Verteilungsgesetz einer diskreten Zufallsvariablen. Beispiele für Problemlösungen
Definition 3. X hat Normalverteilungsgesetz (Gausssches Gesetz), wenn seine Verteilungsdichte die Form hat:
wo m = M(x), σ 2 = D(x), σ > 0 .
Die Kurve des Normalverteilungsgesetzes heißt normale oder gaußsche Kurve(Abb. 6.7).
Normale Kurve symmetrisch um eine Gerade x = m, hat ein Maximum an der Stelle x = m, gleicht.
Die Verteilungsfunktion einer nach dem Normalgesetz verteilten Zufallsvariablen X wird durch die Laplace-Funktion Ф ( x) nach der Formel:
F ( x) ist die Laplace-Funktion.
Kommentar. Funktion Ф ( x) ist ungerade (Ф (- x) = -Ф ( x)), zusätzlich für x> 5 können wir annehmen Ф ( x) ≈ 1/2.
Die Wertetabelle der Funktion Ф ( x) ist im Anhang (Tabelle P 2.2) angegeben.
Verteilungsfunktionsdiagramm F(x) ist in Abb. 6.8.
Die Wahrscheinlichkeit, dass die Zufallsvariable X Werte annimmt, die zum Intervall gehören ( a; b) werden nach der Formel berechnet:
R(ein< x < b ) = .
Die Wahrscheinlichkeit, dass der Absolutwert der Abweichung einer Zufallsvariablen von ihrer mathematischen Erwartung kleiner als eine positive Zahl δ ist, berechnet sich nach der Formel:
P(| x -m | .
Insbesondere für m= 0 gilt die Gleichheit:
P(| x | .
Die Three-Sigma-Regel
Wenn eine Zufallsvariable x hat eine Normalverteilung mit Parametern m und σ, dann ist es praktisch sicher, dass seine Werte im Intervall enthalten sind ( m 3σ; m+ 3σ), da P(| x -m | = 0,9973.
Aufgabe 6.3. Zufallswert x normalverteilt mit mathematischem Erwartungswert 32 und Varianz 16. Finden Sie: a) die WahrF(x); X nimmt einen Wert aus dem Intervall (28; 38).
Lösung: Bedingung m= 32, σ 2 = 16, also σ = 4, dann
ein)
b) Verwenden wir die Formel:
R(ein< x )= .
Ersetzend ein= 28, B= 38, m= 32, σ = 4, wir erhalten
R(28< x < 38)= F (1,5) F (1)
Gemäß der Wertetabelle der Funktion Ф ( x) finden wir Ф (1,5) = 0,4332, Ф (1) = 0,3413.
Also die erforderliche Wahrscheinlichkeit:
P(28 Aufgaben 6.1.
Zufallswert x gleichmäßig im Intervall verteilt (-3; 5). Finden: a) Verteilungsdichte F(x);
b) Verteilungsfunktionen F(x);
c) numerische Merkmale; d) Wahrscheinlichkeit R(4<x<6). 6.2.
Zufallswert x gleichmäßig über das Segment verteilt. Finden: a) Verteilungsdichte F(x);
b) Verteilungsfunktion F(x);
c) numerische Merkmale; d) Wahrscheinlichkeit R(3≤x≤6). 6.3.
Auf der Autobahn ist eine automatische Ampel installiert, bei der ein grünes Licht für 2 Minuten, gelb für 3 Sekunden und rot für 30 Sekunden usw. Ein Auto fährt zu einem zufälligen Zeitpunkt die Autobahn entlang. Bestimmen Sie die Wahrscheinlichkeit, dass das Auto die Ampel passiert, ohne anzuhalten. 6.4.
U-Bahn-Züge fahren regelmäßig alle 2 Minuten. Der Fahrgast betritt den Bahnsteig zu einem zufälligen Zeitpunkt. Wie groß ist die Wahrscheinlichkeit, dass der Fahrgast länger als 50 Sekunden auf den Zug warten muss? Finden Sie den mathematischen Erwartungswert einer Zufallsvariablen x- die Wartezeit auf den Zug. 6.5.
Ermitteln Sie die Varianz und Standardabweichung der Exponentialverteilung, die durch die Verteilungsfunktion gegeben ist: 6.6.
Kontinuierliche Zufallsvariable x gegeben durch die Dichte der Wahrscheinlichkeitsverteilung: a) Wie lautet das Verteilungsgesetz der betrachteten Zufallsvariablen? b) Finden Sie die Verteilungsfunktion F(x) und numerische Eigenschaften der Zufallsvariablen x. 6.7.
Zufallswert x verteilt nach dem Exponentialgesetz, gegeben durch die Dichte der Wahrscheinlichkeitsverteilung: x nimmt einen Wert aus dem Intervall (2,5; 5). 6.8.
Kontinuierliche Zufallsvariable x verteilt nach dem durch die Verteilungsfunktion gegebenen Exponentialgesetz: Bestimmen Sie die Wahrscheinlichkeit, dass als Ergebnis des Tests x nimmt den Wert aus dem Segment. 6.9.
Der mathematische Erwartungswert und die Standardabweichung der normalverteilten Zufallsvariablen sind 8 bzw. 2. Finden Sie: a) Dichte Verteilung f(x); b) die Wahrscheinlichkeit, dass als Ergebnis des Tests x nimmt einen Wert aus dem Intervall (10; 14). 6.10.
Zufallswert x normalverteilt mit mathematischem Erwartungswert 3,5 und Varianz 0,04. Finden: a) Verteilungsdichte F(x); b) die Wahrscheinlichkeit, dass als Ergebnis des Tests x nimmt den Wert aus dem Segment. 6.11.
Zufallswert x normal verteilt mit m(x) =
0 und D(x)=
1. Welches der Ereignisse: | x|≤0,6 oder | x| ≥0,6 ist wahrscheinlicher? 6.12.
Zufallswert x normal verteilt mit m(x) =
0 und D(x)=
1. Aus welchem Intervall (-0.5; -0.1) oder (1; 2) nimmt er in einem Test einen Wert mit höherer Wahrscheinlichkeit an? 6.13.
Der aktuelle Kurs je Aktie kann nach dem Normalverteilungsgesetz modelliert werden mit m(x)=
10 Tage Einheiten und σ ( x) = 0,3 den. Einheiten Finden: a) die Wahrscheinlichkeit, dass der aktuelle Aktienkurs bei 9,8 den liegt. Einheiten bis 10,4 den. Einheiten; b) Verwenden der "Three-Sigma-Regel", um die Grenzen zu finden, in denen sich der aktuelle Aktienkurs befindet. 6.14.
Der Stoff wird ohne systematische Fehler gewogen. Zufällige Wägefehler unterliegen dem Normalgesetz mit einer Standardabweichung σ = 5g. Bestimmen Sie die Wahrscheinlichkeit, dass in vier unabhängigen Experimenten der Fehler bei drei Wägungen als absoluter Wert 3 g nicht überschreitet. 6.15.
Zufallswert x normal verteilt mit m(X) = 12.6. Die Wahrscheinlichkeit, dass eine Zufallsvariable das Intervall (11,4; 13,8) trifft, beträgt 0,6826. Finden Sie die Standardabweichung σ. 6.16.
Zufallswert x normal verteilt mit m(x) = 12 und D(x) = 36. Finden Sie das Intervall, in das die Zufallsvariable mit einer Wahrscheinlichkeit von 0,9973 als Ergebnis des Tests fällt x. 6.17.
Ein von einem Automaten hergestelltes Teil gilt als defekt, wenn die Abweichung x sein überwachter Parameter vom Nennwert überschreitet die Maßeinheit in Modul 2. Es wird angenommen, dass die Zufallsvariable x normal verteilt mit m(x) = 0 und σ ( x) = 0,7. Wie viel Prozent der defekten Teile gibt die Maschine aus? 3.18.
Parameter x Teile werden normal mit einem mathematischen Erwartungswert von 2, gleich dem Nennwert, und einer Standardabweichung von 0,014 verteilt. Finden Sie die Wahrscheinlichkeit, dass die Abweichung x des Nennmodulo darf 1 % des Nennwertes nicht überschreiten. Antworten v) m(x)=1, D(x) = 16/3, σ ( x) = 4 /, d) 1/8. v) m(x)=4,5, D(x) = 2, σ ( x) =, d) 3/5. 6.3.
40/51. 6.4.
7/12, m(x)=1. 6.5.
D(x) = 1/64, σ ( x)=1/8 6.6.
m(x)=1 , D(x) = 2, σ ( x)= 1 . 6.7.
P (2,5<x<5)=e -1 e -2 ≈0,2325 6.8.
P (2≤ x≤5)=0,252. B) R(10 < x < 14) ≈ 0,1574. B) R(3,1 ≤ x ≤ 3,7) ≈ 0,8185. 6.11.
|x|≥0,6. 6.12.
(-0,5; -0,1). 6.13.
a) P (9,8 ≤ X ≤ 10,4) ≈ 0,6562 6.14.
0,111. b) (9.1; 10.9). 6.15.
= 1,2. 6.16.
(-6; 30). 6.17.
