพอจะพบได้บ่อยกว่าค่าเหล่านั้น แตกต่างกันขึ้นหรือลง การแจกแจงความน่าจะเป็นปกติของตัวแปรสุ่มต่อเนื่อง (บางครั้งเป็นการแจกแจงแบบเกาส์เซียน) สามารถเรียกได้ว่าเป็นรูประฆัง เนื่องจากฟังก์ชันความหนาแน่นของการแจกแจงนี้มีความสมมาตรเกี่ยวกับค่าเฉลี่ย คล้ายกับการตัดระฆังมาก (เส้นโค้งสีแดง ในรูปด้านบน) ความน่าจะเป็นที่จะพบค่าบางค่าในตัวอย่างจะเท่ากับพื้นที่ของรูปใต้เส้นโค้ง และในกรณีของการแจกแจงแบบปกติ เราจะเห็นว่าใต้ด้านบนของ “ระฆัง” ซึ่งสอดคล้องกับค่า การพุ่งเข้าหาค่าเฉลี่ย พื้นที่ และความน่าจะเป็นจึงมากกว่าใต้ขอบ ดังนั้นเราจึงได้สิ่งเดียวกันกับที่กล่าวไว้แล้ว: ความน่าจะเป็นที่จะพบกับบุคคลที่มีส่วนสูง "ปกติ" และจับปลาที่มีน้ำหนัก "ปกติ" นั้นสูงกว่าค่าที่แตกต่างกันขึ้นหรือลง ในทางปฏิบัติหลายๆ กรณี ข้อผิดพลาดในการวัดจะถูกกระจายไปตามกฎที่ใกล้เคียงกับปกติ ลองดูรูปที่ตอนต้นบทเรียนอีกครั้ง ซึ่งแสดงฟังก์ชันความหนาแน่นของการแจกแจงแบบปกติ กราฟของฟังก์ชันนี้ได้มาจากการคำนวณตัวอย่างข้อมูลบางอย่างในชุดซอฟต์แวร์ สถิติ- คอลัมน์ฮิสโตแกรมแสดงช่วงต่างๆ ของค่าตัวอย่าง ซึ่งการกระจายของค่านั้นใกล้เคียงกับ (หรือตามที่พูดกันทั่วไปในสถิติ ไม่แตกต่างอย่างมีนัยสำคัญจาก) กราฟจริงของฟังก์ชันความหนาแน่นของการแจกแจงแบบปกติ ซึ่งเป็นเส้นโค้งสีแดง . กราฟแสดงว่าเส้นโค้งนี้เป็นรูประฆังจริงๆ การแจกแจงแบบปกติมีคุณค่าในหลายๆ ด้าน เนื่องจากการทราบเพียงค่าคาดหวังของตัวแปรสุ่มต่อเนื่องและค่าเบี่ยงเบนมาตรฐาน คุณจึงสามารถคำนวณความน่าจะเป็นใดๆ ที่เกี่ยวข้องกับตัวแปรนั้นได้ การแจกแจงแบบปกติยังมีข้อดีคือเป็นหนึ่งในวิธีที่ง่ายที่สุดในการใช้งาน การทดสอบทางสถิติที่ใช้ในการทดสอบสมมติฐานทางสถิติ - การทดสอบของนักเรียน- สามารถใช้ได้หากข้อมูลตัวอย่างเป็นไปตามกฎหมายการกระจายแบบปกติเท่านั้น ฟังก์ชันความหนาแน่นของการแจกแจงแบบปกติของตัวแปรสุ่มต่อเนื่องสามารถพบได้โดยใช้สูตร: ที่ไหน x- มูลค่าของปริมาณที่เปลี่ยนแปลง - ค่าเฉลี่ย - ส่วนเบี่ยงเบนมาตรฐาน จ=2.71828... - ฐานของลอการิทึมธรรมชาติ, =3.1416... คุณสมบัติของฟังก์ชันความหนาแน่นของการแจกแจงแบบปกติ การเปลี่ยนแปลงของค่าเฉลี่ยจะเคลื่อนเส้นโค้งฟังก์ชันความหนาแน่นปกติเข้าหาแกน