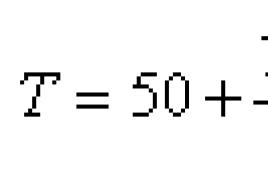Narišite 90 interval zaupanja. Konstrukcija intervala zaupanja za matematično pričakovanje splošne populacije
Primer intervalnega ocenjevanja je interval zaupanja. Interval zaupanja je segment, katerega središče je točkovna ocena numerične značilnosti, vključno z resnično vrednostjo te numerične značilnosti z dano verjetnostjo. Ta verjetnost se imenuje verjetnost zaupanja. Tako je interval zaupanja merilo točnosti ocene, verjetnost zaupanja pa označuje njeno zanesljivost. Velikost intervala zaupanja je odvisna od vrednosti verjetnosti zaupanja, ki jo poda izvajalec eksperimenta. Višja kot je stopnja zaupanja, širši mora biti interval, da lahko z dano verjetnostjo vključimo pravo vrednost numerične karakteristike. Pogosto je izbrana vrednost zaupanja P d = 0,95, s čimer se verjame, da je ta vrednost dovolj velika, da se šteje, da interval zaupanja "skoraj vedno" pokriva pravo vrednost. Le včasih se pri odgovornih in zelo odgovornih raziskavah predpostavi P d = 0,99 oziroma 0,999.
Postopek izdelave intervala zaupanja vključuje dva koraka:
Zapis verjetnostne izjave o neki naključni funkciji, ki vključuje razliko ali razmerje ocene in numerične značilnosti. Takšna funkcija nosi informacijo o stopnji bližine omenjenih vrednosti. Poznati je treba porazdelitveni zakon funkcije;
Verjetnostni stavek se preoblikuje v obliko, v kateri so meje intervala zaupanja numerične karakteristike predstavljene v eksplicitni obliki.
Primeri funkcij z znano porazdelitvijo, ki izpolnjujejo zahtevane zahteve, so naslednji:
imajo normalno porazdelitev, če je vrednost X normalno porazdeljena in je vrednost s[X] znana;
2)  (3.25)
(3.25)
s Studentovo porazdelitvijo c m = N-1, če je vrednost X normalno porazdeljena in vrednost s[X] ni vnaprej znana, vendar je njeno oceno mogoče dobiti iz eksperimentalnih podatkov z uporabo formule (3.23);
3)  (3.26)
(3.26)
s Pearsonovo porazdelitvijo z m = N-1, če je vrednost X normalno porazdeljena.
Spomnimo se, da so parametri porazdelitve m števila prostostnih stopinj. Poleg tega so tu uporabljeni naslednji zapisi: - aritmetična povprečna vrednost, - povprečna kvadratna vrednost, enaka kvadratnemu korenu variance, [X] - ocena srednje okvirne vrednosti, definirana kot kvadratni koren nepristranske ocene variance, N - velikost vzorca.
Funkciji Z in t se lahko uporabita za konstruiranje intervala zaupanja za povprečje, medtem ko funkcija c 2 konstruira interval zaupanja za varianco.
Konstruirajmo interval zaupanja za matematično pričakovanje, pod pogojem, da imamo na razpolago rezultate N opazovanj normalno porazdeljene količine X, srednja kvadratna vrednost pa je znana vnaprej iz neodvisnih opazovanj. Ker je funkcija Z normalno porazdeljena, lahko uporabite ustrezno tabelo za določitev vrednosti z a tako, da je zunaj - z a in + z a del površine pod porazdelitveno krivuljo v vsoti enak a, medtem ko je znotraj [- z a ,+ z a ] del površine enak 1 - a . Pravkar povedano ustreza naslednji verjetnostni izjavi:
Р(- z a £  £+z a )= 1-a. (3,27)
£+z a )= 1-a. (3,27)
(Verjetnost izpolnitve neenakosti v zavitih oklepajih je 1-a.). Preoblikujemo izraz v oklepajih:
Р(-z a  )= 1 - a
)= 1 - a
Vrednost 1-a = Р d imenujemo verjetnost zaupanja Р d. Glede na (3.28) je s to verjetnostjo zaupanja interval zaupanja za M[X] podan z mejami:
 . (3.29)
. (3.29)
komentar: Na žalost so običajne distribucijske tabele v različnih knjigah zgrajene drugače. Včasih je podan verjetnostni integral
Ф(z) = 
Vsak vzorec daje le približno predstavo o generalni populaciji, vse vzorčne statistične značilnosti (povprečje, modus, varianca ...) pa so nek približek ali recimo ocena splošnih parametrov, ki jih v večini primerov ni mogoče izračunati zaradi nedostopnosti generalne populacije (Slika 20).
Slika 20. Vzorčna napaka
Lahko pa določite interval, v katerem se z določeno stopnjo verjetnosti nahaja prava (splošna) vrednost statistične značilnosti. Ta interval se imenuje d interval zaupanja (CI).
Torej je splošno povprečje z verjetnostjo 95% znotraj
od do, (20)
Kje t - tabelarična vrednost Studentovega kriterija za α =0,05 in f= n-1
V tem primeru je mogoče najti 99% IZ t izbran za α =0,01.
Kakšen je praktični pomen intervala zaupanja?
Širok interval zaupanja kaže, da povprečje vzorca ne odraža natančno povprečja populacije. To je običajno posledica premajhne velikosti vzorca ali njegove heterogenosti, tj. velika disperzija. Oba dajeta veliko napako v povprečju in temu primerno širši CI. In to je razlog, da se vrnemo k fazi načrtovanja raziskav.
Zgornje in spodnje meje intervala zaupanja ocenijo, ali bodo rezultati klinično pomembni
Oglejmo si podrobneje vprašanje statističnega in kliničnega pomena rezultatov študije skupinskih lastnosti. Spomnimo se, da je naloga statistike na podlagi vzorčnih podatkov zaznati vsaj nekatere razlike v splošnih populacijah. Naloga kliničnega zdravnika je najti takšne (ne kakršne koli) razlike, ki bodo pomagale pri diagnozi ali zdravljenju. In niso vedno statistični zaključki osnova za klinične zaključke. Tako statistično pomembno znižanje hemoglobina za 3 g/l ni razlog za skrb. In obratno, če neka težava v človeškem telesu nima množičnega značaja na ravni celotne populacije, to ni razlog, da se s to težavo ne bi ukvarjali.
|
To stališče bomo obravnavali v primer. Raziskovalce je zanimalo, ali fantje, ki so imeli kakšno nalezljivo bolezen, v rasti zaostajajo za svojimi vrstniki. V ta namen je bila izvedena selektivna študija, v kateri je sodelovalo 10 dečkov, ki so imeli to bolezen. Rezultati so predstavljeni v tabeli 23. Tabela 23. Statistični rezultati
Iz teh izračunov izhaja, da je selektivna povprečna višina 10-letnih dečkov, ki so preboleli kakšno nalezljivo bolezen, blizu normalne (132,5 cm). Vendar spodnja meja intervala zaupanja (126,6 cm) kaže, da obstaja 95-odstotna verjetnost, da prava povprečna višina teh otrok ustreza konceptu "nizke rasti", tj. ti otroci so zakrneli. V tem primeru so rezultati izračunov intervala zaupanja klinično pomembni. |
|||||||||||||||||||
Pogosto mora ocenjevalec analizirati trg nepremičnin tistega segmenta, v katerem se nahaja predmet ocenjevanja. Če je trg razvit, je lahko težko analizirati celoten nabor predstavljenih predmetov, zato se za analizo uporabi vzorec predmetov. Ta vzorec ni vedno homogen, včasih ga je treba očistiti ekstremov – previsokih ali prenizkih tržnih ponudb. V ta namen se uporablja interval zaupanja. Namen te študije je izvesti primerjalno analizo dveh metod za izračun intervala zaupanja in izbrati najboljšo možnost izračuna pri delu z različnimi vzorci v sistemu estimatica.pro.
Interval zaupanja - izračunan na podlagi vzorca interval vrednosti značilnosti, ki z znano verjetnostjo vsebuje ocenjeni parameter splošne populacije.
Smisel izračuna intervala zaupanja je v tem, da na podlagi vzorčnih podatkov zgradimo tak interval, da je mogoče z dano verjetnostjo trditi, da je vrednost ocenjenega parametra v tem intervalu. Z drugimi besedami, interval zaupanja z določeno verjetnostjo vsebuje neznano vrednost ocenjene količine. Čim širši je interval, večja je netočnost.
Obstajajo različne metode za določanje intervala zaupanja. V tem članku bomo obravnavali 2 načina:
- prek mediane in standardne deviacije;
- preko kritične vrednosti t-statistike (Studentov koeficient).
Faze primerjalne analize različnih metod za izračun CI:
1. oblikovati vzorec podatkov;
2. obdelamo ga s statističnimi metodami: izračunamo srednjo vrednost, mediano, varianco itd.;
3. izračunamo interval zaupanja na dva načina;
4. Analizirajte očiščene vzorce in dobljene intervale zaupanja.
Faza 1. Vzorčenje podatkov
Vzorec je bil oblikovan s sistemom estimatica.pro. Vzorec je vključeval 91 ponudb za prodajo 1-sobnih stanovanj v 3. cenovni coni z vrsto načrtovanja "Hruščov".
Tabela 1. Začetni vzorec
|
Cena 1 m2, c.u. |
|
Slika 1. Začetni vzorec