0,4 %. - die Zahl der Jungen unter 10 Neugeborenen. Es ist ganz klar, dass diese Zahl im Voraus nicht bekannt ist und in den nächsten zehn Kindern, die dort geboren werden, möglicherweise: Oder Jungs - der eine und einzige der aufgeführten Optionen. Und um fit zu bleiben, ein bisschen Sportunterricht: - Weitsprungbereich (in einigen Einheiten). Auch der Sportmeister kann sie nicht vorhersagen :) Ihre Hypothese? 2) Kontinuierliche Zufallsvariable - nimmt alle numerische Werte aus einem endlichen oder unendlichen Bereich. Notiz
: In der Bildungsliteratur sind die Abkürzungen DSV und NSV beliebt Lassen Sie uns zuerst eine diskrete Zufallsvariable analysieren, dann - kontinuierlich. - Das Konformität zwischen den möglichen Werten dieser Größe und ihren Wahrscheinlichkeiten. Am häufigsten wird das Gesetz in eine Tabelle geschrieben: Und jetzt sehr wichtiger punkt: da die Zufallsvariable Notwendig werde akzeptieren eine der bedeutungen, dann bilden sich die entsprechenden Ereignisse ganze Gruppe und die Summe der Wahrscheinlichkeiten ihres Auftretens ist gleich eins: oder, falls zusammengeklappt geschrieben: Das Gesetz der Verteilung der Wahrscheinlichkeiten von Punkten, die auf einen Würfel fallen, lautet zum Beispiel wie folgt: Keine Kommentare. Sie haben vielleicht den Eindruck, dass eine diskrete Zufallsvariable nur "gute" ganzzahlige Werte annehmen kann. Zerstreuen wir die Illusion - sie können alles sein: Beispiel 1 Einige Spiele haben das folgende Gewinnverteilungsgesetz: ... von solchen Aufgaben hast du bestimmt schon lange geträumt :) Ich verrate dir ein Geheimnis - mich auch. Vor allem nach Abschluss der Arbeiten an Feldtheorie. Lösung: Da eine Zufallsvariable nur einen von drei Werten annehmen kann, bilden sich die entsprechenden Ereignisse ganze Gruppe, was bedeutet, dass die Summe ihrer Wahrscheinlichkeiten gleich eins ist: Wir werden den "Partisanen" entlarven: Kontrolle: Was nötig war, um überzeugt zu werden. Antworten: Es kommt nicht selten vor, dass das Verteilungsrecht eigenständig erstellt werden muss. Verwenden Sie dazu klassische Definition von Wahrscheinlichkeit, Multiplikations-/Additionssätze für Ereigniswahrscheinlichkeiten und andere Chips tervera: Beispiel 2 Die Schachtel enthält 50 Lottoscheine, von denen 12 gewinnen, 2 davon jeweils 1000 Rubel und der Rest jeweils 100 Rubel. Erstellen Sie das Verteilungsgesetz einer Zufallsvariablen - die Höhe der Auszahlung, wenn ein Los zufällig aus der Schachtel gezogen wird. Lösung: wie Sie bemerkt haben, ist es üblich, die Werte einer Zufallsvariablen in anzuordnen aufsteigende Reihenfolge... Daher beginnen wir mit dem kleinsten Gewinn, nämlich Rubel. Es gibt insgesamt 50 - 12 = 38 solcher Tickets, und klassische Definition: Der Rest der Fälle ist einfach. Die Wahrscheinlichkeit, Rubel zu gewinnen, beträgt: Check: - und das ist ein besonders angenehmer Moment solcher Aufgaben! Antworten: die erforderliche Verteilung der Auszahlung: Die nächste Aufgabe zur eigenständigen Lösung: Beispiel 3 Die Wahrscheinlichkeit, dass der Schütze das Ziel trifft, ist. Erstellen Sie das Verteilungsgesetz einer Zufallsvariablen - die Anzahl der Treffer nach 2 Schüssen. ... ich wusste, dass du ihn vermisst :) Denk dran Multiplikations- und Additionssätze... Lösung und Antwort am Ende der Lektion. Das Verteilungsgesetz beschreibt eine Zufallsvariable vollständig, aber in der Praxis ist es nützlich (und manchmal nützlicher), nur einen Teil davon zu kennen. numerische Eigenschaften
. In einfachen Worten ist es durchschnittlicher Erwartungswert mit mehrfacher Wiederholung von Prüfungen. Lassen Sie eine Zufallsvariable Werte mit Wahrscheinlichkeiten annehmen oder zusammengebrochen: Berechnen wir zum Beispiel die mathematische Erwartung einer Zufallsvariablen - die Anzahl der Punkte, die auf einen Würfel fallen: Erinnern wir uns nun an unser hypothetisches Spiel: Es stellt sich die Frage: Lohnt es sich, dieses Spiel überhaupt zu spielen? … Wer hat welche Eindrücke? Also doch "von der Hand" und Sie werden es nicht sagen! Aber diese Frage lässt sich leicht beantworten, indem man den Erwartungswert berechnet. gewichteter Durchschnitt nach den Gewinnwahrscheinlichkeiten: Somit ist die mathematische Erwartung dieses Spiels verlieren. Vertrauen Sie nicht den Eindrücken - vertrauen Sie den Zahlen! Ja, hier kann man 10 oder sogar 20-30 Mal hintereinander gewinnen, aber auf Dauer werden wir unweigerlich ruinieren. Und ich würde dir nicht raten, solche Spiele zu spielen :) Naja, vielleicht nur zum Spass. Aus all dem folgt, dass die mathematische Erwartung kein RANDOM-Wert mehr ist. Kreativer Auftrag zum Selbststudium: Beispiel 4 Herr X spielt europäisches Roulette nach folgendem System: setzt ständig 100 Rubel auf "Rot". Erstellen Sie das Verteilungsgesetz einer Zufallsvariablen - ihren Gewinn. Berechnen Sie die mathematische Erwartung eines Gewinns und runden Sie ihn auf die nächste Kopeke. wie viele im mittleren verliert der Spieler mit jeder hundert Wette? Hinweis
: Europäisches Roulette enthält 18 rote, 18 schwarze und 1 grüne Sektoren ("Null"). Bei einem „roten“ Treffer wird dem Spieler ein doppelter Einsatz ausbezahlt, ansonsten geht es um die Einnahmen des Casinos Es gibt viele andere Roulette-Spielsysteme, für die Sie Ihre eigenen Wahrscheinlichkeitstabellen erstellen können. Dies ist jedoch der Fall, wenn wir keine Verteilungsgesetze und -tabellen benötigen, da mit Sicherheit festgestellt wurde, dass die mathematische Erwartung des Spielers genau dieselbe ist. Von System zu System nur Änderungen 1.2.4. Zufallsvariablen und ihre Verteilungen Verteilungen von Zufallsvariablen und Verteilungsfunktionen... Die Verteilung einer numerischen Zufallsvariablen ist eine Funktion, die eindeutig die Wahrscheinlichkeit bestimmt, dass eine Zufallsvariable einen bestimmten Wert annimmt oder zu einem bestimmten bestimmten Intervall gehört. Die erste ist, wenn die Zufallsvariable eine endliche Anzahl von Werten annimmt. Dann ist die Verteilung gegeben durch die Funktion P (X = x), jeden möglichen Wert setzen x zufällige Variable x die Wahrscheinlichkeit, dass X = x. Zweitens, wenn die Zufallsvariable unendlich viele Werte annimmt. Dies ist nur möglich, wenn der Wahrscheinlichkeitsraum, auf dem die Zufallsvariable bestimmt wird, aus unendlich vielen Elementarereignissen besteht. Dann ist die Verteilung gegeben durch die Menge der Wahrscheinlichkeiten P (a <
x P (a <
x Diese Beziehung zeigt, dass sowohl die Verteilung aus der Verteilungsfunktion berechnet werden kann, als auch umgekehrt die Verteilungsfunktion - aus der Verteilung. Verteilungsfunktionen, die in probabilistisch-statistischen Methoden der Entscheidungsfindung und anderer angewandter Forschung verwendet werden, sind entweder diskret oder stetig oder deren Kombinationen. Diskrete Verteilungsfunktionen entsprechen diskreten Zufallsvariablen, die eine endliche Anzahl von Werten oder Werten aus einer Menge nehmen, deren Elemente mit natürlichen Zahlen umnummeriert werden können (solche Mengen werden in der Mathematik als abzählbar bezeichnet). Ihr Diagramm sieht aus wie eine Stufentreppe (Abb. 1). Beispiel 1. Nummer x fehlerhafte Produkte in der Charge nehmen mit einer Wahrscheinlichkeit von 0,3 den Wert 0, mit einer Wahrscheinlichkeit von 0,4 einen Wert von 1, mit einer Wahrscheinlichkeit von 0,2 einen Wert von 2 und mit einer Wahrscheinlichkeit von 0,1 den Wert 3 an. Der Graph der Verteilungsfunktion einer Zufallsvariablen x gezeigt in Abb. 1. Abb. 1. Der Graph der Verteilungsfunktion der Anzahl fehlerhafter Produkte. Stetige Verteilungsfunktionen haben keine Sprünge. Sie steigen mit steigendem Argument monoton an - von 0 at auf 1 at. Zufallsvariablen mit stetigen Verteilungsfunktionen werden als stetig bezeichnet. Stetige Verteilungsfunktionen, die in probabilistisch-statistischen Entscheidungsverfahren verwendet werden, haben Ableitungen. Erste Ableitung f(x) Verteilungsfunktionen F(x) die Wahrscheinlichkeitsdichte genannt, Aus der Wahrscheinlichkeitsdichte lässt sich die Verteilungsfunktion bestimmen: Für jede Verteilungsfunktion Die aufgeführten Eigenschaften von Verteilungsfunktionen werden in probabilistischen und statistischen Entscheidungsverfahren ständig verwendet. Insbesondere impliziert die letzte Gleichheit die konkrete Form der Konstanten in den unten betrachteten Formeln für die Wahrscheinlichkeitsdichten. Beispiel 2. Die folgende Verteilungsfunktion wird häufig verwendet: wo ein und B- einige Zahlen, ein ... Lassen Sie uns die Wahrscheinlichkeitsdichte dieser Verteilungsfunktion ermitteln: (in Punkten) x = a und x = b Ableitung einer Funktion F(x) existiert nicht). Eine Zufallsvariable mit Verteilungsfunktion (1) heißt „gleichmäßig verteilt auf der Strecke [ ein; B]». Gemischte Verteilungsfunktionen treten insbesondere dann auf, wenn Beobachtungen irgendwann aufhören. Zum Beispiel bei der Analyse statistischer Daten, die mit Zuverlässigkeitstestplänen gewonnen wurden, die den Abbruch von Tests nach einer bestimmten Zeit vorsehen. Oder bei der Analyse von Daten zu technischen Produkten, die eine Garantiereparatur erfordern. Beispiel 3. Angenommen, die Lebensdauer einer Glühbirne sei eine Zufallsvariable mit einer Verteilungsfunktion F(t), und die Prüfung wird vor dem Ausfall der Glühbirne durchgeführt, wenn dies weniger als 100 Stunden nach Beginn der Prüfung auftritt, oder bis zum Zeitpunkt t 0= 100 Stunden. Lassen G(t)- die Verteilungsfunktion der Betriebszeit der Glühbirne in gutem Zustand während dieser Prüfung. Dann Funktion G(t) hat einen Sprung in den Punkt t 0, da die entsprechende Zufallsvariable den Wert annimmt t 0 mit Wahrscheinlichkeit 1- F (t 0)> 0.
Eigenschaften von Zufallsvariablen. Bei probabilistischen und statistischen Entscheidungsverfahren werden eine Reihe von Merkmalen von Zufallsvariablen verwendet, die durch Verteilungsfunktionen und Wahrscheinlichkeitsdichte ausgedrückt werden. Bei der Beschreibung der Einkommensdifferenzierung, bei der Suche nach Konfidenzgrenzen für die Parameter von Verteilungen von Zufallsvariablen und in vielen anderen Fällen bei einem Konzept wie „Ordnungsquantil“ R», Wo 0< P < 1 (обозначается x p). Bestellmenge R Ist der Wert einer Zufallsvariablen, für die die Verteilungsfunktion den Wert . annimmt R oder es gibt einen "Sprung" von einem Wert kleiner R auf einen Wert größer als R(Abb. 2). Es kann vorkommen, dass diese Bedingung für alle Werte von x erfüllt ist, die zu diesem Intervall gehören (d. h. die Verteilungsfunktion ist auf diesem Intervall konstant und ist gleich R). Dann wird jeder dieser Werte ein "Quantil der Ordnung" genannt R". Für stetige Verteilungsfunktionen gibt es in der Regel ein einzelnes Quantil x p bestellen R(Abb. 2), und F (x p) = p. (2) Abb. 2. Quantildefinition x p bestellen R. Beispiel 4. Finde das Quantil x p bestellen R für die Verteilungsfunktion F(x) aus (1). Bei 0< P <
1 квантиль x p ergibt sich aus der Gleichung jene. x p
= a + p (b - a) = a ( 1- p) + bp... Beim P= 0 beliebig x <
ein ist ein Quantil der Ordnung P= 0. Ordnungsquantil P= 1 ist eine beliebige Zahl x >
B. Für diskrete Verteilungen gibt es in der Regel kein x p Gleichung (2) erfüllen. Genauer gesagt, wenn die Verteilung einer Zufallsvariablen in Tabelle 1 angegeben ist, wobei x 1< x 2 < … < x k
, dann Gleichheit (2), betrachtet als Gleichung für x p, hat nur Lösungen für k Werte P, nämlich, p = p 1, p = p 1 + p 2, p = p 1 + p 2 + p 3, p = p 1 + p 2 + ...+
p m, 3 <
m <
k,
P =
P 1
+
P 2
+ … +
p k.