วัว- ถ้ามันเพิ่มขึ้น เส้นโค้งจะเคลื่อนไปทางขวา ถ้ามันลดลง แล้วก็ไปทางซ้าย หากค่าเบี่ยงเบนมาตรฐานเปลี่ยนแปลง ความสูงของส่วนบนของเส้นโค้งจะเปลี่ยนไป เมื่อค่าเบี่ยงเบนมาตรฐานเพิ่มขึ้น ด้านบนของเส้นโค้งจะสูงขึ้น และเมื่อลดลง ก็จะต่ำลง ในย่อหน้านี้เราจะเริ่มแก้ไขปัญหาเชิงปฏิบัติซึ่งความหมายระบุไว้ในชื่อเรื่อง มาดูกันว่าทฤษฎีความเป็นไปได้มีไว้เพื่อการแก้ปัญหาอย่างไร แนวคิดเริ่มต้นในการคำนวณความน่าจะเป็นของตัวแปรสุ่มแบบกระจายปกติที่อยู่ในช่วงที่กำหนดคือฟังก์ชันสะสมของการแจกแจงแบบปกติ ฟังก์ชันการแจกแจงแบบปกติสะสม: อย่างไรก็ตาม การหาตารางสำหรับทุกค่าผสมของค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานที่เป็นไปได้อาจเป็นปัญหาได้ ดังนั้นหนึ่งใน วิธีง่ายๆการคำนวณความน่าจะเป็นของตัวแปรสุ่มแบบกระจายปกติที่อยู่ในช่วงที่กำหนดคือการใช้ตารางความน่าจะเป็นสำหรับการแจกแจงแบบปกติที่เป็นมาตรฐาน การแจกแจงแบบปกติเรียกว่าการทำให้เป็นมาตรฐานหรือทำให้เป็นมาตรฐานค่าเฉลี่ยคือ และส่วนเบี่ยงเบนมาตรฐานคือ ฟังก์ชันความหนาแน่นของการแจกแจงแบบปกติที่ได้มาตรฐาน: ฟังก์ชันสะสมของการแจกแจงแบบปกติมาตรฐาน: รูปด้านล่างแสดงฟังก์ชันรวมของการแจกแจงแบบปกติมาตรฐาน ซึ่งกราฟได้มาจากการคำนวณตัวอย่างข้อมูลบางอย่างในชุดซอฟต์แวร์ สถิติ- กราฟนั้นเป็นเส้นโค้งสีแดงและค่าตัวอย่างกำลังเข้าใกล้ หากต้องการขยายภาพคุณสามารถคลิกด้วยปุ่มซ้ายของเมาส์ การทำให้ตัวแปรสุ่มเป็นมาตรฐานหมายถึงการย้ายจากหน่วยเดิมที่ใช้ในงานไปเป็นหน่วยมาตรฐาน การกำหนดมาตรฐานจะดำเนินการตามสูตร ในทางปฏิบัติ ค่าที่เป็นไปได้ทั้งหมดของตัวแปรสุ่มมักจะไม่ทราบ ดังนั้นค่าของค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานจึงไม่สามารถระบุได้อย่างแม่นยำ จะถูกแทนที่ด้วยค่าเฉลี่ยเลขคณิตของการสังเกตและส่วนเบี่ยงเบนมาตรฐาน ส- ขนาด zเป็นการแสดงออกถึงความเบี่ยงเบนของค่าของตัวแปรสุ่มจากค่าเฉลี่ยเลขคณิตเมื่อทำการวัดส่วนเบี่ยงเบนมาตรฐาน ตารางความน่าจะเป็นของการแจกแจงแบบปกติมาตรฐานซึ่งมีอยู่ในหนังสือสถิติเกือบทุกเล่ม มีความน่าจะเป็นที่ตัวแปรสุ่มจะมีการแจกแจงแบบปกติมาตรฐาน มีการแจกแจงแบบ lognormal หากเป็นตัวแปรสุ่มจะใช้ค่าน้อยกว่าจำนวนหนึ่ง