Faza 2. Obdelava začetnega vzorca
Obdelava vzorca s statističnimi metodami zahteva izračun naslednjih vrednosti:
1. Aritmetična sredina

2. Mediana - število, ki označuje vzorec: natanko polovica elementov vzorca je večja od mediane, druga polovica je manjša od mediane.
 (za vzorec z lihim številom vrednosti)
(za vzorec z lihim številom vrednosti)
3. Razpon - razlika med najvišjo in najmanjšo vrednostjo v vzorcu

4. Varianca – uporablja se za natančnejšo oceno variacije podatkov

5. Standardni odklon za vzorec (v nadaljevanju RSD) je najpogostejši pokazatelj razpršenosti prilagoditvenih vrednosti okoli aritmetične sredine.

6. Koeficient variacije - odraža stopnjo razpršenosti prilagoditvenih vrednosti

7. koeficient nihanja - odraža relativno nihanje ekstremnih vrednosti cen v vzorcu okoli povprečja

Tabela 2. Statistični kazalniki izvirnega vzorca
Koeficient variacije, ki označuje homogenost podatkov, je 12,29 %, vendar je koeficient nihanja prevelik. Tako lahko trdimo, da izvirni vzorec ni homogen, zato preidimo na izračun intervala zaupanja.
Faza 3. Izračun intervala zaupanja
Metoda 1. Izračun preko mediane in standardnega odklona.
Interval zaupanja se določi na naslednji način: najmanjša vrednost - standardni odklon se odšteje od mediane; največja vrednost - standardni odklon se doda mediani.

Tako je interval zaupanja (47179 CU; 60689 CU)
riž. 2. Vrednosti znotraj intervala zaupanja 1.

Metoda 2. Gradnja intervala zaupanja preko kritične vrednosti t-statistike (Studentov koeficient)
S.V. Gribovsky v knjigi "Matematične metode za ocenjevanje vrednosti premoženja" opisuje metodo za izračun intervala zaupanja s pomočjo Studentovega koeficienta. Pri izračunu po tej metodi mora cenilec sam nastaviti stopnjo pomembnosti ∝, ki določa verjetnost, s katero bo zgrajen interval zaupanja. Običajno se uporabljajo ravni pomembnosti 0,1; 0,05 in 0,01. Ustrezajo verjetnosti zaupanja 0,9; 0,95 in 0,99. S to metodo velja, da so prave vrednosti matematičnega pričakovanja in variance praktično neznane (kar je skoraj vedno res pri reševanju praktičnih problemov vrednotenja).
Formula intervala zaupanja:

n - velikost vzorca;
Kritična vrednost t-statistike (Studentove porazdelitve) s stopnjo pomembnosti ∝, številom prostostnih stopenj n-1, ki se določi s posebnimi statističnimi tabelami ali z uporabo MS Excel (→»Statistika«→ STUDRASPOBR);
∝ - stopnja pomembnosti, vzamemo ∝=0,01.

riž. 2. Vrednosti znotraj intervala zaupanja 2.