Tabelle 1. Verteilung einer diskreten Zufallsvariablen Für die aufgeführten k Wahrscheinlichkeitswerte P Lösung x p Gleichung (2) ist nicht eindeutig, nämlich F(x) = p 1 + p 2 +… + p m für alle x so dass x m< x <
x m + 1. Jene. x p - eine beliebige Zahl aus dem Intervall (xm; xm + 1]. Für alle anderen R aus dem Intervall (0; 1), das nicht in der Liste (3) enthalten ist, erfolgt ein "Sprung" von einem Wert kleiner als R auf einen Wert größer als R... Nämlich, wenn p 1 + p 2 +… + p m dann xp = xm + 1. Die betrachtete Eigenschaft diskreter Verteilungen führt zu erheblichen Schwierigkeiten bei der tabellarischen Darstellung und Verwendung solcher Verteilungen, da es sich als unmöglich herausstellt, die typischen Zahlenwerte der Verteilungsmerkmale genau einzuhalten. Dies gilt insbesondere für die kritischen Werte und Signifikanzniveaus nichtparametrischer statistischer Tests (siehe unten), da die Verteilungen der Statistiken dieser Tests diskret sind. Das Quantil der Ordnung ist in der Statistik von großer Bedeutung. R= ½. Es heißt Median (einer Zufallsvariablen x oder seine Verteilungsfunktion F(x)) und bezeichnet Ich (X). In der Geometrie gibt es den Begriff "Median" - eine gerade Linie, die durch die Spitze eines Dreiecks verläuft und die gegenüberliegende Seite in zwei Hälften teilt. In der mathematischen Statistik halbiert der Median nicht die Seite eines Dreiecks, sondern die Verteilung einer Zufallsvariablen: Gleichheit F (x 0,5)= 0,5 bedeutet, dass die Wahrscheinlichkeit, links zu treffen x 0,5 und die Wahrscheinlichkeit, nach rechts zu kommen x 0,5(oder direkt in x 0,5) sind gleich und gleich ½, d.h. P(x < x 0,5) = P(x >
x 0,5) = ½. Der Median gibt das "Zentrum" der Verteilung an. Aus Sicht eines der modernen Konzepte - der Theorie stabiler statistischer Verfahren - ist der Median eine bessere Eigenschaft einer Zufallsvariablen als der mathematische Erwartungswert. Bei der Verarbeitung von Messergebnissen in einer Ordinalskala (siehe Kapitel Messtheorie) kann der Median verwendet werden, der mathematische Erwartungswert jedoch nicht. Ein Merkmal einer Zufallsvariablen wie ein Modus hat eine klare Bedeutung – der Wert (oder die Werte) einer Zufallsvariablen entspricht einem lokalen Maximum der Wahrscheinlichkeitsdichte für eine kontinuierliche Zufallsvariable oder einem lokalen Maximum der Wahrscheinlichkeit für eine diskrete Zufallsvariable . Wenn x 0- Modus einer Zufallsvariablen mit Dichte f(x), dann, wie aus der Differentialrechnung bekannt,. Eine Zufallsvariable kann viele Modi haben. Also für eine gleichmäßige Verteilung (1) jeder Punkt x so dass ein< x < b
, ist eine Mode. Dies ist jedoch eine Ausnahme. Die meisten Zufallsvariablen, die in der probabilistisch-statistischen Entscheidungsfindung und anderen angewandten Forschungen verwendet werden, haben einen Modus. Zufallsvariablen, Dichten, Verteilungen, die einen Modus haben, werden unimodal genannt. Die mathematische Erwartung für diskrete Zufallsvariablen mit endlich vielen Werten wird im Kapitel „Ereignisse und Wahrscheinlichkeiten“ diskutiert. Für eine stetige Zufallsvariable x erwarteter Wert M (X) erfüllt die Gleichheit was ein Analogon der Formel (5) aus Aussage 2 des Kapitels "Ereignisse und Wahrscheinlichkeiten" ist. Beispiel 5. Mathematischer Erwartungswert für eine gleichverteilte Zufallsvariable x gleich Für die in diesem Kapitel betrachteten Zufallsvariablen gelten all jene Eigenschaften mathematischer Erwartungen und Varianzen, die zuvor für diskrete Zufallsvariablen mit endlich vielen Werten betrachtet wurden. Beweise für diese Eigenschaften werden jedoch nicht vorgelegt, da sie ein tieferes Verständnis mathematischer Feinheiten erfordern, das für das Verständnis und die qualifizierte Anwendung probabilistisch-statistischer Entscheidungsverfahren nicht erforderlich ist. Kommentar. Dieses Lehrbuch vermeidet bewusst die mathematischen Feinheiten, die insbesondere mit den Konzepten der messbaren Mengen und messbaren Funktionen, der Ereignisalgebra usw. Wer diese Konzepte beherrschen möchte, muss auf Fachliteratur, insbesondere auf die Enzyklopädie, zurückgreifen. Jedes der drei Merkmale - mathematischer Erwartungswert, Median, Modus - beschreibt das "Zentrum" der Wahrscheinlichkeitsverteilung. Zentrum kann auf unterschiedliche Weise definiert werden - daher drei verschiedene Merkmale. Für eine wichtige Klasse von Verteilungen - symmetrisch unimodal - stimmen jedoch alle drei Eigenschaften überein. Verteilungsdichte f(x)- die Dichte der symmetrischen Verteilung, falls es eine Zahl gibt x 0 so dass Gleichheit (3) bedeutet, dass der Graph der Funktion y = f(x) symmetrisch um eine vertikale Linie durch das Symmetriezentrum x = x 0. Aus (3) folgt, dass die symmetrische Verteilungsfunktion die Beziehung Bei einer symmetrischen Verteilung mit einer Mode fallen der mathematische Erwartungswert, der Median und die Mode zusammen und sind gleich x 0. Am wichtigsten ist der Fall der Symmetrie um 0, d.h. x 0= 0. Dann werden (3) und (4) zu Gleichungen bzw. Die obigen Beziehungen zeigen, dass es nicht notwendig ist, symmetrische Verteilungen für alle x, es reicht, Tische zu haben für x >
x 0. Beachten wir eine weitere Eigenschaft symmetrischer Verteilungen, die in probabilistisch-statistischen Methoden der Entscheidungsfindung und anderer angewandter Forschung ständig verwendet wird. Für eine stetige Verteilungsfunktion P (| X | <
a) = P (-a <
x <
a) = F (a) - F (-a), wo F- Verteilungsfunktion einer Zufallsvariablen x... Wenn die Verteilungsfunktion F symmetrisch zu 0, d.h. Formel (6) gilt dafür, dann P (| X | <
a) = 2F (a) - 1.
Häufig wird eine andere Formulierung der betrachteten Aussage verwendet: if Sind und Quantile der Ordnung bzw. (siehe (2)) einer bezüglich 0 symmetrischen Verteilungsfunktion, dann folgt aus (6), dass Von den Eigenschaften der Position - mathematischer Erwartungswert, Median, Modus - wenden wir uns den Eigenschaften der Streuung einer Zufallsvariablen zu x: Varianz, Standardabweichung und Variationskoeffizient v... Die Definition und Eigenschaften der Varianz für diskrete Zufallsvariablen wurden im vorherigen Kapitel diskutiert. Für stetige Zufallsvariablen Die Standardabweichung ist die nicht negative Quadratwurzel der Varianz: Der Variationskoeffizient ist das Verhältnis der Standardabweichung zum mathematischen Erwartungswert: Der Variationskoeffizient wird angewendet, wenn M (X)> 0. Es misst die Streuung in relativen Einheiten, während die Standardabweichung in absoluten Einheiten angegeben ist. Beispiel 6. Für eine gleichverteilte Zufallsvariable x Finden Sie die Varianz, die Standardabweichung und den Variationskoeffizienten. Die Varianz ist gleich: Die Variablenersetzung ermöglicht das Schreiben von: wo C = (B –
ein)/
2. Folglich ist die Standardabweichung gleich und der Variationskoeffizient ist wie folgt: Für jede Zufallsvariable x drei weitere Größen bestimmen - zentriert Ja normalisiert V und gegeben U... Zentrierte Zufallsvariable Ja Ist die Differenz zwischen einer gegebenen Zufallsvariablen x und seine mathematische Erwartung M (X), jene. Ja = X - M (X). Der Erwartungswert einer zentrierten Zufallsvariablen Ja gleich 0 ist und die Varianz die Varianz der gegebenen Zufallsvariablen ist: M (Ja)
= 0, D(Ja) =
D(x).
Verteilungsfunktion F Y(x)
zentrierte Zufallsvariable Ja bezogen auf die Verteilungsfunktion F(x)
die ursprüngliche Zufallsvariable x Verhältnis: F Y(x) =
F(x +
m(x)).
Die Dichten dieser Zufallsvariablen erfüllen die Gleichheit f Ja(x) =
F(x +
m(x)).
Normalisierte Zufallsvariable V Ist das Verhältnis einer gegebenen Zufallsvariablen x zu seiner Standardabweichung, d.h. ... Mathematischer Erwartungswert und Varianz einer normalisierten Zufallsvariablen V ausgedrückt durch Eigenschaften x So: wo v- Variationskoeffizient der ursprünglichen Zufallsvariablen x... Für die Verteilungsfunktion F V(x)
und Dichte f V(x)
normalisierte Zufallsvariable V wir haben: wo F(x)
- die Verteilungsfunktion der ursprünglichen Zufallsvariablen x, ein F(x)
Ist seine Wahrscheinlichkeitsdichte. Reduzierte Zufallsvariable U Ist eine zentrierte und normalisierte Zufallsvariable: Für die reduzierte Zufallsvariable Normalisierte, zentrierte und reduzierte Zufallsvariablen werden sowohl in theoretischen Studien als auch in Algorithmen, Softwareprodukten, normativ-technischen und instruktionsmethodischen Dokumentationen ständig verwendet. Vor allem, weil die Gleichheiten Es werden Transformationen von Zufallsvariablen und ein allgemeinerer Plan verwendet. Also wenn Ja = Axt + B, wo ein und B- dann ein paar Zahlen Beispiel 7. Wenn, dann Ja Ist die reduzierte Zufallsvariable, und aus Formeln (8) werden Formeln (7). Mit jeder Zufallsvariablen x viele Zufallsvariablen können zugeordnet werden Ja gegeben durch die Formel Ja = Axt + B mit unterschiedlichen ein>
0 und B.