z- นั่นคือมันจะตกอยู่ในช่วงเปิดจากลบอนันต์ถึง z- เช่น ความน่าจะเป็นที่ปริมาณ มีการแจกแจงแบบ lognormal หากเป็นตัวแปรสุ่มน้อยกว่า 1.5 เท่ากับ 0.93319 ตัวอย่างที่ 1บริษัทผลิตชิ้นส่วนที่มีการกระจายอายุการใช้งานตามปกติ โดยมีค่าเฉลี่ย 1,000 ชั่วโมง และค่าเบี่ยงเบนมาตรฐาน 200 ชั่วโมง สำหรับชิ้นส่วนที่เลือกแบบสุ่ม ให้คำนวณความน่าจะเป็นที่อายุการใช้งานจะอยู่ที่อย่างน้อย 900 ชั่วโมง สารละลาย. ขอแนะนำสัญกรณ์แรก: ความน่าจะเป็นที่ต้องการ ค่าตัวแปรสุ่มจะอยู่ในช่วงเวลาเปิด แต่เรารู้วิธีคำนวณความน่าจะเป็นที่ตัวแปรสุ่มจะได้ค่าน้อยกว่าค่าที่กำหนด และตามเงื่อนไขของปัญหา เราจำเป็นต้องค้นหาค่าหนึ่งที่เท่ากับหรือมากกว่าค่าที่กำหนด นี่คืออีกส่วนหนึ่งของพื้นที่ใต้เส้นโค้งความหนาแน่นปกติ (ระฆัง) ดังนั้นในการค้นหาความน่าจะเป็นที่ต้องการ คุณจะต้องลบความน่าจะเป็นดังกล่าวออกจากความสามัคคีที่ตัวแปรสุ่มจะใช้ค่าน้อยกว่าที่ระบุ 900: ตอนนี้ตัวแปรสุ่มจำเป็นต้องได้รับการกำหนดมาตรฐาน เรายังคงแนะนำสัญลักษณ์ต่อไป: z = (เอ็กซ์ ≤ 900)
; x= 900 - ค่าที่ระบุของตัวแปรสุ่ม μ
= 1,000 - มูลค่าเฉลี่ย; σ
= 200 - ส่วนเบี่ยงเบนมาตรฐาน เมื่อใช้ข้อมูลเหล่านี้ เราได้รับเงื่อนไขของปัญหา: ตามตารางตัวแปรสุ่มมาตรฐาน (ขอบเขตช่วง) z= −0.5 สอดคล้องกับความน่าจะเป็น 0.30854 ลบออกจากความสามัคคีและรับสิ่งที่จำเป็นในคำสั่งปัญหา: ดังนั้น ความน่าจะเป็นที่ชิ้นส่วนจะมีอายุการใช้งานอย่างน้อย 900 ชั่วโมงคือ 69% ความน่าจะเป็นนี้สามารถหาได้โดยใช้ฟังก์ชัน MS Excel NORM.DIST (ค่าจำนวนเต็ม - 1): ป(เอ็กซ์≥900) = 1 - ป(เอ็กซ์≤900) = 1 - ปกติ.DIST(900; 1000; 200; 1) = 1 - 0.3085 = 0.6915 เกี่ยวกับการคำนวณใน MS Excel - ในย่อหน้าใดย่อหน้าหนึ่งของบทเรียนนี้ ตัวอย่างที่ 2ในเมืองหนึ่ง รายได้เฉลี่ยของครอบครัวต่อปีเป็นตัวแปรสุ่มแบบกระจายปกติ โดยมีค่าเฉลี่ย 300,000 และค่าเบี่ยงเบนมาตรฐาน 50,000 เป็นที่ทราบกันดีว่ารายได้ 40% ของครอบครัวนั้นน้อยกว่า ก- หาค่า ก. สารละลาย. ในปัญหานี้ 40% ไม่มีอะไรมากไปกว่าความน่าจะเป็นที่ตัวแปรสุ่มจะนำค่าจากช่วงเปิดที่น้อยกว่าค่าที่กำหนดโดยระบุด้วยตัวอักษร ก. เพื่อหาค่า กขั้นแรกเราเขียนฟังก์ชันอินทิกรัล: ตามเงื่อนไขของปัญหา μ