Korak 4. Analiza različnih načinov izračuna intervala zaupanja
Dve metodi izračuna intervala zaupanja - preko mediane in Studentovega koeficienta - sta privedli do različnih vrednosti intervalov. V skladu s tem sta bila pridobljena dva različna prečiščena vzorca.
Tabela 3. Statistični kazalniki za tri vzorce.
|
Kazalo |
Začetni vzorec |
1 možnost |
Možnost 2 |
|
Povprečna vrednost |
|||
|
Razpršenost |
|||
|
Coef. variacije |
|||
|
Coef. nihanja |
|||
|
Število upokojenih predmetov, kos. |
|||
Na podlagi opravljenih izračunov lahko rečemo, da se vrednosti intervalov zaupanja, pridobljene z različnimi metodami, sekajo, zato lahko po presoji ocenjevalca uporabite katero koli od metod izračuna.
Menimo pa, da je pri delu v sistemu estimatica.pro priporočljivo izbrati metodo za izračun intervala zaupanja, odvisno od stopnje razvitosti trga:
- če trg ni razvit, uporabite metodo izračuna prek mediane in standardne deviacije, saj je število upokojenih predmetov v tem primeru majhno;
- če je trg razvit, uporabite izračun preko kritične vrednosti t-statistike (Studentov koeficient), saj je možno oblikovati velik začetni vzorec.
Pri pripravi članka so bili uporabljeni:
1. Gribovsky S.V., Sivets S.A., Levykina I.A. Matematične metode za ocenjevanje vrednosti nepremičnin. Moskva, 2014
2. Podatki iz sistema estimatica.pro
Metoda ocenjevanja naključne napake temelji na načelih teorije verjetnosti in matematične statistike. Slučajno napako je mogoče oceniti le v primeru, ko so bile opravljene ponovne meritve iste količine.
Naj bo zaradi opravljenih meritev p količinske vrednosti X: X 1 , X 2 , …, x n. Označimo z aritmetično sredino
V teoriji verjetnosti je dokazano, da s povečanjem števila meritev p aritmetična sredina izmerjene vrednosti se približa pravi:
Z majhnim številom meritev ( p£ 10) se povprečna vrednost lahko bistveno razlikuje od prave. Da bi vedeli, kako natančno vrednost označuje izmerjeno vrednost, je treba določiti tako imenovani interval zaupanja dobljenega rezultata.
Ker absolutno natančna meritev ni mogoča, je verjetnost pravilnosti izjave " x ima vrednost, ki je popolnoma enaka» je enako nič. Verjetnost izjave x ima vrednost» je enako ena (100%). Tako je verjetnost pravilnosti katere koli vmesne trditve v območju od 0 do 1. Namen meritve je najti takšen interval, v katerem z vnaprej določeno verjetnostjo a(0 < a < 1) находится истинное значение измеряемой величины. Этот интервал называется interval zaupanja , in vrednost, ki je neločljivo povezana z njim a – stopnja zaupanja (oz faktor zanesljivosti). Povprečna vrednost, izračunana po formuli (3), se vzame kot sredina intervala. Polovica širine intervala zaupanja je naključna napaka D s x(slika 1).
 |
Očitno je širina intervala zaupanja (in s tem napaka D s x) odvisno od tega, koliko so posamezne meritve količine x i od srednje vrednosti. Za "razpršenost" merilnih rezultatov glede na povprečje je značilno koren srednje kvadratne napake s, ki ga najdemo s formulo
 , (4)
, (4)
Širina želenega intervala zaupanja je neposredno sorazmerna s korenom srednje kvadratne napake:
![]() . (5)
. (5)
Faktor sorazmernosti t n, a klical Študentski koeficient; odvisno od števila poskusov p in stopnjo zaupanja a.
Na sl. 1, a, b Jasno je prikazano, da je ob drugih enakih pogojih za povečanje verjetnosti, da prava vrednost pade v interval zaupanja, treba povečati širino slednjega (verjetnost "pokritja" vrednosti Xširši interval zgoraj). Zato vrednost t n, a bi morala biti večja, višja je stopnja zaupanja a.
Z večanjem števila poskusov se povprečna vrednost približuje pravi vrednosti; torej z enako verjetnostjo a interval zaupanja je lahko ožji (glej sliko 1, a, c). Tako z rastjo p koeficient sudenta bi se moral zmanjšati. Tabela vrednosti študentovega koeficienta glede na p in a naveden v dodatkih k temu priročniku.
Upoštevati je treba, da stopnja zaupanja nima nobene zveze s točnostjo merilnega rezultata. Vrednost a so določeni vnaprej na podlagi zahtev po njihovi zanesljivosti. V večini tehničnih poskusov in v laboratorijski praksi vrednost a je enak 0,95.
Izračun slučajne napake pri merjenju količine X izvajajo v naslednjem vrstnem redu:
1) izračuna se vsota izmerjenih vrednosti, nato pa se izračuna povprečna vrednost količine po formuli (3);
2) za vsakega jaz poskusu se izračuna razlika med izmerjenimi in povprečnimi vrednostmi ter kvadrat te razlike (odklon) (D x i) 2 ;
3) najde se vsota kvadratnih odstopanj in nato koren srednje kvadratne napake s po formuli (4);
4) glede na dano stopnjo zaupanja a in število poskusov p iz tabele na str. 149 prijav izbere ustrezno vrednost študentovega količnika t n, a in naključna napaka D s x po formuli (5).
Za udobje izračunov in preverjanje vmesnih rezultatov so podatki vneseni v tabelo, katere zadnji trije stolpci so izpolnjeni po vzorcu tabele 1.
Tabela 1
| Številka izkušenj | … | X | D X | (D X) 2 |
| … | ||||
| … | ||||
| … | … | |||
| p | … | |||
| S= | S= |
V vsakem posameznem primeru vrednost X ima določen fizični pomen in ustrezne merske enote. To je lahko na primer pospešek prostega pada g (gospa 2), viskoznost tekočine h (Pa×s) itd. Manjkajoči stolpci tabele. 1 lahko vsebuje vmesne izmerjene vrednosti, potrebne za izračun ustreznih vrednosti X.