Dieses Set heißt Schuppenscherenfamilie erzeugt durch die Zufallsvariable x... Verteilungsfunktionen F Y(x)
bilden eine Skalenverschiebungsfamilie von Verteilungen, die durch die Verteilungsfunktion erzeugt wird F(x).
Anstatt Ja = Axt + B verwende oft Notation Nummer Mit heißt Verschiebungsparameter und die Zahl D- der Skalenparameter. Formel (9) zeigt, dass x- das Ergebnis der Messung einer bestimmten Größe - geht in Verfügen über- das Ergebnis der Messung des gleichen Wertes, wenn der Beginn der Messung auf den Punkt verschoben wird Mit und dann die neue Maßeinheit verwenden, in D mal größer als das alte. Für die Scale-Shift-Familie (9) wird die Verteilung X als Standard bezeichnet. In probabilistischen und statistischen Entscheidungsverfahren und anderer angewandter Forschung werden die Standardnormalverteilung, die Standardweibull-Gnedenko-Verteilung, die Standardgammaverteilung und andere verwendet (siehe unten). Andere Transformationen von Zufallsvariablen werden ebenfalls verwendet. Zum Beispiel für eine positive Zufallsvariable x sind am Überlegen Ja= lg x wo lg x- Dezimallogarithmus einer Zahl x... Gleichstellungskette F Y (x) = P ( lg x< x) = P(X
< 10x) = F ( 10x) verbindet Verteilungsfunktionen x und Ja. Bei der Verarbeitung von Daten werden die folgenden Merkmale einer Zufallsvariablen verwendet x als Momente der Ordnung Q, d.h. mathematische Erwartung einer Zufallsvariablen X q, Q= 1, 2, ... Der mathematische Erwartungswert selbst ist also ein Moment der Ordnung 1. Für eine diskrete Zufallsvariable ist das Moment der Ordnung Q kann berechnet werden als Für eine stetige Zufallsvariable Momente der Ordnung Q heißen auch die Anfangsmomente der Ordnung Q,
im Gegensatz zu verwandten Merkmalen - zentrale Momente der Ordnung Q,
gegeben durch die Formel Die Varianz ist also der zentrale Punkt der Ordnung 2. Normalverteilung und zentraler Grenzwertsatz. Bei probabilistischen und statistischen Entscheidungsverfahren spricht man oft von einer Normalverteilung. Manchmal versuchen sie, damit die Verteilung der Originaldaten zu modellieren (diese Versuche sind nicht immer gerechtfertigt - siehe unten). Noch wichtiger ist, dass viele Datenverarbeitungsmethoden darauf basieren, dass die berechneten Werte nahezu normale Verteilungen aufweisen. Lassen x 1
,
x 2
,…,
X nein m(X ich) =
m und Abweichungen D(X ich)
= , ich
= 1, 2,…, n, ... Wie aus den Ergebnissen des vorherigen Kapitels hervorgeht, Betrachten Sie die reduzierte Zufallsvariable U n für den Betrag Wie aus Formeln (7) folgt, m(U n)
= 0, D(U n)
= 1. (für identisch verteilte Begriffe). Lassen x 1
,
x 2
,…,
X nein, ... sind unabhängige gleichverteilte Zufallsvariablen mit mathematischen Erwartungen m(X ich) =
m und Abweichungen D(X ich)
= , ich
= 1, 2,…, n, ... Dann gibt es für jedes x einen Grenzwert wo F(x) Ist die Standardnormalverteilungsfunktion. Mehr zur Funktion F(x) - unten (lesen Sie "phi von x", weil F- Griechischer Großbuchstabe "phi"). Das Central Limit Theorem (CLT) trägt seinen Namen, weil es das zentrale, am häufigsten verwendete mathematische Ergebnis der Wahrscheinlichkeitstheorie und mathematischen Statistik ist. Die Geschichte des CLT dauert etwa 200 Jahre - von 1730, als der englische Mathematiker A. Moivre (1667-1754) die ersten Ergebnisse zum CLT veröffentlichte (siehe unten zum Theorem von Moivre-Laplace), bis in die zwanziger - dreißiger Jahre des zwanzigsten Jahrhunderts, als Finn J.W. Lindeberg, Franzose Paul Levy (1886-1971), Jugoslawe V. Feller (1906-1970), Russe A.Ya. Khinchin (1894-1959) und andere Wissenschaftler erhielten notwendige und hinreichende Bedingungen für die Gültigkeit des klassischen zentralen Grenzwertsatzes. Die Entwicklung des betrachteten Themas ist noch lange nicht stehen geblieben - es wurden Zufallsvariablen ohne Varianz untersucht, d.h. die für wen (Akademiker B.V. Gnedenko und andere), die Situation, in der Zufallsvariablen (genauer Zufallselemente) komplexerer Natur als Zahlen summiert werden (Akademiker Yu.V. Prokhorov, A.A. Borovkov und ihre Mitarbeiter) usw. .d. Verteilungsfunktion F(x) gegeben durch Gleichheit wo ist die Dichte der Standardnormalverteilung, die einen ziemlich komplizierten Ausdruck hat: Hier = 3,1415925 ... ist eine in der Geometrie bekannte Zahl, gleich dem Verhältnis von Umfang zu Durchmesser, e
= 2.718281828 ... - die Basis des natürlichen Logarithmus (um sich diese Zahl zu merken, beachten Sie, dass 1828 das Geburtsjahr des Schriftstellers Leo Tolstoi ist). Wie aus der mathematischen Analyse bekannt ist, Bei der Verarbeitung der Beobachtungsergebnisse wird die Normalverteilungsfunktion nicht mit den angegebenen Formeln berechnet, sondern mit speziellen Tabellen oder Computerprogrammen gefunden. Die besten russischen "Tabellen der mathematischen Statistik" wurden von korrespondierenden Mitgliedern der Akademie der Wissenschaften der UdSSR L.N. zusammengestellt. Bolschew und N. V. Smirnow. Die Form der Dichte der Standardnormalverteilung ergibt sich aus der mathematischen Theorie, die wir hier nicht betrachten können, sowie dem Beweis der CLT. Zur Veranschaulichung präsentieren wir kleine Tabellen der Verteilungsfunktion F(x)(Tabelle 2) und ihre Quantile (Tabelle 3). Funktion F(x) symmetrisch zu 0, was sich in Tabelle 2-3 widerspiegelt. Tabelle 2. Standardnormalverteilungsfunktion. Wenn eine Zufallsvariable x hat eine Verteilungsfunktion F(x), dann M (X) = 0, D(x)
= 1. Diese Aussage wird in der Wahrscheinlichkeitstheorie bewiesen, ausgehend von der Form der Wahrscheinlichkeitsdichte. Sie stimmt mit einer ähnlichen Aussage für die Eigenschaften der reduzierten Zufallsvariablen überein U n, was ganz natürlich ist, da die CLT behauptet, dass mit einer unendlichen Zunahme der Anzahl der Terme die Verteilungsfunktion U n tendiert zur SF(x), und für jeden x. Tisch 3. Quantile der Standardnormalverteilung. Bestellmenge R Bestellmenge R Wir führen das Konzept einer Familie von Normalverteilungen ein. Per Definition ist die Normalverteilung die Verteilung einer Zufallsvariablen x, für die die Verteilung der reduzierten Zufallsvariablen F(x). Wie aus den allgemeinen Eigenschaften von Scale-Shift-Verteilungsfamilien (siehe oben) folgt, ist die Normalverteilung die Verteilung einer Zufallsvariablen wo x- Zufallsvariable mit Verteilung F(X), darüber hinaus m =
m(Ja),
= D(Ja).
Normalverteilung mit Verschiebungsparametern m und Maßstab wird normalerweise bezeichnet n(m, )
(manchmal wird die Notation verwendet n(m, )
). Wie aus (8) folgt, ist die Wahrscheinlichkeitsdichte der Normalverteilung n(m, )
Es gibt Normalverteilungen bilden eine Scale-Shift-Familie. In diesem Fall ist der Skalenparameter D= 1 /, und der Verschiebungsparameter C = -
m/ . Für die Zentralmomente dritter und vierter Ordnung der Normalverteilung gelten die Gleichungen Diese Gleichheiten liegen den klassischen Methoden der Überprüfung zugrunde, dass die Ergebnisse von Beobachtungen einer Normalverteilung gehorchen. Derzeit wird in der Regel empfohlen, die Normalität anhand des Kriteriums zu prüfen W Shapiro - Wilk. Das Problem der Überprüfung der Normalität wird unten diskutiert. Wenn Zufallsvariablen X 1 und X 2 haben Verteilungsfunktionen n(m 1
, 1)
und n(m 2
, 2)
dementsprechend dann X 1+ X 2 hat Verbreitung hat Verbreitung n(m, )
... Diese Eigenschaften der Normalverteilung werden in verschiedenen probabilistischen und statistischen Entscheidungsverfahren, insbesondere in der statistischen Regelung technologischer Prozesse und in der statistischen Akzeptanzkontrolle nach quantitativen Kriterien, ständig genutzt. Mit Hilfe der Normalverteilung werden drei Verteilungen ermittelt, die derzeit häufig in der statistischen Datenverarbeitung verwendet werden. Verteilung (chi - Quadrat) - Verteilung einer Zufallsvariablen wobei die Zufallsvariablen x 1
,
x 2
,…,
X nein unabhängig und haben die gleiche Verteilung n(0,1). Darüber hinaus ist die Anzahl der Begriffe, d.h. n wird die "Anzahl der Freiheitsgrade" der Chi-Quadrat-Verteilung genannt. Verteilung T Student's t ist die Verteilung einer Zufallsvariablen wobei die Zufallsvariablen U und x unabhängig, U hat eine Standardnormalverteilung n(0,1), und x- Chi-Verteilung - Quadrat mit
n Freiheitsgrade. Dabei n wird die "Anzahl der Freiheitsgrade" der Student-Verteilung genannt. Diese Verteilung wurde 1908 von dem englischen Statistiker W. Gosset eingeführt, der in einer Bierfabrik arbeitete. In dieser Fabrik wurden probabilistisch-statistische Methoden verwendet, um wirtschaftliche und technische Entscheidungen zu treffen, daher verbot die Geschäftsführung V. Gosset, wissenschaftliche Artikel unter eigenem Namen zu veröffentlichen. Auf diese Weise wurden Betriebsgeheimnisse, "Know-how" in Form von probabilistisch-statistischen Verfahren, die von V. Gosset entwickelt wurden, geschützt. Er hatte jedoch die Möglichkeit, unter dem Pseudonym „Student“ zu veröffentlichen. Die Gossett-Student-Geschichte zeigt, dass den Managern Großbritanniens noch weitere hundert Jahre die große wirtschaftliche Effizienz probabilistisch-statistischer Entscheidungsmethoden klar war. Die Fisher-Verteilung ist die Verteilung einer Zufallsvariablen wobei die Zufallsvariablen X 1 und X 2 unabhängig und haben Chi-Quadrat-Verteilungen mit der Anzahl der Freiheitsgrade k 1