= 300000 - มูลค่าเฉลี่ย; σ
= 50,000 - ส่วนเบี่ยงเบนมาตรฐาน x = ก- ปริมาณที่จะพบ สร้างความเท่าเทียมกัน จากตารางสถิติเราพบว่าความน่าจะเป็น 0.40 สอดคล้องกับค่าของขอบเขตช่วง z = −0,25
. เราจึงสร้างความเท่าเทียมกัน และหาทางแก้ไข: ก = 287300
. คำตอบ: 40% ของครอบครัวมีรายได้น้อยกว่า 287,300 ในปัญหาหลายๆ อย่าง จำเป็นต้องค้นหาความน่าจะเป็นที่ตัวแปรสุ่มแบบกระจายแบบปกติจะรับค่าในช่วงเวลานั้น z 1 ถึง z 2. นั่นคือมันจะตกอยู่ในช่วงปิด ในการแก้ปัญหาดังกล่าว จำเป็นต้องค้นหาความน่าจะเป็นในตารางที่สอดคล้องกับขอบเขตของช่วงเวลา จากนั้นจึงค้นหาความแตกต่างระหว่างความน่าจะเป็นเหล่านี้ สิ่งนี้จำเป็นต้องลบค่าที่น้อยกว่าออกจากค่าที่มากกว่า ตัวอย่างวิธีแก้ไขปัญหาทั่วไปเหล่านี้มีดังต่อไปนี้ และระบบจะขอให้คุณแก้ไขด้วยตนเอง จากนั้นคุณจะเห็นวิธีแก้ไขและคำตอบที่ถูกต้อง ตัวอย่างที่ 3กำไรขององค์กรในช่วงระยะเวลาหนึ่งเป็นตัวแปรสุ่มภายใต้กฎหมายการกระจายแบบปกติซึ่งมีมูลค่าเฉลี่ย 0.5 ล้าน และส่วนเบี่ยงเบนมาตรฐาน 0.354 คำนวณให้แม่นยำถึงทศนิยมสองตำแหน่ง ความน่าจะเป็นที่กำไรของบริษัทจะอยู่ระหว่าง 0.4 ถึง 0.6 ลูกบาศก์เมตร ตัวอย่างที่ 4ความยาวของชิ้นส่วนที่ผลิตขึ้นเป็นตัวแปรสุ่มซึ่งกระจายตามกฎปกติพร้อมพารามิเตอร์ μ
=10 และ σ
=0.071. ค้นหาความน่าจะเป็นของข้อบกพร่องซึ่งมีความแม่นยำถึงทศนิยมสองตำแหน่ง หากขนาดที่อนุญาตของชิ้นส่วนต้องเป็น 10±0.05 คำแนะนำ: ในปัญหานี้ นอกเหนือจากการค้นหาความน่าจะเป็นที่ตัวแปรสุ่มจะตกอยู่ในช่วงปิด (ความน่าจะเป็นที่จะได้รับชิ้นส่วนที่ไม่มีข้อบกพร่อง) คุณยังจำเป็นต้องดำเนินการอีกหนึ่งอย่างอีกด้วย ช่วยให้คุณสามารถกำหนดความน่าจะเป็นที่ค่ามาตรฐานได้ มีการแจกแจงแบบ lognormal หากเป็นตัวแปรสุ่มไม่น้อย -zและไม่มีอีกแล้ว +z, ที่ไหน z- ค่าที่เลือกโดยพลการของตัวแปรสุ่มมาตรฐาน วิธีการโดยประมาณในการตรวจสอบความเป็นปกติของการแจกแจงค่าตัวอย่างมีดังต่อไปนี้ สมบัติของการแจกแจงแบบปกติ: สัมประสิทธิ์ความเบ้ β
1
และสัมประสิทธิ์ความโด่ง β
2
มีค่าเท่ากับศูนย์. ค่าสัมประสิทธิ์ความไม่สมมาตร β
1