Primer 1 Za določitev pospeška A gibi telesa merjeni čas t mimo njihove poti S brez začetne hitrosti. Z znano relacijo dobimo formulo za izračun
Rezultati meritev poti S in čas t so podani v drugem in tretjem stolpcu tabele. 2. Po izvedbi izračunov s formulo (6) izpolnimo
četrti stolpec z vrednostmi pospeška a i in poiščemo njihovo vsoto, ki jo zapišemo pod tem stolpcem v celici "S =". Nato izračunamo povprečno vrednost po formuli (3)
![]() .
.
tabela 2
| Številka izkušenj | S, m | t, c | A, gospa 2 | D A, gospa 2 | (D A) 2 , (gospa 2) 2 |
| 2,20 | 2,07 | 0,04 | 0,0016 | ||
| 2,68 | 1,95 | -0,08 | 0,0064 | ||
| 2,91 | 2,13 | 0,10 | 0,0100 | ||
| 3,35 | 1,96 | -0,07 | 0,0049 | ||
| S= | 8,11 | S= | 0,0229 |
Odštevanje od vsake vrednosti a i povprečje, poišči razlike D a i in jih dajte v peti stolpec tabele. S kvadriranjem teh razlik izpolnimo zadnji stolpec. Nato izračunamo vsoto kvadratov odstopanj in jo zapišemo v drugo celico "S =". Po formuli (4) določimo povprečno kvadratno napako:
 .
.
Glede na vrednost verjetnosti zaupanja a= 0,95, za število poskusov p= 4 iz tabele v prilogah (str. 149) izberite vrednost študentovega koeficienta t n, a= 3,18; s formulo (5) ocenimo naključno napako pri merjenju pospeška
D s a= 3,18×0,0437 » 0,139 ( gospa 2) .
Ocena intervalov zaupanja
Učni cilji
Statistika upošteva naslednje dve glavni nalogi:
Imamo neko oceno, ki temelji na vzorčnih podatkih, in želimo podati neko verjetnostno izjavo o tem, kje je prava vrednost parametra, ki se ocenjuje.
Imamo posebno hipotezo, ki jo je treba preizkusiti na podlagi vzorčnih podatkov.
V tej temi obravnavamo prvi problem. Uvedemo tudi definicijo intervala zaupanja.
Interval zaupanja je interval, ki je zgrajen okoli ocenjene vrednosti parametra in kaže, kje je prava vrednost ocenjenega parametra z vnaprej dano verjetnostjo.
Po preučevanju gradiva o tej temi boste:
izvedeti, kakšen je interval zaupanja ocene;
naučijo se razvrščati statistične probleme;
obvladajo tehniko konstruiranja intervalov zaupanja, tako z uporabo statističnih formul kot z uporabo programskih orodij;
naučijo se določiti zahtevane velikosti vzorcev za doseganje določenih parametrov točnosti statističnih ocen.
Porazdelitve značilnosti vzorcev
T-razdelitev
Kot je razloženo zgoraj, je porazdelitev naključne spremenljivke blizu standardizirane normalne porazdelitve s parametroma 0 in 1. Ker ne poznamo vrednosti σ, jo nadomestimo z neko oceno s. Količina ima že drugačno porazdelitev in sicer oz Študentska distribucija, ki je določen s parametrom n -1 (število prostostnih stopinj). Ta porazdelitev je blizu normalne porazdelitve (večji kot je n, bližje so porazdelitve).
Na sl. 95  Prikazana je študentova porazdelitev s 30 prostostnimi stopnjami. Kot lahko vidite, je zelo blizu normalne porazdelitve.
Prikazana je študentova porazdelitev s 30 prostostnimi stopnjami. Kot lahko vidite, je zelo blizu normalne porazdelitve.
Podobno kot funkciji za delo z normalno porazdelitvijo NORMDIST in NORMINV, obstajata tudi funkciji za delo s t-porazdelitvijo - STUDIST (TDIST) in STUDRASPBR (TINV). Primer uporabe teh funkcij je v datoteki STUDRIST.XLS (predloga in rešitev) in na sl. 96  .
.
Porazdelitve drugih značilnosti
Kot že vemo, za določitev točnosti ocene pričakovanja potrebujemo t-porazdelitev. Za oceno drugih parametrov, kot je varianca, so potrebne druge porazdelitve. Dve izmed njih sta F-distribucija in x 2 -razporeditev.
Interval zaupanja za srednjo vrednost
Interval zaupanja je interval, ki je zgrajen okoli ocenjene vrednosti parametra in kaže, kje je prava vrednost ocenjenega parametra z vnaprej dano verjetnostjo.
Pride do konstrukcije intervala zaupanja za srednjo vrednost na naslednji način:
Primer
Restavracija s hitro prehrano načrtuje razširitev ponudbe z novo vrsto sendvičev. Da bi ocenil povpraševanje po njem, namerava upravljavec naključno izbrati 40 obiskovalcev izmed tistih, ki so ga že preizkusili, in jih prositi, naj ocenijo svoj odnos do novega izdelka na lestvici od 1 do 10. Upravljavec želi oceniti pričakovano število točk, ki jih bo novi izdelek prejel, in zgraditi 95-odstotni interval zaupanja te ocene. Kako narediti? (glejte datoteko SANDWICH1.XLS (predloga in rešitev).
rešitev
Če želite rešiti to težavo, lahko uporabite. Rezultati so predstavljeni na sl. 97  .
.
Interval zaupanja za skupno vrednost
Včasih je treba glede na vzorčne podatke oceniti ne matematično pričakovanje, temveč skupno vsoto vrednosti. Na primer, v primeru revizorja je lahko zanimivo oceniti ne povprečno vrednost računa, temveč vsoto vseh računov.
Naj bo N skupno število elementov, n bo velikost vzorca, T 3 bo vsota vrednosti v vzorcu, T" bo ocena za vsoto celotne populacije, potem pa , interval zaupanja pa se izračuna po formuli , kjer je s ocena standardnega odklona za vzorec, je ocena povprečja za vzorec.
Primer