und k 2
bzw. In diesem Fall ist das Paar (k 1
,
k 2
)
- ein Paar von "Zahlen von Freiheitsgraden" der Fisher-Verteilung, nämlich k 1
Ist die Anzahl der Freiheitsgrade des Zählers und k 2
- die Anzahl der Freiheitsgrade des Nenners. Die Verteilung der Zufallsvariablen F ist nach dem großen englischen Statistiker R. Fisher (1890-1962) benannt, der sie in seinen Werken aktiv verwendet hat. Ausdrücke für die Verteilungsfunktionen chi - quadrat, Student und Fisher, deren Dichten und Charakteristiken sowie Tabellen finden sich in der Fachliteratur (siehe zB). Wie bereits erwähnt, werden Normalverteilungen heute häufig in probabilistischen Modellen in verschiedenen Anwendungsgebieten verwendet. Was ist der Grund für ein so weit verbreitetes Auftreten dieser zweiparametrigen Verteilungsfamilie? Es wird durch den folgenden Satz verdeutlicht. Zentraler Grenzwertsatz(für unterschiedlich verteilte Begriffe). Lassen x 1
,
x 2
,…,
X nein, ... sind unabhängige Zufallsvariablen mit mathematischen Erwartungen M (x 1
), M (x 2
), ..., M (x n), ... und Abweichungen D(x 1
),
D(x 2
),…,
D(x n), ... bzw. Lassen Dann, unter bestimmten Bedingungen, die sicherstellen, dass der Beitrag einer der Bedingungen zu U n, für jeden x. Die fraglichen Bedingungen werden hier nicht formuliert. Sie sind in der Fachliteratur zu finden (siehe zB). "Die Aufklärung der Bedingungen, unter denen das CPT arbeitet, ist den herausragenden russischen Wissenschaftlern A. A. Markov (1857-1922) und insbesondere A. M. Lyapunov (1857-1918) zu verdanken." Der zentrale Grenzwertsatz zeigt, dass für den Fall, dass das Ergebnis einer Messung (Beobachtung) unter dem Einfluss vieler Gründe aufsummiert wird, jeder von ihnen nur einen kleinen Beitrag leistet und die kumulierte Summe bestimmt wird additiv, d.h. außerdem ist die Verteilung des Mess-(Beobachtungs-)Ergebnisses nahezu normal. Es wird manchmal angenommen, dass es für eine normale Verteilung ausreicht, dass das Ergebnis der Messung (Beobachtung) x entsteht unter dem Einfluss vieler Gründe, von denen jeder eine kleine Wirkung hat. Das ist nicht so. Es ist wichtig, wie diese Gründe funktionieren. Wenn es additiv ist, dann x hat eine ungefähr normale Verteilung. Wenn multiplikativ(d.h. die Wirkungen einzelner Ursachen werden multipliziert, nicht addiert), dann die Verteilung x nah nicht an normal, sondern an den sogenannten. logarithmisch normal, d.h. nicht x und lg X hat eine ungefähr normale Verteilung. Wenn kein Grund zu der Annahme besteht, dass einer dieser beiden Mechanismen zur Bildung des Endergebnisses (oder ein anderer ganz bestimmter Mechanismus) wirksam ist, dann über die Verteilung x kann nichts Bestimmtes gesagt werden. Aus dem Gesagten folgt, dass bei einem konkreten Anwendungsproblem die Normalität von Messergebnissen (Beobachtungen) in der Regel nicht aus allgemeinen Erwägungen festgestellt werden kann, sondern anhand statistischer Kriterien überprüft werden sollte. Oder verwenden Sie nichtparametrische statistische Methoden, die nicht auf der Annahme beruhen, dass die Verteilungsfunktionen von Messergebnissen (Beobachtungen) zu der einen oder anderen parametrischen Familie gehören. Kontinuierliche Verteilungen, die in probabilistisch-statistischen Entscheidungsverfahren verwendet werden. Neben der Scale-Shift-Familie der Normalverteilungen werden eine Reihe anderer Verteilungsfamilien häufig verwendet - logarithmisch normale, exponentielle, Weibull-Gnedenko-, Gammaverteilungen. Betrachten wir diese Familien. Zufallswert x hat eine logarithmische Normalverteilung, wenn die Zufallsvariable Ja= lg x hat eine Normalverteilung. Dann Z= ln x = 2,3026…Ja hat auch eine Normalverteilung
n(ein 1
, 1) wo ln x- natürlicher Logarithmus x... Die Dichte der Lognormalverteilung ist wie folgt: Aus dem zentralen Grenzwertsatz folgt, dass das Produkt x =
x 1
x 2
…
X nein unabhängige positive Zufallsvariablen X ich,
ich = 1, 2,…, n, für große n
kann durch eine logarithmische Normalverteilung angenähert werden. Insbesondere das multiplikative Modell der Lohn- bzw. Einkommensbildung führt zu einer Empfehlung, die Verteilung von Löhnen und Einkommen mit logarithmisch normalen Gesetzen anzunähern. Für Russland erwies sich diese Empfehlung als gerechtfertigt – die Statistiken bestätigen dies. Es gibt andere Wahrscheinlichkeitsmodelle, die zu einem Log-Normalgesetz führen. Ein klassisches Beispiel für ein solches Modell liefert A. N. Kolmogorov, der aus einem physikalisch begründeten System von Postulaten die Schlussfolgerung ableitete, dass die Partikelgröße beim Zerkleinern von Erzklumpen, Kohle usw. auf Kugelmühlen haben eine lognormale Verteilung. Kommen wir zu einer anderen Familie von Verteilungen, die in verschiedenen probabilistisch-statistischen Methoden der Entscheidungsfindung und anderen angewandten Forschung weit verbreitet ist - der Familie der Exponentialverteilungen. Beginnen wir mit einem probabilistischen Modell, das zu solchen Verteilungen führt. Betrachten Sie dazu den "Fluss der Ereignisse", d.h. eine Abfolge von Ereignissen, die zu einem bestimmten Zeitpunkt nacheinander auftreten. Beispiele umfassen: Anruffluss in einer Telefonzentrale; der Fluss von Geräteausfällen in der technologischen Kette; der Fluss von Produktfehlern während der Produktprüfung; der Fluss von Kundenanfragen an die Bankfiliale; der Strom von Käufern, die Waren und Dienstleistungen beantragen usw. In der Theorie der Ereignisströme gilt ein dem zentralen Grenzwertsatz ähnliches Theorem, das sich jedoch nicht mit der Summation von Zufallsvariablen, sondern mit der Summation der Ereignisströme befasst. Es wird ein Gesamtfluss betrachtet, der sich aus einer Vielzahl unabhängiger Flüsse zusammensetzt, von denen keiner einen überwiegenden Einfluss auf den Gesamtfluss hat. Zum Beispiel besteht der Fluss von Anrufen, die an einer Telefonvermittlungsstelle ankommen, aus einer großen Anzahl unabhängiger Anrufflüsse, die von einzelnen Teilnehmern stammen. Es ist bewiesen, dass in Fällen, in denen die Eigenschaften der Flüsse nicht von der Zeit abhängen, der Gesamtfluss vollständig durch eine Zahl beschrieben wird – die Flussrate. Betrachten Sie für den Gesamtfluss eine Zufallsvariable x- die Länge des Zeitintervalls zwischen aufeinanderfolgenden Ereignissen. Seine Verteilungsfunktion hat die Form Diese Verteilung wird Exponentialverteilung genannt, weil die Exponentialfunktion ist in Formel (10) beteiligt e -λ
x... Die Größe 1 / λ ist der Skalenparameter. Manchmal wird auch ein Verschiebungsparameter eingeführt Mit, exponentiell ist die Verteilung einer Zufallsvariablen X + c wo die Verteilung x ist durch Formel (10) gegeben. Exponentialverteilungen sind ein Spezialfall der sogenannten. Weibull - Gnedenko-Verteilungen. Sie sind nach dem Ingenieur V. Weibull benannt, der diese Verteilungen in die Praxis der Analyse der Ergebnisse von Ermüdungsversuchen einführte, und dem Mathematiker BV Gnedenko (1912-1995), der solche Verteilungen als limitierende Verteilungen bei der Untersuchung des Maximums des Tests erhielt Ergebnisse. Lassen x- eine Zufallsvariable, die die Dauer der Funktionsfähigkeit eines Produkts, eines komplexen Systems, eines Elements (dh einer Ressource, Betriebszeit bis zu einem Grenzzustand usw.), die Dauer des Betriebs eines Unternehmens oder die Lebensdauer eines Lebewesen usw. Ausfallrate spielt eine wichtige Rolle wo F(x)
und F(x)
- Verteilungsfunktion und Dichte einer Zufallsvariablen x. Beschreiben wir das typische Verhalten der Ausfallrate. Das gesamte Zeitintervall kann in drei Perioden unterteilt werden. Auf der ersten ist die Funktion λ (x) hat hohe Werte und eine klare Tendenz zur Abnahme (meistens nimmt sie monoton ab). Dies kann durch das Vorhandensein von Produkteinheiten mit offensichtlichen und latenten Mängeln in der betrachteten Charge erklärt werden, die zu einem relativ schnellen Ausfall dieser Produkteinheiten führen. Die erste Periode wird als "Einlauf" (oder "Einlauf") bezeichnet. Für ihn gilt in der Regel die Gewährleistungsfrist. Daran schließt sich ein Zeitraum des Normalbetriebs an, der durch eine annähernd konstante und relativ geringe Ausfallrate gekennzeichnet ist. Die Art der Ausfälle während dieses Zeitraums ist plötzlicher Art (Unfälle, Fehler von Bedienungspersonal usw.) und hängt nicht von der Betriebsdauer einer Produktionseinheit ab. Schließlich ist die letzte Betriebsperiode die Zeit der Alterung und des Verschleißes. Die Art der Ausfälle während dieser Zeit besteht in irreversiblen physikalischen, mechanischen und chemischen Veränderungen der Materialien, die zu einer fortschreitenden Verschlechterung der Qualität einer Produktionseinheit und ihrem endgültigen Ausfall führen. Jede Periode hat ihre eigene Art von Funktion λ (x)... Betrachten Sie eine Klasse von Machtabhängigkeiten λ (х) = λ 0bx b -1
,
(12) wo λ 0 >
0 und B> 0 - einige numerische Parameter. Die Werte B < 1, B= 0 und B> 1 entsprechen der Art der Ausfallrate während der Zeiträume Einlauf, Normalbetrieb bzw. Alterung. Beziehung (11) bei einer gegebenen Ausfallrate λ (x)- Differentialgleichung bezüglich der Funktion F(x).