แสดงลักษณะเชิงตัวเลขของความสมมาตรของการแจกแจงเชิงประจักษ์สัมพันธ์กับค่าเฉลี่ย หากค่าสัมประสิทธิ์ความเบ้เป็นศูนย์ ค่าเฉลี่ยเลขคณิต ค่ามัธยฐาน และโหมดจะเท่ากัน และกราฟความหนาแน่นของการแจกแจงมีความสมมาตรเกี่ยวกับค่าเฉลี่ย หากค่าสัมประสิทธิ์ความไม่สมมาตรน้อยกว่าศูนย์ (β
1
< 0
) ดังนั้นค่าเฉลี่ยเลขคณิตจะน้อยกว่าค่ามัธยฐาน และค่ามัธยฐานจะน้อยกว่าโหมด () และ เส้นโค้งจะเลื่อนไปทางขวา (เทียบกับการแจกแจงแบบปกติ). หากค่าสัมประสิทธิ์ความไม่สมมาตรมากกว่าศูนย์ (β
1
> 0
) ดังนั้นค่าเฉลี่ยเลขคณิตจะมากกว่าค่ามัธยฐาน และค่ามัธยฐานจะมากกว่าค่าโหมด () และ เส้นโค้งจะเลื่อนไปทางซ้าย (เทียบกับการแจกแจงแบบปกติ). ค่าสัมประสิทธิ์เคอร์โทซิส β
2
แสดงลักษณะความเข้มข้นของการแจกแจงเชิงประจักษ์รอบค่าเฉลี่ยเลขคณิตในทิศทางของแกน เฮ้ยและระดับจุดสูงสุดของเส้นโค้งความหนาแน่นของการแจกแจง หากค่าสัมประสิทธิ์ความโด่งมากกว่าศูนย์ แสดงว่าเส้นโค้งนั้นยาวขึ้น (เมื่อเทียบกับการแจกแจงแบบปกติ)ตามแนวแกน เฮ้ย(กราฟจะมีจุดสูงสุดมากขึ้น) หากค่าสัมประสิทธิ์ความโด่งน้อยกว่าศูนย์ เส้นโค้งจะแบนมากขึ้น (เมื่อเทียบกับการแจกแจงแบบปกติ)ตามแนวแกน เฮ้ย(กราฟจะป้านมากขึ้น) ค่าสัมประสิทธิ์ความไม่สมมาตรสามารถคำนวณได้โดยใช้ฟังก์ชัน MS Excel SKOS หากคุณกำลังตรวจสอบอาร์เรย์ข้อมูลหนึ่งรายการ คุณจะต้องป้อนช่วงข้อมูลในช่อง "ตัวเลข" ช่องเดียว ค่าสัมประสิทธิ์ความโด่งสามารถคำนวณได้โดยใช้ฟังก์ชัน MS Excel KURTESS เมื่อตรวจสอบอาร์เรย์ข้อมูลหนึ่งรายการ การป้อนช่วงข้อมูลในกล่อง "ตัวเลข" กล่องเดียวก็เพียงพอแล้ว อย่างที่เรารู้อยู่แล้วว่าด้วยการแจกแจงแบบปกติค่าสัมประสิทธิ์ของความเบ้และความโด่งจะเท่ากับศูนย์ แต่จะเกิดอะไรขึ้นถ้าเรามีค่าสัมประสิทธิ์ความเบ้ -0.14, 0.22, 0.43 และค่าสัมประสิทธิ์ความเบ้ที่ 0.17, -0.31, 0.55? คำถามนี้ค่อนข้างยุติธรรมเนื่องจากในทางปฏิบัติเรากำลังเผชิญกับค่าตัวอย่างของความไม่สมมาตรและความโด่งโดยประมาณเท่านั้นซึ่งอาจมีการกระจายที่ไม่สามารถหลีกเลี่ยงไม่ได้และไม่สามารถควบคุมได้ ดังนั้นจึงไม่มีใครเรียกร้องให้ค่าสัมประสิทธิ์เหล่านี้เท่ากับศูนย์อย่างเคร่งครัดเท่านั้น โดยจะต้องใกล้เคียงกับศูนย์เท่านั้น แต่คำว่าเพียงพอหมายถึงอะไร? จำเป็นต้องเปรียบเทียบค่าเชิงประจักษ์ที่ได้รับกับค่าที่ยอมรับได้ ในการทำเช่นนี้คุณจะต้องตรวจสอบความไม่เท่าเทียมกันดังต่อไปนี้ (เปรียบเทียบค่าของสัมประสิทธิ์โมดูลัสกับค่าวิกฤต - ขอบเขตของพื้นที่ทดสอบสมมติฐาน) สำหรับค่าสัมประสิทธิ์ความไม่สมมาตร β