Recimo, da davčni urad želi oceniti znesek skupnih vračil davka za 10.000 davkoplačevalcev. Davkoplačevalec bodisi prejme povračilo bodisi plača dodatne davke. Poiščite 95-odstotni interval zaupanja za znesek povračila ob predpostavki velikosti vzorca 500 oseb (glejte datoteko REFUND AMOUNT.XLS (predloga in rešitev).
rešitev
V StatPro za ta primer ni posebnega postopka, vendar lahko vidite, da lahko meje dobite iz meja za povprečje z uporabo zgornjih formul (slika 98).  ).
).
Interval zaupanja za delež
Naj bo p pričakovani delež kupcev, pv pa ocena tega deleža, pridobljena iz vzorca velikosti n. Lahko se pokaže, da za dovolj velike  ocenjena porazdelitev bo blizu normalne s srednjo vrednostjo p in standardnim odklonom
ocenjena porazdelitev bo blizu normalne s srednjo vrednostjo p in standardnim odklonom ![]() . Standardna napaka ocene je v tem primeru izražena kot
. Standardna napaka ocene je v tem primeru izražena kot  , interval zaupanja pa kot
, interval zaupanja pa kot  .
.
Primer
Restavracija s hitro prehrano načrtuje razširitev ponudbe z novo vrsto sendvičev. Da bi ocenil povpraševanje po njem, je upravitelj naključno izbral 40 obiskovalcev izmed tistih, ki so ga že preizkusili, in jih prosil, naj ocenijo svoj odnos do novega izdelka na lestvici od 1 do 10. Vodja želi oceniti pričakovani delež kupcev, ki novi izdelek ocenijo z vsaj 6 točkami (pričakuje, da bodo ti kupci potrošniki novega izdelka).
rešitev
Na začetku ustvarimo nov stolpec na podlagi 1, če je bila ocena stranke več kot 6 točk, in 0 v nasprotnem primeru (glej datoteko SANDWICH2.XLS (predloga in rešitev).
1. metoda
Če preštejemo znesek 1, ocenimo delež in nato uporabimo formule.
Vrednost z cr je vzeta iz posebnih tabel normalne porazdelitve (na primer 1,96 za 95 % interval zaupanja).
Z uporabo tega pristopa in specifičnih podatkov za izdelavo 95-odstotnega intervala dobimo naslednje rezultate (slika 99).  ). Kritična vrednost parametra z cr je 1,96. Standardna napaka ocene je 0,077. Spodnja meja intervala zaupanja je 0,475. Zgornja meja intervala zaupanja je 0,775. Tako lahko vodja s 95-odstotno gotovostjo domneva, da bo odstotek kupcev, ki bodo novi izdelek ocenili s 6 točkami ali več, med 47,5 in 77,5.
). Kritična vrednost parametra z cr je 1,96. Standardna napaka ocene je 0,077. Spodnja meja intervala zaupanja je 0,475. Zgornja meja intervala zaupanja je 0,775. Tako lahko vodja s 95-odstotno gotovostjo domneva, da bo odstotek kupcev, ki bodo novi izdelek ocenili s 6 točkami ali več, med 47,5 in 77,5.
Metoda 2
To težavo je mogoče rešiti s standardnimi orodji StatPro. Če želite to narediti, zadostuje, da upoštevate, da delež v tem primeru sovpada s povprečno vrednostjo stolpca Vrsta. Naslednja prijava StatPro/Statistična inferenca/Analiza enega vzorca za izgradnjo intervala zaupanja za srednjo vrednost (ocena pričakovanja) za stolpec Vrsta. Rezultati, dobljeni v tem primeru, bodo zelo blizu rezultatom 1. metode (slika 99).
Interval zaupanja za standardni odklon
s se uporablja kot ocena standardnega odklona (formula je podana v razdelku 1). Funkcija gostote ocene s je funkcija hi-kvadrat, ki ima tako kot t-porazdelitev n-1 prostostnih stopenj. Obstajajo posebne funkcije za delo s to distribucijo CHI2DIST (CHIDIST) in CHI2OBR (CHIINV) .
Interval zaupanja v tem primeru ne bo več simetričen. Pogojna shema meja je prikazana na sl. 100 .
Primer
Stroj bi moral izdelovati dele s premerom 10 cm, vendar zaradi različnih okoliščin prihaja do napak. Kontrolorja kakovosti skrbita dve stvari: prvič, povprečna vrednost mora biti 10 cm; drugič, tudi v tem primeru, če so odstopanja velika, bo veliko podrobnosti zavrnjenih. Vsak dan naredi vzorec 50 delov (glej datoteko QUALITY CONTROL.XLS (predloga in rešitev). Kakšne zaključke lahko da tak vzorec?
rešitev
Konstruiramo 95-odstotne intervale zaupanja za povprečje in standardno deviacijo z uporabo StatPro/Statistical Inference/Analysis One-Sample(Slika 101  ).
).
Nadalje, ob predpostavki normalne porazdelitve premerov, izračunamo delež izdelkov z napako, pri čemer določimo največje odstopanje 0,065. Z uporabo zmožnosti iskalne tabele (primer dveh parametrov) sestavimo odvisnost odstotka zavrnitev od srednje vrednosti in standardnega odklona (slika 102  ).
).
Interval zaupanja za razliko dveh srednjih vrednosti
To je ena najpomembnejših aplikacij statističnih metod. Primeri situacije.
Vodja trgovine z oblačili bi rad vedel, koliko več ali manj povprečna nakupovalka zapravi v trgovini kot moški.
Letalski družbi letita na podobnih progah. Potrošniška organizacija želi primerjati razliko med povprečnimi pričakovanimi zamudami leta za obe letalski družbi.
Podjetje pošilja kupone za določene vrste blaga v enem mestu in ne pošilja v drugem. Upravitelji želijo primerjati povprečne nakupe teh artiklov v naslednjih dveh mesecih.
Prodajalec avtomobilov se na predstavitvah pogosto ukvarja s poročenimi pari. Da bi razumeli njihove osebne reakcije na predstavitev, se pari pogosto intervjuvajo ločeno. Vodja želi oceniti razlike v ocenah moških in žensk.
Primer neodvisnih vzorcev
Srednja razlika bo imela t-porazdelitev z n 1 + n 2 - 2 prostostnima stopnjama. Interval zaupanja za μ 1 - μ 2 je izražen z razmerjem:

To težavo je mogoče rešiti ne samo z zgornjimi formulami, ampak tudi s standardnimi orodji StatPro. Če želite to narediti, je dovolj, da se prijavite
Interval zaupanja za razliko med deleži
Naj bo matematično pričakovanje delnic. Naj bodo njihove vzorčne ocene zgrajene na vzorcih velikosti n 1 oziroma n 2. Nato je ocena razlike. Zato je interval zaupanja za to razliko izražen kot:
Tukaj je z cr vrednost, dobljena iz normalne porazdelitve posebnih tabel (na primer 1,96 za 95-odstotni interval zaupanja).
Standardna napaka ocene je v tem primeru izražena z razmerjem:
 .
.
Primer
V trgovini so se v pripravah na veliko razprodajo lotili naslednje marketinške raziskave. Izbranih je bilo 300 najboljših kupcev, ki so bili naključno razdeljeni v dve skupini po 150 članov. Vsem izbranim kupcem je bilo poslano vabilo k sodelovanju v razprodaji, le za člane prve skupine pa je bil priložen kupon s pravico do 5 % popusta. Med prodajo so bili evidentirani nakupi vseh 300 izbranih kupcev. Kako lahko vodja razlaga rezultate in presoja o učinkovitosti kuponiranja? (Glejte datoteko COUPONS.XLS (predloga in rešitev)).
rešitev
V našem konkretnem primeru jih je od 150 kupcev, ki so prejeli kupon za popust, 55 opravilo akcijski nakup, med 150, ki kupona niso prejeli, pa le 35 kupcev (slika 103).  ). Potem so vrednosti vzorčnih deležev 0,3667 oziroma 0,2333. In vzorčna razlika med njima je enaka 0,1333. Ob predpostavki 95 % intervala zaupanja dobimo iz tabele normalne porazdelitve z cr = 1,96. Izračun standardne napake vzorčne razlike je 0,0524. Končno dobimo, da je spodnja meja 95-odstotnega intervala zaupanja 0,0307, zgornja pa 0,2359. Dobljene rezultate lahko interpretiramo tako, da lahko na vsakih 100 kupcev, ki so prejeli kupon za popust, pričakujemo od 3 do 23 novih kupcev. Vendar je treba upoštevati, da ta ugotovitev sama po sebi še ne pomeni učinkovitosti uporabe kuponov (saj z zagotavljanjem popusta izgubljamo dobiček!). Dokažimo to na konkretnih podatkih. Recimo, da je povprečni znesek nakupa 400 rubljev, od tega 50 rubljev. obstaja dobiček trgovine. Potem je pričakovan dobiček na 100 kupcev, ki niso prejeli kupona, enak:
). Potem so vrednosti vzorčnih deležev 0,3667 oziroma 0,2333. In vzorčna razlika med njima je enaka 0,1333. Ob predpostavki 95 % intervala zaupanja dobimo iz tabele normalne porazdelitve z cr = 1,96. Izračun standardne napake vzorčne razlike je 0,0524. Končno dobimo, da je spodnja meja 95-odstotnega intervala zaupanja 0,0307, zgornja pa 0,2359. Dobljene rezultate lahko interpretiramo tako, da lahko na vsakih 100 kupcev, ki so prejeli kupon za popust, pričakujemo od 3 do 23 novih kupcev. Vendar je treba upoštevati, da ta ugotovitev sama po sebi še ne pomeni učinkovitosti uporabe kuponov (saj z zagotavljanjem popusta izgubljamo dobiček!). Dokažimo to na konkretnih podatkih. Recimo, da je povprečni znesek nakupa 400 rubljev, od tega 50 rubljev. obstaja dobiček trgovine. Potem je pričakovan dobiček na 100 kupcev, ki niso prejeli kupona, enak:
50 0,2333 100 \u003d 1166,50 rubljev.
Podobni izračuni za 100 kupcev, ki so prejeli kupon, dajejo:
30 0,3667 100 \u003d 1100,10 rubljev.
Zmanjšanje povprečnega dobička na 30 je razloženo z dejstvom, da bodo kupci, ki so prejeli kupon, z uporabo popusta v povprečju opravili nakup za 380 rubljev.
Tako končna ugotovitev kaže na neučinkovitost uporabe takih kuponov v tej konkretni situaciji.
Komentiraj. To težavo je mogoče rešiti s standardnimi orodji StatPro. Da bi to naredili, je dovolj, da ta problem zmanjšamo na problem ocenjevanja razlike dveh povprečij z metodo in nato uporabimo StatPro/Statistična inferenca/Analiza dveh vzorcev za izgradnjo intervala zaupanja za razliko med dvema srednjima vrednostma.
Nadzor intervala zaupanja
Dolžina intervala zaupanja je odvisna od naslednje pogoje:
neposredni podatki (standardni odklon);
stopnja pomembnosti;
Velikost vzorca.
Velikost vzorca za oceno povprečja
Najprej razmislimo o problemu v splošnem primeru. Vrednost polovice dolžine intervala zaupanja, ki nam je bil dan, označimo z B (slika 104).  ). Vemo, da je interval zaupanja za srednjo vrednost neke naključne spremenljivke X izražen kot
). Vemo, da je interval zaupanja za srednjo vrednost neke naključne spremenljivke X izražen kot ![]() , Kje
, Kje ![]() . Ob predpostavki:
. Ob predpostavki:
![]() in izrazimo n, dobimo.
in izrazimo n, dobimo.
Natančne vrednosti variance naključne spremenljivke X žal ne poznamo. Poleg tega ne poznamo vrednosti t cr, saj je odvisna od n skozi število prostostnih stopinj. V tej situaciji lahko storimo naslednje. Namesto variance s uporabimo neko oceno variance za nekatere razpoložljive realizacije proučevane naključne spremenljivke. Namesto vrednosti t cr uporabimo vrednost z cr za normalno porazdelitev. To je povsem sprejemljivo, saj sta funkciji gostote za normalno in t-porazdelitev zelo blizu (razen v primeru majhnega n). Tako ima želena formula obliko:
 .
.
Ker formula na splošno daje neceloštevilske rezultate, se za želeno velikost vzorca vzame zaokroževanje s presežkom rezultata.
Primer
Restavracija s hitro prehrano načrtuje razširitev ponudbe z novo vrsto sendvičev. Da bi ocenil povpraševanje po njem, upravitelj naključno izbere število obiskovalcev izmed tistih, ki so ga že preizkusili, in jih prosi, naj ocenijo svoj odnos do novega izdelka na lestvici od 1 do 10. Upravljavec želi oceniti pričakovano število točk, ki jih bo novi izdelek prejel, in zgraditi 95-odstotni interval zaupanja te ocene. Želi pa, da polovica širine intervala zaupanja ne presega 0,3. Koliko obiskovalcev potrebuje za anketo?
kot sledi:

Tukaj r ots je ocena ulomka p, B pa je dana polovica dolžine intervala zaupanja. Napihnjeno vrednost za n lahko dobite z uporabo vrednosti r ots= 0,5. V tem primeru dolžina intervala zaupanja ne bo presegla dane vrednosti B za nobeno pravo vrednost p.
Primer
Naj vodja iz prejšnjega primera načrtuje oceno deleža strank, ki imajo raje novo vrsto izdelka. Skonstruirati želi 90-odstotni interval zaupanja, katerega polovična dolžina je manjša ali enaka 0,05. Koliko strank je treba naključno vzorčiti?
rešitev
V našem primeru je vrednost z cr = 1,645. Zato se zahtevana količina izračuna kot  .
.
Če bi imel vodja razlog za domnevo, da je želena vrednost p na primer približno 0,3, potem bi z zamenjavo te vrednosti v zgornji formuli dobili manjšo vrednost naključnega vzorca, in sicer 228.
Formula za določitev velikosti naključnega vzorca v primeru razlike med dvema srednjima vrednostma zapisano kot:
 .
.
Primer
Neko računalniško podjetje ima center za pomoč uporabnikom. V zadnjem času se je povečalo število pritožb strank zaradi slabe kakovosti storitev. Servisni center zaposluje predvsem dve vrsti sodelavcev: tiste z malo izkušnjami, ki so opravili specialna izobraževanja, in tiste z bogatimi praktičnimi izkušnjami, ki pa niso opravili posebnih tečajev. Podjetje želi analizirati pritožbe strank v zadnjih šestih mesecih in primerjati njihovo povprečje na vsako od obeh skupin zaposlenih. Predpostavlja se, da bodo številke v vzorcih za obe skupini enake. Koliko zaposlenih mora biti vključenih v vzorec, da dobimo 95 % interval s polovično dolžino največ 2?
rešitev
Tukaj je σ ots ocena standardnega odklona obeh naključnih spremenljivk ob predpostavki, da sta blizu. Zato moramo pri naši nalogi nekako pridobiti to oceno. To je mogoče storiti na primer na naslednji način. Če pogledamo podatke o pritožbah strank v zadnjih šestih mesecih, lahko vodja opazi, da je na splošno med 6 in 36 pritožb na zaposlenega. Ker ve, da za normalno porazdelitev praktično vse vrednosti niso več kot tri standardne deviacije od povprečja, lahko razumno verjame, da:
Od tod σ ots = 5.
Če nadomestimo to vrednost v formulo, dobimo  .
.
Formula za določitev velikost naključnega vzorca v primeru ocenjevanja razlike med deleži izgleda kot:

Primer
Neko podjetje ima dve tovarni za proizvodnjo podobnih izdelkov. Vodja podjetja želi primerjati stopnje napak obeh tovarn. Po dostopnih podatkih je stopnja zavrnitve v obeh tovarnah od 3 do 5 %. Zgradil naj bi 99-odstotni interval zaupanja s polovično dolžino, ki ne presega 0,005 (ali 0,5 %). Koliko izdelkov je treba izbrati iz vsake tovarne?
rešitev
Tukaj sta p 1ot in p 2ot oceni dveh neznanih deležev zavrženih v 1. in 2. tovarni. Če damo p 1ots \u003d p 2ots \u003d 0,5, potem bomo dobili precenjeno vrednost za n. Ker pa imamo v našem primeru nekaj apriornih informacij o teh deležih, vzamemo zgornjo oceno teh deležev, in sicer 0,05. Dobimo
Ko so nekateri parametri populacije ocenjeni iz vzorčnih podatkov, je koristno zagotoviti ne le točkovno oceno parametra, ampak tudi interval zaupanja, ki kaže, kje bi lahko bila natančna vrednost ocenjenega parametra.
V tem poglavju smo se seznanili tudi s kvantitativnimi razmerji, ki nam omogočajo gradnjo takih intervalov za različne parametre; naučil načine za nadzor dolžine intervala zaupanja.
Opažamo tudi, da je problem ocenjevanja velikosti vzorca (problem načrtovanja eksperimenta) mogoče rešiti s standardnimi orodji StatPro, in sicer StatPro/Statistical Inference/Sample Size Selection.