Aus der Theorie der Differentialgleichungen folgt Durch Einsetzen von (12) in (13) erhalten wir, dass Die durch Formel (14) gegebene Verteilung wird Weibull-Gnedenko-Verteilung genannt. Soweit dann folgt aus Formel (14), dass die Menge ein durch Formel (15) gegeben ist der Skalenparameter. Manchmal wird auch ein Verschiebungsparameter eingeführt, d.h. Weibull - Gnedenko-Verteilungsfunktionen heißen F(x - C), wo F(x) ist durch Formel (14) für einige λ 0 und B. Die Dichte der Weibull-Gnedenko-Verteilung hat die Form wo ein> 0 - Skalenparameter, B> 0 - Formparameter, Mit ist der Verschiebungsparameter. In diesem Fall ist der Parameter ein aus Formel (16) bezieht sich auf den Parameter λ
0 aus Formel (14) durch die in Formel (15) angegebene Beziehung. Die Exponentialverteilung ist ein ganz besonderer Fall der Weibull-Gnedenko-Verteilung, entsprechend dem Wert des Formparameters B = 1. Die Weibull-Gnedenko-Verteilung wird auch verwendet, um probabilistische Modelle von Situationen zu konstruieren, in denen das Verhalten eines Objekts durch das "schwächste Glied" bestimmt wird. Dies impliziert eine Analogie zu einer Kette, deren Sicherheit durch das Glied mit der geringsten Festigkeit bestimmt wird. Mit anderen Worten, lass x 1
,
x 2
,…,
X nein- unabhängige gleichverteilte Zufallsvariablen, X (1)= min ( X 1, X 2, ..., X n), X(n)= max ( X 1, X 2, ..., X n). Bei einer Reihe von Anwendungsproblemen spielt eine wichtige Rolle x(1)
und x(n)
, insbesondere bei der Untersuchung der maximal möglichen Werte ("Aufzeichnungen") bestimmter Werte, zum Beispiel Versicherungszahlungen oder Verluste aufgrund kommerzieller Risiken, bei der Untersuchung der Elastizitäts- und Dauerfestigkeitsgrenzen von Stahl, einer Reihe von Zuverlässigkeitsmerkmalen usw . Es wird gezeigt, dass für große n die Verteilungen x(1)
und x(n)
, werden in der Regel durch die Weibull-Gnedenko-Verteilungen gut beschrieben. Grundlegender Beitrag zum Studium der Verteilungen x(1)
und x(n)
eingeführt von dem sowjetischen Mathematiker B.V. Gnedenko. Die Nutzung der gewonnenen Ergebnisse in Wirtschaft, Management, Technik und anderen Bereichen ist Gegenstand der Arbeiten von V. Weibull, E. Gumbel, V.B. Nevzorova, E. M. Kudlaev und viele andere Spezialisten. Kommen wir zur Familie der Gammaverteilungen. Sie finden breite Anwendung in Wirtschaft und Management, Theorie und Praxis der Zuverlässigkeit und Prüfung, in verschiedenen Bereichen der Technik, Meteorologie usw. Insbesondere unterliegt die Gammaverteilung in vielen Situationen Größen wie der Gesamtlebensdauer des Produkts, der Länge der Kette der leitfähigen Staubpartikel, der Zeit, die das Produkt benötigt, um den Grenzzustand während der Korrosion zu erreichen, und die Betriebszeit bis k Verweigerung, k= 1, 2, ... usw. Die Lebenserwartung von Patienten mit chronischen Erkrankungen, die Zeit, um während der Behandlung einen bestimmten Effekt zu erzielen, haben in einigen Fällen eine Gammaverteilung. Diese Verteilung ist am besten geeignet, um die Nachfrage in ökonomischen und mathematischen Modellen der Warenwirtschaft (Logistik) zu beschreiben. Die Dichte der Gammaverteilung hat die Form Die Wahrscheinlichkeitsdichte in Formel (17) wird durch drei Parameter bestimmt ein,
B,
C, wo ein>0, B> 0. Dabei ein ist ein Formularparameter, B- der Skalenparameter und Mit- der Verschiebungsparameter. Faktor 1 / Γ (a) wird normalisiert, es wird eingeführt in Hier Γ (a)- eine der in der Mathematik verwendeten Sonderfunktionen, die sogenannte "Gamma-Funktion", nach der auch die durch Formel (17) gegebene Verteilung benannt ist, Mit einem festen ein Formel (17) definiert die Skalenverschiebungsfamilie der Verteilungen, die durch die Verteilung mit der Dichte Die Verteilung der Form (18) wird als Standard-Gamma-Verteilung bezeichnet. Es ergibt sich aus Formel (17) at B= 1 und Mit= 0. Ein Sonderfall von Gammaverteilungen für ein= 1 sind die Exponentialverteilungen (mit = 1 /B). Mit natürlichem ein und Mit= 0 Gammaverteilungen werden Erlang-Verteilungen genannt. Aus den Werken des dänischen Wissenschaftlers K.A. Erlang (1878-1929), eines Angestellten der Kopenhagener Telefongesellschaft, der 1908-1922 studierte. mit dem Funktionieren von Telefonnetzen begann die Entwicklung der Theorie der Warteschlangen. Diese Theorie beschäftigt sich mit der probabilistisch-statistischen Modellierung von Systemen, in denen der Fluss von Anwendungen bedient wird, um optimale Entscheidungen zu treffen. Erlang-Verteilungen werden in den gleichen Anwendungsgebieten verwendet wie Exponentialverteilungen. Dem liegt folgende mathematische Tatsache zugrunde: die Summe von k unabhängigen Zufallsvariablen exponentiell verteilt mit den gleichen Parametern λ und Mit, hat eine Gammaverteilung mit dem Formparameter a =k, der Skalenparameter B= 1 / λ und der Verschiebungsparameter kc... Beim Mit= 0 erhalten wir die Erlang-Verteilung. Wenn eine Zufallsvariable x hat eine Gammaverteilung mit einem Formparameter ein so dass D = 2
ein- ganze Zahl, B= 1 und Mit= 0, dann 2 x hat eine Chi-Quadrat-Verteilung mit D Freiheitsgrade. Zufallswert x mit gvmma-Verteilung hat die folgenden Eigenschaften: Erwarteter Wert M (X) =ab +
C, Abweichung D(x) =
σ
2
=
ab 2
, Der Variationskoeffizient Asymmetrie Überschuss Die Normalverteilung ist der Grenzfall der Gammaverteilung. Genauer gesagt sei Z eine Zufallsvariable mit der durch Formel (18) gegebenen Standard-Gammaverteilung. Dann für jede reelle Zahl x, wo F(x)- Standard-Normalverteilungsfunktion n(0,1). In der angewandten Forschung werden auch andere parametrische Verteilungsfamilien verwendet, von denen die bekanntesten die Pearson-Kurven, die Edgeworth- und die Charlier-Reihe sind. Sie werden hier nicht abgedeckt. Diskret Verteilungen, die in probabilistischen und statistischen Entscheidungsverfahren verwendet werden. Die am häufigsten verwendeten sind drei Familien diskreter Verteilungen - binomial, hypergeometrisch und Poisson, sowie einige andere Familien - geometrisch, negativ binomial, multinomial, negativ hypergeometrisch usw. Wie bereits erwähnt erfolgt die Binomialverteilung in unabhängigen Tests, in denen jeweils mit Wahrscheinlichkeit R ein Ereignis erscheint EIN... Wenn die Gesamtzahl der Tests n gegeben, dann die Anzahl der Tests Ja in dem die Veranstaltung aufgetreten ist EIN, hat eine Binomialverteilung. Für die Binomialverteilung die Wahrscheinlichkeit, von einer Zufallsvariablen akzeptiert zu werden Ja Bedeutung ja ist definiert durch die Formel Anzahl der Kombinationen von n Elemente von ja aus der Kombinatorik bekannt. Für alle ja, außer 0, 1, 2, ..., n, wir haben P(Ja=
ja)=
0. Binomialverteilung für einen festen Stichprobenumfang n durch Parameter eingestellt P, d.h. Binomialverteilungen bilden eine Einparameterfamilie. Sie werden bei der Analyse von Stichprobenforschungsdaten verwendet, insbesondere bei der Untersuchung von Verbraucherpräferenzen, der selektiven Kontrolle der Produktqualität nach einstufigen Kontrollplänen, beim Testen von Personenpopulationen in den Bereichen Demographie, Soziologie, Medizin, Biologie usw. Wenn Ja 1
und Ja 2
- unabhängige binomiale Zufallsvariablen mit gleichem Parameter P 0
bestimmt durch Proben mit Volumina n 1
und n 2
dementsprechend dann Ja 1
+ Ja 2
ist eine binomiale Zufallsvariable mit Verteilung (19) mit R = P 0
und n
= n 1
+ n 2
... Diese Bemerkung erweitert den Anwendungsbereich der Binomialverteilung, sodass Sie die Ergebnisse mehrerer Versuchsgruppen kombinieren können, wenn Grund zu der Annahme besteht, dass alle diese Gruppen dem gleichen Parameter entsprechen. Die Eigenschaften der Binomialverteilung wurden früher berechnet: m(Ja) =
np,
D(Ja) =
np( 1-
P).
Im Abschnitt "Ereignisse und Wahrscheinlichkeiten" für eine binomiale Zufallsvariable wird das Gesetz der großen Zahlen bewiesen: für jeden . Mit dem zentralen Grenzwertsatz lässt sich das Gesetz der großen Zahlen verfeinern, indem man angibt, wie viel Ja/
n unterscheidet sich von R. Satz von Moivre-Laplace. Für beliebige Zahlen a und
B, ein<
B, wir haben wo F(x) ist eine Smit Mittelwert 0 und Varianz 1. Zum Beweis genügt die Darstellung Ja als Summe unabhängiger Zufallsvariablen entsprechend den Ergebnissen einzelner Tests, Formeln für m(Ja)
und D(Ja)
und der zentrale Grenzwertsatz. Dieser Satz für den Fall R= ½ wurde 1730 von dem englischen Mathematiker A. Moivre (1667-1754) bewiesen. In der obigen Formulierung wurde es 1810 von dem französischen Mathematiker Pierre Simon Laplace (1749 - 1827) bewiesen. Die hypergeometrische Verteilung erfolgt während der selektiven Steuerung einer endlichen Menge von Objekten des Volumens N nach einem alternativen Kriterium. Jedes kontrollierte Objekt wird entweder als mit dem Attribut EIN, oder als nicht im Besitz dieser Funktion. Die hypergeometrische Verteilung hat eine Zufallsvariable Ja gleich der Anzahl der Objekte mit dem Merkmal EIN in einer zufälligen Volumenstichprobe n, wo n<
n... Zum Beispiel die Zahl Ja defekte Artikel in einer Stichprobe von Mengen n ab Chargenvolumen n hat eine hypergeometrische Verteilung, wenn n<
n.
Ein weiteres Beispiel ist die Lotterie. Lass das Zeichen EIN ein Ticket ist ein Zeichen dafür, dass man "gewinnt". Lass alle Tickets n,
und einige Gesichter erworben n von ihnen. Dann hat die Anzahl der Gewinnscheine dieser Person eine hypergeometrische Verteilung. Für die hypergeometrische Verteilung hat die Wahrscheinlichkeit, dass eine Zufallsvariable Y den Wert y annimmt, die Form wo D- die Anzahl der Objekte mit dem Merkmal EIN, im betrachteten Volumen n... Dabei ja nimmt Werte von max (0, n - (n -
D)) bis min ( n,
D), mit anderen ja die Wahrscheinlichkeit in Formel (20) ist 0. Somit wird die hypergeometrische Verteilung durch drei Parameter bestimmt - das Volumen der allgemeinen Bevölkerung n,
Anzahl der Objekte D darin, das betrachtete Merkmal besitzt EIN, und die Stichprobengröße n.