1
.กฎการกระจายของตัวแปรสุ่มแบบไม่ต่อเนื่อง

คำนี้ปรากฏค่อนข้างบ่อย แถว
การกระจายแต่ในบางสถานการณ์อาจฟังดูคลุมเครือ ดังนั้นฉันจะยึดติดกับ "กฎหมาย"

![]()
![]()
– ดังนั้น ความน่าจะเป็นที่จะชนะหน่วยทั่วไปคือ 0.4
– ความน่าจะเป็นที่ตั๋วสุ่มจะเป็นผู้แพ้![]()
ความคาดหวังของตัวแปรสุ่มแบบไม่ต่อเนื่อง
![]() ตามลำดับ จากนั้นความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่มนี้จะเท่ากับ ผลรวมของผลิตภัณฑ์ค่าทั้งหมดตามความน่าจะเป็นที่สอดคล้องกัน:
ตามลำดับ จากนั้นความคาดหวังทางคณิตศาสตร์ของตัวแปรสุ่มนี้จะเท่ากับ ผลรวมของผลิตภัณฑ์ค่าทั้งหมดตามความน่าจะเป็นที่สอดคล้องกัน:![]()

![]()
 (1)
(1)


![]()
![]() . (3)
. (3)![]() (4)
(4)![]() (6)
(6)![]() .
.
![]() ,
,![]() .
.![]() ทำให้สามารถลดความซับซ้อนของเหตุผลของวิธีการ การกำหนดทฤษฎีบทและสูตรการคำนวณ
ทำให้สามารถลดความซับซ้อนของเหตุผลของวิธีการ การกำหนดทฤษฎีบทและสูตรการคำนวณ![]()
![]()
![]()
![]() กล่าวคือ
กล่าวคือ![]()
![]()
![]()
![]() ,
,![]() .
.![]()

![]()
![]() ดังนั้นหากตัวแปรสุ่ม เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็น เอ็น(ม, )
แล้วค่าเฉลี่ยเลขคณิตของพวกเขา
ดังนั้นหากตัวแปรสุ่ม เอ็กซ์ 1
,
เอ็กซ์ 2
,…,
เอ็กซ์ เอ็น เอ็น(ม, )
แล้วค่าเฉลี่ยเลขคณิตของพวกเขา![]()
![]()

 (10)
(10)![]() (11)
(11) (13)
(13) (14)
(14) (16)
(16) (17)
(17)![]()

 (18)
(18)![]()
![]()
![]()
![]()
![]()

 (20)
(20)
![]() ,
,ในบางกรณี ตัวอย่างเช่น เมื่อศึกษาราคา ปริมาณผลผลิต หรือเวลารวมระหว่างความล้มเหลวในปัญหาความน่าเชื่อถือ ฟังก์ชันการแจกแจงจะคงที่ในบางช่วงเวลาที่ค่าของตัวแปรสุ่มที่ศึกษาไม่สามารถตกได้
 ,
,![]()
ความน่าจะเป็นที่ตัวแปรสุ่มแบบกระจายแบบปกติจะตกภายในช่วงเวลาที่กำหนด
 .
.![]() .
.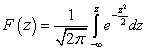 .
.
ช่วงเวลาเปิด
![]() .
.![]()
![]() .
.![]()
ช่วงปิด
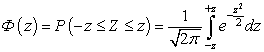
วิธีการโดยประมาณสำหรับการตรวจสอบความปกติของการแจกแจง