Einfache Zufallsstichprobe des Volumens n aus dem Gesamtvolumen n heißt Stichprobe, die als Ergebnis einer Zufallsauswahl gewonnen wurde, in der eine der Mengen aus n Objekte haben die gleiche Wahrscheinlichkeit, ausgewählt zu werden. Die Methoden der zufälligen Auswahl von Stichproben von Befragten (Befragten) oder Einheiten von Stückprodukten werden in den instruktionsmethodischen und regulatorisch-technischen Dokumenten berücksichtigt. Eine der Auswahlmethoden ist wie folgt: Objekte wählen eines aus dem anderen aus, und bei jedem Schritt hat jedes der verbleibenden Objekte in der Menge die gleichen Chancen, ausgewählt zu werden. In der Literatur werden für den betrachteten Stichprobentyp auch die Begriffe „Stichprobe“ und „Stichprobe ohne Rücklauf“ verwendet. Da die Volumina der allgemeinen Bevölkerung (Charge) n und Probenahme n normalerweise bekannt sind, dann ist der Parameter der zu schätzenden hypergeometrischen Verteilung D... In statistischen Methoden des Produktqualitätsmanagements D- in der Regel die Anzahl der defekten Artikel im Los. Interessant ist auch die Charakteristik der Verteilung D/
n- der Grad der Mangelhaftigkeit. Für hypergeometrische Verteilung Der letzte Faktor im Ausdruck für die Varianz liegt nahe 1 wenn n>10
n... Wenn Sie gleichzeitig einen Ersatz machen P =
D/
n,
dann werden die Ausdrücke für die mathematische Erwartung und Varianz der hypergeometrischen Verteilung zu Ausdrücken für die mathematische Erwartung und Varianz der Binomialverteilung. Dies ist kein Zufall. Es kann gezeigt werden, dass beim n>10
n,
wo P =
D/
n.
Es gilt die Grenzbeziehung und diese begrenzende Beziehung kann verwendet werden für n>10
n.
Die dritte weit verbreitete diskrete Verteilung ist die Poisson-Verteilung. Eine Zufallsvariable Y hat eine Poisson-Verteilung, wenn wobei λ der Parameter der Poisson-Verteilung ist und P(Ja=
ja)=
0 für alle anderen ja(für y = 0 wird es mit 0 bezeichnet! = 1). Für die Poisson-Verteilung m(Ja)
= λ, D(Ja)
= λ. Diese Verteilung ist nach dem französischen Mathematiker S.D. Poisson (1781-1840) benannt, der sie erstmals 1837 erhielt. Die Poisson-Verteilung ist der Grenzfall der Binomialverteilung, wenn die Wahrscheinlichkeit R Die Durchführung der Veranstaltung ist gering, aber die Anzahl der Versuche n großartig und np= . Genauer gesagt gilt die Grenzbeziehung Daher wird die Poisson-Verteilung (in der alten Terminologie "Verteilungsgesetz") oft als "Gesetz seltener Ereignisse" bezeichnet. Die Poissonverteilung ergibt sich aus der Theorie der Ereignisströme (siehe oben). Es ist bewiesen, dass für die einfachste Strömung mit konstanter Intensität Λ die Anzahl der Ereignisse (Rufe) die während der Zeit aufgetreten sind T, hat eine Poisson-Verteilung mit Parameter λ = Λ T... Daher ist die Wahrscheinlichkeit, dass während der Zeit T kein Ereignis wird eintreten, gleich e -
Λ T, d.h. die Verteilungsfunktion der Länge des Intervalls zwischen Ereignissen ist exponentiell. Die Poisson-Verteilung wird verwendet, um die Ergebnisse von Marketing-Stichprobenbefragungen von Verbrauchern zu analysieren, die Betriebsmerkmale von Plänen zur statistischen Abnahmekontrolle bei kleinen Werten des Akzeptanzgrades der Fehlerhaftigkeit zu berechnen, die Anzahl der Unregelmäßigkeiten einer statistischen Beschreibung zu beschreiben kontrollierter technologischer Prozess pro Zeiteinheit, die Anzahl der pro Zeiteinheit im Warteschlangensystem empfangenen „Serviceanfragen“, statistische Muster von Unfällen und seltenen Krankheiten usw. Beschreibungen anderer parametrischer Familien diskreter Verteilungen und die Möglichkeit ihrer praktischen Anwendung werden in der Literatur berücksichtigt. In einigen Fällen, zum Beispiel bei der Untersuchung von Preisen, Produktionsmengen oder Gesamt-MTBF bei Zuverlässigkeitsproblemen, sind die Verteilungsfunktionen in einigen Intervallen konstant, in die die Werte der untersuchten Zufallsvariablen nicht fallen können. Beispiele für nach dem Normalgesetz verteilte Zufallsvariablen sind die Körpergröße einer Person, die Masse eines gefangenen Fisches einer Art. Normalverteilung bedeutet Folgendes
: Es gibt Werte der menschlichen Größe, der Masse der Fische einer Art, die intuitiv als "normal" wahrgenommen werden (aber tatsächlich - gemittelt), und sie werden in einer ziemlich großen Stichprobe viel häufiger gefunden als solche, die sich in unterscheiden eine größere oder kleinere Richtung. Die normale Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen (manchmal - die Gaußsche Verteilung) kann als glockenförmig bezeichnet werden, da die Dichtefunktion dieser Verteilung, symmetrisch zum Mittelwert, einem Glockenschnitt (rot Kurve in der Abbildung oben). Die Wahrscheinlichkeit, bestimmte Werte in der Stichprobe zu erreichen, entspricht der Fläche der Figur unter der Kurve, und bei einer Normalverteilung sehen wir dies unter der "Glocke", die den Werten entspricht tendenziell zum Mittelwert, ist die Fläche und damit die Wahrscheinlichkeit größer als unter den Rändern. Somit erhalten wir das Gleiche, was bereits gesagt wurde: Die Wahrscheinlichkeit, eine Person mit "normaler" Größe zu treffen, einen Fisch mit "normalem" Gewicht zu fangen, ist höher als bei Werten, die sich mehr oder weniger stark unterscheiden. In sehr vielen Fällen der Praxis werden Messfehler nach einem nahezu normalen Gesetz verteilt. Halten wir noch einmal bei der Abbildung am Anfang der Lektion an, die die Dichtefunktion der Normalverteilung zeigt. Der Graph dieser Funktion wurde durch Berechnung einer bestimmten Datenprobe im Softwarepaket erhalten STATISTIK... Darauf stellen die Spalten des Histogramms Intervalle von Stichprobenwerten dar, deren Verteilung nahe (oder, wie man in der Statistik sagt, unbedeutend abweicht) von der tatsächlichen Grafik der Dichtefunktion der Normalverteilung, die ein rotes ist Kurve. Die Grafik zeigt, dass diese Kurve tatsächlich glockenförmig ist. Die Normalverteilung ist in vielerlei Hinsicht wertvoll, da man nur die mathematische Erwartung einer kontinuierlichen Zufallsvariablen und die Standardabweichung kennt, um jede mit dieser Größe verbundene Wahrscheinlichkeit berechnen zu können. Die Normalverteilung hat auch den Vorteil, dass sie eine der am einfachsten zu verwendenden ist. Statistische Tests zum Testen statistischer Hypothesen - Student's t test- kann nur verwendet werden, wenn die Stichprobendaten dem Normalverteilungsgesetz entsprechen. Die Dichtefunktion der Normalverteilung einer stetigen Zufallsvariablen findet man nach der Formel: wo x- der Wert der Variablen, - der Mittelwert, - die Standardabweichung, e= 2,71828 ... ist die Basis des natürlichen Logarithmus, = 3,1416 ... Eigenschaften der Normalverteilungsdichtefunktion Mittelwertänderungen verschieben die Normalverteilungskurve in Richtung der Achse Ochse... Steigt sie an, wandert die Kurve nach rechts, sinkt sie dann nach links. Wenn sich die Standardabweichung ändert, ändert sich die Höhe des oberen Endes der Kurve. Wenn die Standardabweichung zunimmt, ist die Spitze der Kurve höher, und wenn die Standardabweichung abnimmt, ist sie niedriger. Bereits in diesem Abschnitt beginnen wir mit der Lösung praktischer Probleme, deren Bedeutung im Titel angegeben ist. Lassen Sie uns untersuchen, welche Möglichkeiten die Theorie zur Lösung von Problemen bietet. Das Ausgangskonzept für die Berechnung der Wahrscheinlichkeit, dass eine normalverteilte Zufallsvariable in ein gegebenes Intervall fällt, ist die kumulative Normalverteilungsfunktion. Kumulative Normalverteilungsfunktion: Es ist jedoch problematisch, Tabellen für jede mögliche Kombination von Mittelwert und Standardabweichung zu erhalten. Daher ist eine der einfachsten Methoden zur Berechnung der Wahrscheinlichkeit, dass eine normalverteilte Zufallsvariable in ein gegebenes Intervall fällt, die Verwendung von Wahrscheinlichkeitstabellen für die standardisierte Normalverteilung. Standardisiert oder normalisiert ist die Normalverteilung, deren Mittelwert ist, und die Standardabweichung. Dichtefunktion der standardisierten Normalverteilung: Kumulative Funktion der standardisierten Normalverteilung: Die folgende Abbildung zeigt die kumulative Funktion der standardisierten Normalverteilung, deren Graph durch Berechnung einer bestimmten Datenstichprobe im Softwarepaket erhalten wurde STATISTIK... Der Graph selbst ist eine rote Kurve, und die Beispielwerte nähern sich ihm. Um das Bild zu vergrößern, können Sie es mit der linken Maustaste anklicken. Standardisierung einer Zufallsvariablen bedeutet den Übergang von den ursprünglichen Einheiten der Aufgabe zu standardisierten Einheiten. Die Standardisierung erfolgt nach der Formel In der Praxis sind oft nicht alle möglichen Werte einer Zufallsvariablen bekannt, sodass Mittelwert und Standardabweichung nicht genau bestimmt werden können. Sie werden durch das arithmetische Mittel der Beobachtungen und die Standardabweichung ersetzt S... Die Größenordnung z drückt die Abweichung der Werte einer Zufallsvariablen vom arithmetischen Mittel bei der Messung von Standardabweichungen aus. Die Wahrscheinlichkeitstabelle für die standardisierte Normalverteilung, die in fast jedem Statistikbuch zu finden ist, enthält die Wahrscheinlichkeiten, dass eine Zufallsvariable eine standardisierte Normalverteilung hat Z nimmt einen Wert an, der kleiner als eine bestimmte Zahl ist z... Das heißt, es fällt in das offene Intervall von minus unendlich bis z... Zum Beispiel die Wahrscheinlichkeit, dass die Menge Z weniger als 1,5 ist gleich 0,93319. Beispiel 1. Das Unternehmen produziert Teile mit einer normalen Lebensdauer von 1000 Stunden und einer Standardabweichung von 200 Stunden. Berechnen Sie für ein zufällig ausgewähltes Teil die Wahrscheinlichkeit, dass seine Lebensdauer mindestens 900 Stunden beträgt. Lösung. Lassen Sie uns die erste Notation einführen: Suche nach Wahrscheinlichkeit. Die Werte der Zufallsvariablen liegen im offenen Intervall. Aber wir wissen, wie man die Wahrscheinlichkeit berechnet, dass eine Zufallsvariable einen Wert kleiner als ein gegebener Wert annimmt, und je nach Bedingung des Problems ist es erforderlich, einen Wert zu finden, der gleich oder größer als ein gegebener Wert ist. Dies ist der andere Teil des Raums unter der Dichtekurve der Glocke. Um die gewünschte Wahrscheinlichkeit zu finden, müssen Sie daher die erwähnte Wahrscheinlichkeit, dass die Zufallsvariable einen Wert kleiner als eine gegebene 900 annimmt, von eins abziehen: Nun muss die Zufallsvariable standardisiert werden. Wir führen weiterhin die Notation ein: z = (x ≤ 900)
; x= 900 - ein gegebener Wert einer Zufallsvariablen; μ
= 1000 - Durchschnittswert; σ
= 200 - Standardabweichung. Basierend auf diesen Daten sind die Bedingungen des Problems: Nach Tabellen der standardisierten Zufallsvariablen (Intervallgrenze) z= −0,5 entspricht einer Wahrscheinlichkeit von 0,30854. Ziehen Sie es von der Einheit ab und erhalten Sie, was in der Problemstellung erforderlich ist: Die Wahrscheinlichkeit, dass ein Teil mindestens 900 Stunden hält, beträgt also 69 %. Diese Wahrscheinlichkeit kann mit der MS Excel NORM.DIST-Funktion ermittelt werden (der Wert des Integralwerts ist 1): P(x≥900) = 1 - P(x≤900) = 1 - NORM.VERZ (900; 1000; 200; 1) = 1 - 0,3085 = 0,6915. Über Berechnungen in MS Excel - in einem der folgenden Absätze dieser Lektion. Beispiel 2. In manchen Städten stellt das durchschnittliche jährliche Familieneinkommen eine normalverteilte Zufallsvariable mit einem Durchschnittswert von 300.000 und einer Standardabweichung von 50.000 dar. Es ist bekannt, dass das Einkommen von 40% der Familien weniger als beträgt EIN... Finde den Wert EIN. Lösung. Bei diesem Problem sind 40% nichts anderes als die Wahrscheinlichkeit, dass eine Zufallsvariable einen Wert aus einem offenen Intervall nimmt, der kleiner als ein bestimmter Wert ist, der durch den Buchstaben angegeben ist EIN. Um die Größe zu finden EIN, bilden wir zunächst die Integralfunktion: Durch den Zustand des Problems μ
= 300000 - Durchschnittswert; σ
= 50.000 - Standardabweichung; x = EIN- der zu findende Wert. Gleichberechtigung komponieren Gemäß den statistischen Tabellen finden wir, dass die Wahrscheinlichkeit 0,40 dem Wert der Grenze des Intervalls entspricht z = −0,25
. Daher bilden wir die Gleichheit und finde seine Lösung: EIN = 287300
. Antwort: 40% der Familien haben weniger als 287.300 Einkommen. In vielen Problemen ist es erforderlich, die Wahrscheinlichkeit zu finden, dass eine normalverteilte Zufallsvariable einen Wert im Bereich von z 1 zu z 2. Das heißt, es fällt in das geschlossene Intervall. Um solche Probleme zu lösen, ist es notwendig, in der Tabelle die Wahrscheinlichkeiten zu finden, die den Grenzen des Intervalls entsprechen, und dann die Differenz zwischen diesen Wahrscheinlichkeiten zu finden. Dazu muss der kleinere Wert vom größeren abgezogen werden. Beispiele für Lösungen für diese häufigen Probleme sind wie folgt, und es wird vorgeschlagen, sie unabhängig voneinander zu lösen, und dann können Sie die richtigen Lösungen und Antworten sehen. Beispiel 3. Der Gewinn eines Unternehmens für einen bestimmten Zeitraum ist eine Zufallsvariable, die dem Normalverteilungsgesetz mit einem Durchschnittswert von 0,5 Mio. und eine Standardabweichung von 0,354. Bestimmen Sie mit einer Genauigkeit von zwei Dezimalstellen die Wahrscheinlichkeit, dass der Gewinn des Unternehmens zwischen 0,4 und 0,6 c.u. liegt. Beispiel 4. Die Länge des herzustellenden Teils ist eine nach dem Normalgesetz verteilte Zufallsvariable mit Parametern μ
= 10 und σ
= 0,071. Bestimmen Sie mit einer Genauigkeit von zwei Dezimalstellen die Wahrscheinlichkeit einer Heirat, wenn die zulässigen Abmessungen des Teils 10 ± 0,05 betragen sollten. Hinweis: Bei diesem Problem müssen Sie zusätzlich zur Ermittlung der Wahrscheinlichkeit, dass eine Zufallsvariable in ein geschlossenes Intervall fällt (die Wahrscheinlichkeit, ein nicht defektes Teil zu erhalten), eine weitere Aktion ausführen. ermöglicht es Ihnen, die Wahrscheinlichkeit zu bestimmen, dass der standardisierte Wert Z nicht weniger -z und nicht mehr + z, wo z- ein willkürlich gewählter Wert einer standardisierten Zufallsvariablen. Eine ungefähre Methode zur Überprüfung der Normalität der Verteilung von Stichprobenwerten basiert auf dem Folgenden Eigenschaft der Normalverteilung: Asymmetriekoeffizient β
1
und der Kurtosis-Koeffizient β
2
gleich null. Asymmetriekoeffizient β
1
charakterisiert numerisch die Symmetrie der empirischen Verteilung um den Mittelwert. Wenn der Schiefekoeffizient null ist, sind arithmetrischer Mittelwert, Median und Modus gleich: und die Verteilungsdichtekurve ist symmetrisch zum Mittelwert. Wenn der Schiefekoeffizient kleiner als Null ist (β
1
< 0
), dann ist das arithmetische Mittel kleiner als der Median, und der Median wiederum ist kleiner als der Modus () und die Kurve ist nach rechts verschoben (im Vergleich zur Normalverteilung). Wenn der Schiefekoeffizient größer als Null ist (β
1
> 0
), dann ist das arithmetische Mittel größer als der Median und der Median wiederum ist größer als der Modus () und die Kurve ist nach links verschoben (im Vergleich zur Normalverteilung). Kurtose-Koeffizient β
2
charakterisiert die Konzentration der empirischen Verteilung um das arithmetische Mittel in Richtung der Achse Oy und der Grad der Peakbildung der Verteilungsdichtekurve. Wenn der Kurtosis-Koeffizient größer als Null ist, ist die Kurve länger (im Vergleich zur Normalverteilung) entlang der Achse Oy(die Grafik ist spitzer). Wenn der Kurtosis-Koeffizient kleiner als Null ist, ist die Kurve abgeflacht (im Vergleich zur Normalverteilung) entlang der Achse Oy(die Grafik ist stumpfer). Der Schiefefaktor kann mit der MS Excel SKOS Funktion berechnet werden. Wenn Sie ein Datenfeld überprüfen, müssen Sie den Datenbereich in ein Feld "Zahl" eingeben. Der Kurtosis-Koeffizient kann mit der MS Excel EXCESS-Funktion berechnet werden. Bei der Überprüfung eines Datenfeldes reicht es auch aus, den Datenbereich in ein Feld "Nummer" einzutragen. Wie wir bereits wissen, sind die Schiefe- und Kurtosis-Koeffizienten bei einer Normalverteilung also gleich Null. Aber was wäre, wenn wir Schiefe-Koeffizienten von -0,14, 0,22, 0,43 und Kurtosis-Koeffizienten von 0,17, -0,31, 0,55 erhalten würden? Die Frage ist durchaus berechtigt, da wir es in der Praxis nur mit ungefähren, selektiven Werten von Asymmetrie und Kurtosis zu tun haben, die einer unvermeidlichen, unkontrollierbaren Streuung unterliegen. Daher ist es unmöglich, eine strikte Gleichheit dieser Koeffizienten mit Null zu verlangen, sie sollten nur ausreichend nahe bei Null liegen. Aber was bedeutet es - genug? Es ist erforderlich, die erhaltenen Erfahrungswerte mit den akzeptablen Werten zu vergleichen. Dazu müssen Sie die folgenden Ungleichungen überprüfen (vergleichen Sie die Werte der Koeffizienten im Modul mit den kritischen Werten - den Grenzen des Hypothesentestbereichs). Für den Asymmetriekoeffizienten β
1
.Verteilungsgesetz einer diskreten Zufallsvariablen

Sehr oft der Begriff Reihe
Verteilung aber in manchen Situationen klingt es mehrdeutig, und deshalb bleibe ich beim "Gesetz".

![]()
![]()
- somit beträgt die Wahrscheinlichkeit, konventionelle Einheiten zu gewinnen, 0,4.
- die Wahrscheinlichkeit, dass ein zufällig gezogenes Ticket verloren geht.![]()
Der mathematische Erwartungswert einer diskreten Zufallsvariablen
![]() bzw. Dann ist der mathematische Erwartungswert einer gegebenen Zufallsvariablen Summe der Produkte aller seiner Werte zu den entsprechenden Wahrscheinlichkeiten:
bzw. Dann ist der mathematische Erwartungswert einer gegebenen Zufallsvariablen Summe der Produkte aller seiner Werte zu den entsprechenden Wahrscheinlichkeiten:![]()

![]()
 (1)
(1)


![]()
![]() . (3)
. (3)![]() (4)
(4)![]() (6)
(6)![]() .
.
![]() ,
,![]() .
.![]() erleichtern Ihnen die Begründung von Methoden, die Formulierung von Theoremen und Berechnungsformeln.
erleichtern Ihnen die Begründung von Methoden, die Formulierung von Theoremen und Berechnungsformeln.![]()
![]()
![]()
![]() , nämlich,
, nämlich,![]()
![]()
![]()
![]() ,
,![]() .
.![]()

![]()
![]() Wenn also die Zufallsvariablen x 1
,
x 2
,…,
X nein n(m, )
, dann ihr arithmetisches Mittel
Wenn also die Zufallsvariablen x 1
,
x 2
,…,
X nein n(m, )
, dann ihr arithmetisches Mittel![]()
![]()

 (10)
(10)![]() (11)
(11) (13)
(13) (14)
(14) (16)
(16) (17)
(17)![]()

 (18)
(18)![]()
![]()
![]()
![]()
![]()

 (20)
(20)
![]() ,
,Vorherige
 ,
,![]()
Wahrscheinlichkeit, in einem bestimmten Intervall einen Wert einer normalverteilten Zufallsvariablen zu erreichen
 .
.![]() .
.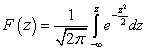 .
.
Offenes Intervall
![]() .
.![]()
![]() .
.![]()
Geschlossenes Intervall
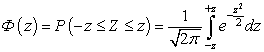
Eine ungefähre Methode zur Überprüfung der Normalität einer Verteilung